プライマリストレージサーバの置き換え
前編でプライマリを復旧したあと、しばらくそのままの環境で使っていましたが、その後バックアップサーバのST2000DL003が死にました。半年以内に3台のDM001と1台のDL003が連鎖的に死亡していくのをみて、さすがに怖くなってプライマリストレージサーバのHDDを全て交換することにしました。(ちなみに死亡したHDDに限って購入時のレシートが見つからないという)
グロ画像ことプライマリとバックアップサーバから引き抜いたDL003君とDM001君です

ストレージサーバの置き換えには、遊んでいたX8DTLにXeon L5630とメモリを適当に積み、ディスクには東芝製MD04ACA200を使う事とにしました。
惨事その3 RAIDアレイが突然死
X8DTLにはオンボードで LSI 1068Eから生える8ポートのJBODで見えるSATA/SASポートがあり、このポートを利用してmdraidでraid5のSRPデータストアを作成し、AHCIの方から生えているSATAポートを/などのOS用に割り当てることにしました。
当初はこれで問題なく動いていたのですが、構築から2週間後にZabbixから
kernel: mptbase: ioc0: WARNING - IOC is in FAULT state!!!
という見たくない感じのエラーが飛び、その後mdからディスクが1本もげました。
何故構築してから全く時間が経っていないのにディスクが故障?と思いましたが、とりあえず予備のMD04ACA200と交換することにしました。が、再構築中にmdがUU__U___になり死にました。その死に方も、一旦その状態になるとsmartctrl -x /dev/sdaなど、1068Eに繋がっている他のディスクに対して行うとエラーを返す、fdiskでも見えなくなるという状態でした。
この文章を書き起こしていても思い出したくないくらいのトラウマなのですが、全てのディスクをsmartやWindowsからHDTuneで読み書きテストをしてみても、特に問題は見つかりませんでした。仕方がないので、再度RAIDの初期化を行い、再度バックアップからの戻しを行いました。
しかし、また1ヶ月後に例のエラーが出て、ディスクアレイが死にました。
惨事その4 RAID HBAが突然死
おそらく、この状態になっていると言う事は、オンボードのLSIのチップが死んでいる?という可能性があったので、オンボードの1068Eを利用しないでLSI 2008チップを載せたD2607を追加し、JBODで見る設定にしました。何故このHBAかというと、手元にありかつ速度がそれなりに速くて接続されたディスクをJBODで見せられるというのが魅力だと感じたからでした。
が、こいつも1ヶ月後にmdが全崩壊を起こしました。
惨事その5 解決したと思わせてからのHBAの突然死
この辺でトラブルについてはほんともうお腹いっぱいだったのですが、この不定期に起きる悪夢の根本原因を探すことにしました。
しかし、何から調べたものか…と、困っていると、ディスクのsmartを取ろうとすると、smartを取得してからその情報を返すまで、非常にディスクのIOが遅くなっていることに気がつきました。
これを手がかりに、検証機でテストしてみると、何もないときはddで内容を読んでいても全く問題がないのですが、smartctrlを動かしながらddをすると、あるタイミングでsmartが刺さり、smartの内容を全く返さなくなり^Cでも中断できなくなり、かつIOがゼロになると言う問題が起きました。
何もせずにdd if=/dev/sda (D2607に繋がってるMD04ACA200) of=/dev/nullを行っているときの状態です。Readが193MB/s出ているので普通です。
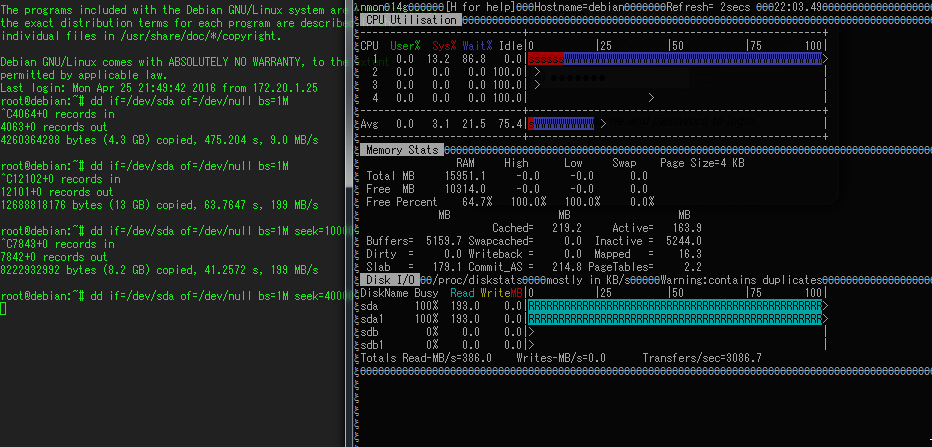
その状態で、新しくSSHのセッションを張り、
while :; do smartctrl -x /dev/sda >/dev/null ;date; sleep 1 ; done
をした結果です。
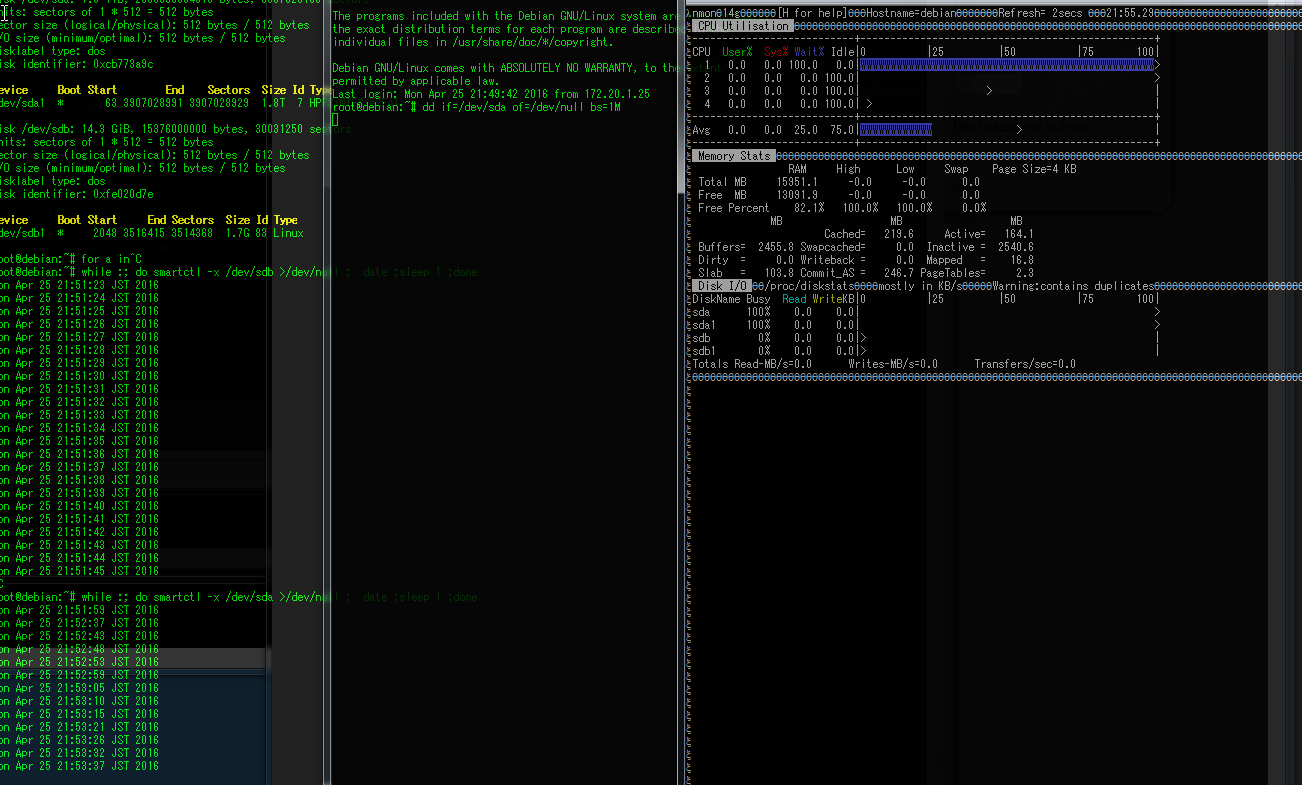
ddは続いているのですが、IOが0になり、かつDisk busyが100になり、CPUを1つI/O WAITで潰しています。
この内容で調べてみると、ぴったりではないのですが、D2607のファームウェア情報に、SMARTの情報異常を感知してコピーバックをする(予備ディスクに内容をコピーして異常時に備える)時にHBAが死ぬという情報があったので、とりあえずファームを新しくしてみました。
その結果、smartctrlをかけながらddをしても、smartを返す時にはIOは遅くなるものの、完全に刺さることはなくなりました。
また、Debianでsmartmontoolsを入れるとデフォルトで定期的にsmartdが各ディスクにSMARTクエリを飛ばすので、systemctl disable smartdを行い、ドライバもLSIから落としたものをビルドし、smart関連で刺さらないことを祈りました。ディスクへの情報取得で何かが起きていることはおそらく間違いないので、さすがにこれで解決したと思いました。いや、思いたかったのですが…
再びHBAが死にました。
再現性の調査
もしかしたらこの悪夢はLSI 2008チップと東芝のディスクの相性が原因で、他のLSI 2008チップを使っているHBAでも同じように起きるのでは?と思いいくつか試してみました。

検証環境で試した結果、以下の結果が分かりました。
・D2607だけではなく、HP OEMの LSI SAS 9212-4i(同じLSI2008チップを使うデフォルトでITモードで動くHBA)でもOSから複数のディスクでRAIDを組むと、バースト的な高負荷書き込みが連続すると不定期に死ぬ
・D2607はJBODを有効にせず、それぞれのディスクで1本のRAID0を作る(過去に8708EM2等で使われていた方法)を使うと検証期間中には問題が起きなかった(SMARTの取得は出来なくなりますが)
・MD04だけではなく、MD03、DT01、日立のHUA723でもSMARTの問題は起きる(これらのディスクは返す内容が大体同じ)
・SeagateのDM001、DL003、WDのCaviarGreen等ではSMARTの問題は起きない(日立系ディスクに比べて非常に簡素な内容しか返さない)
・LSI 2108を載せたボードでは、JBODは出来ないがHBA上でRAIDを組む分には問題なさそう(短期間しか試してないので怪しい)
以上のことから、LSI のチップでEnable JBODを有効にしてJBODでディスクをみていたり、ITモードで動くHBAと日立系のディスクは問題があるのかもしれないという結論に達しました。
ディスク全交換 そしてトラブルは静まる
上述のテストをしてる間に、秋葉原のBUYMOREでMG03ACAがバルクで入荷し、非常に安かったので一つ買ってみたところ問題が起きなさそうだったので、結局ディスクを全てMG03ACA300に交換してしまいました。MG03はSMARTでSAS系の情報を返すNL-SAS製品で、MD/DTシリーズとは動きが違うようでした(噂ではMGシリーズは富士通の流れをくむディスクで、それ以外は日立の流れをくむらしい。富士通のSASディスクでSMARTを見たことないので確証はありませんが、近いとは思います)。もうこのトラブルとおさらばできるのなら多少の出費は厭わない、という感じです。
このディスクに交換したところ、D2607でJBODで見ていても過去のトラブルが嘘のような平凡な日々が訪れました。少なくとも、今のところは…。
まとめ
今回の問題を回避するには、少なくともLinux上では
・LSIのチップに日立系のディスクを混ぜないこと
・LSIのチップで日立系のディスクを使うのなら、HBA自体のRAIDを利用すること(少なくともJBODで見るよりはトラブらない)
・日立系ディスクをJBODで見たいなら、オンボードのAHCI/SCUを使う事(smart取得時の速度低下は起きるが死ぬ事はなかった)
・2012年頃のSeagateのディスクはやばい(DM01が3/8で36%の故障率、DL003が1/6で16%の故障率)
と言うのが今のところの結論です。日立系のディスクと言っても、ニアラインSASや10kRPMのSASドライブではまた違うと思いますが、少なくともデスクトップ向けのディスクとLSIのチップは避けるべきのようです。
また、DM001の故障率は有名なBACKBLAZEでもST3000DM001が導入からちょうど2-3年で20-40%の割合で故障しているので、奇しくもこのデータと近い値が出てしまいました。このヤバいディスクがINしてるシステムでまだ問題が起きていないのであれば、早急に交換をおすすめします。(大半のディスクはもう死んでこの世にいないかもしれませんが)
1台2台がばらばらの時期に壊れてくれるのであれば良いのですが(良くはない)、まさか連続死を起こされるとは…。まあ、それを見越した設計でも最後の砦を壊したのはこの手でしたが。
この一件で、バックアップの重要性を身をもって実感することになり、いくつかのデータは仮想マシンではなく物理マシンにrsyncするようになりました。そしてディスクが安く売ってると買ってバックアップサーバを作らなくてはと言う強迫観念に駆られるという傷跡を残しました。
せめてもの救いは、オペミスしたのが自分の環境だったことで、仕事でやらなくて良かったという点です。個人的には仕事のデータなんかよりこちらの方がよほど大事ですが…。
かなり長い間悩んだ内容だったので記事自体も長くなってしまいましたが、誰かの役に立つことを願い一応まとめてみました。ストレージ関係の悪夢はほんとつらいので誰も見ないに越したことはないのですが。
ツイート
コメントを書く
必要事項とコメントを入力して下さい。