セットアップ
テスト環境はこんな感じです。

ストレージサーバ RX300S7
CPU Xeon E5 2643*1
Mem 8GB*8 at DDR3 1600MHz
Drive SanDisk Optimus Ascend 800GB *10 /RAID5 for Data (PN:LN0800FEHDC)
RAID HBA D3116C (MegaRAID SAS 2208@PCI-E 3.0)
IB HCA MT26428 (Connect-X2 VPI Single Port QDR) *2@PCI-E 2.0
Target SCST Version 3.4.0 from git repo
LIOでもSRPターゲットを作れますが、負荷が1つのコアに集中する、たまに刺さる、認証なしのターゲットが作れないといったことを経験したのでSCSTを使っています。SCSTは非常に安定していて、3-4年位使っていますが問題ありません。ストレージ側の設定はこんな感じです。
# cat /etc/scst.conf
HANDLER vdisk_fileio {
DEVICE dev-srp0 {
filename /vdisk/srp0.img
}
}
TARGET_DRIVER copy_manager {
TARGET copy_manager_tgt {
LUN 0 dev-srp0
}
}
TARGET_DRIVER ib_srpt {
enabled 1
TARGET fe80:0000:0000:0000:0002:c903:000f:41a7 {
enabled 1
rel_tgt_id 1
LUN 0 dev-srp0
}
TARGET fe80:0000:0000:0000:0002:c903:000f:8395 {
enabled 1
rel_tgt_id 2
LUN 0 dev-srp0
}
}
仮想ホストの環境は以下です。SRPを使う手順はこちらを参考にしてください。
DL380p gen8 ESXi 6.5

CPU Xeon E5 2667v2 *2
Mem 16GB*16 at 1333MHz
IB HCA MT26428*2 (Connect-X2 VPI Single Port QDR)
仮想マシン
Windows 10 x64 Pro 1809
vCPU 4
Mem 6GB
ベンチマーク用のディスクには準仮想化SCSIコントローラーを使
この状態で、ディスクへのパスを切り替えてテストします。 テストには最初 IO Meterを使おうと思ったのですが、パラメーターによって大きく値が変わってしまうので再現性のあるCrystalDiskMark6.0を使用しました。
ストレージ接続*1本
まずは、1ポート接続でテストします。
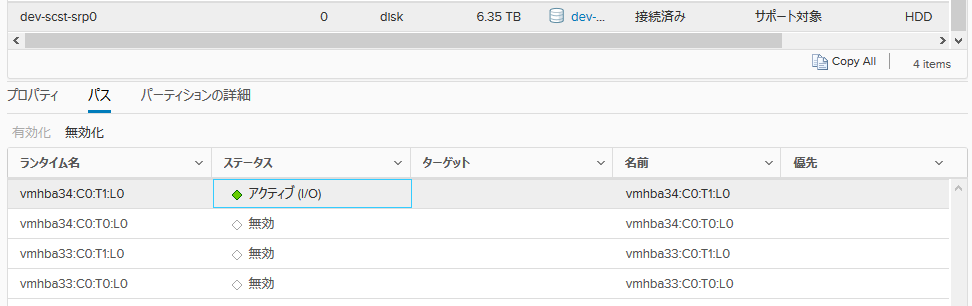
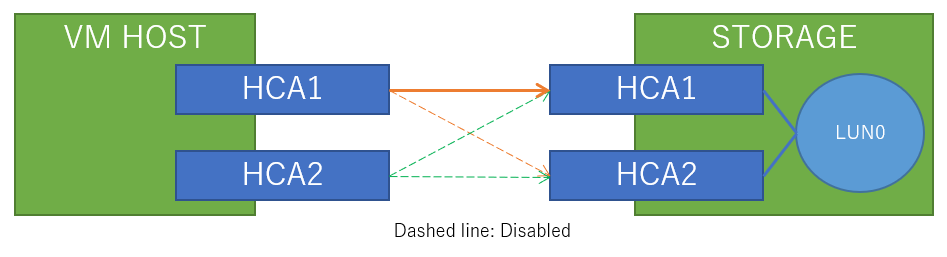
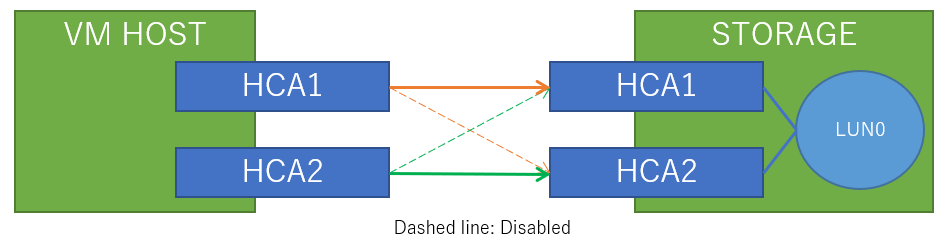
接続図はこんな感じです(途中のIBスイッチは省略)
その結果が以下です。
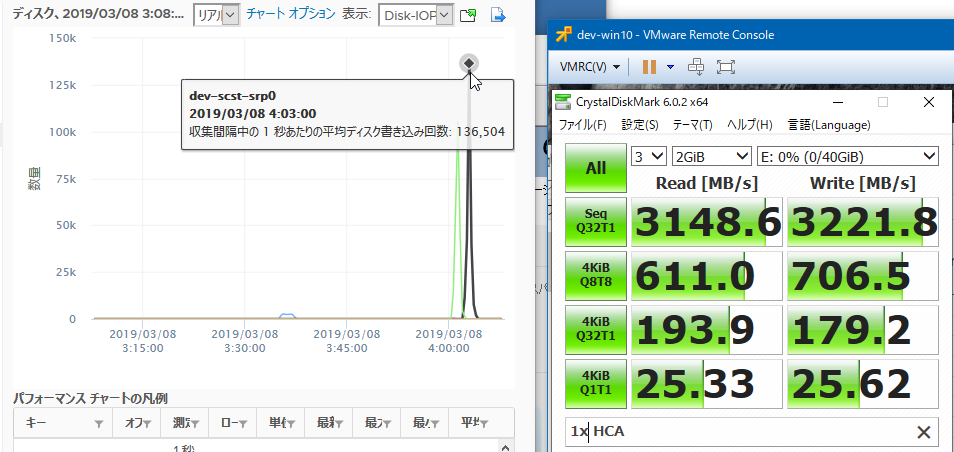
読み、書きともに120-130kIOPSで、帯域は3148MB/sでした。
ストレージ接続*2本
次に、接続を増やしてテストします。ラウンドロビンの切り替えは1IOごとに行う設定にします。
esxcli storage nmp satp rule add -R gsan -s VMW_SATP_DEFAULT_AA -P VMW_PSP_RR -O iops=1
設定ははこうなります。
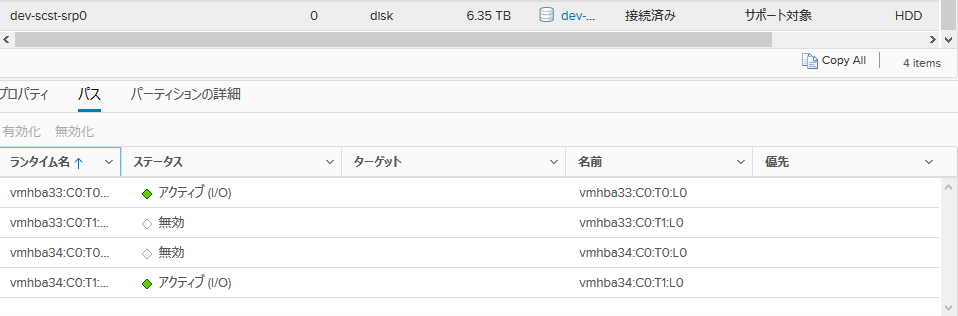
接続図はこんな感じです(途中のIBスイッチは省略)
その結果です。
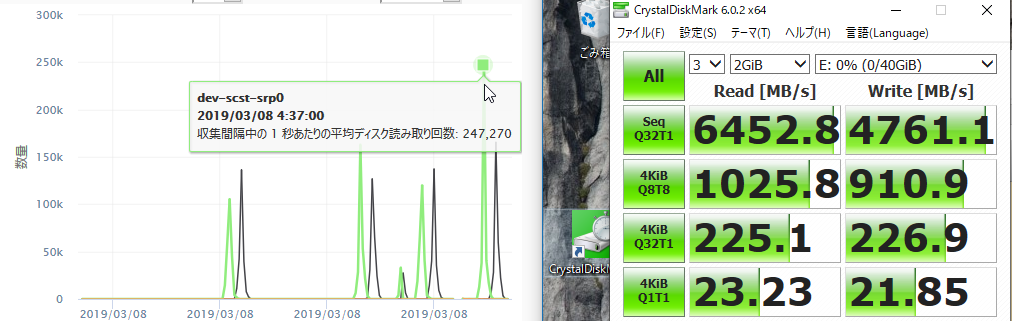
読み込み250kIOPS、書き込み150kIOPS出ました。また、帯域は読み込みに関してはきれいに2倍にスケールしました。いくらほぼストレージサーバのRAMへの読み書きとはいえ、びっくりするほど速いです。こんな速かったのか…。
また、読み込み250kIOPS時のストレージサーバの負荷はこんな感じでした。
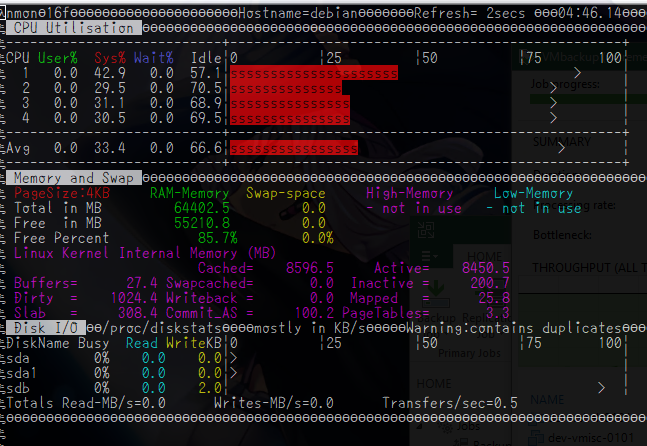
何かのエージェントで監視しているわけではなくnmonで見ていましたが、これより大きく外れることはありませんでした。
まとめ
SRPはもはや旧世代なハードウェア、かつ4コアという、今となっては非力な環境でもかなりの性能を発揮できました。もちろん、搭載しているRAMがちょっと多いのでDirtyやキャッシュの助けもありますが、nvmeのような高速なストレージを使ってもSRPはネックにならないというのはかなり強いです。
とはいえ、これを目当てに今からInfinibandを入れるのは、サポートの切れたConnect-X2からCX3世代をサポートの切れたドライバで動かすという、あまりにも将来性がない構成になるのでおすすめしません。
iSERは試したことがありませんが、原理としては同じなので今からやるならせめて40GbEのiSERでしょうか。100GのiSER環境も試してみたいのでどこかにスイッチとNICが転がってないかなと思う日々です。
早くこれよりも超高速なストレージを見つけて将来性のあるモダンな構成に移行したい…
[ コメントを書く ] ( 774 回表示 ) | このエントリーのURL |
家で仮想化基盤を扱っていると、どうしてもネックになりがちなのがストレージです。特にWindows環境での検証やVDIのテストをしていると、どうしてもIOが多いのでストレージがネックになり、あまりに遅いと作業のやる気が失せてしまいます。
このIOが遅いというのが嫌で仕方がないので、家で使えるレベルでの最速のストレージを求めて今までいろいろなことを試してきましたが、そのあれこれを雑然と書きたくなったので書いてみます。あくまでも家で使うレベルの話であり、業務でやるなら各ベンダから出ているオールフラッシュストレージをサポート付きで購入してください。
階層化ストレージ
今でこそSSDは容量も増え価格も下がりましたが、2017年位までは500GB以上のSSDとなるとなかなかの価格でした。そのため、それまではHDDのみの構成でしたが、128GB-256GBが手頃になり始めた2016年位に階層化ストレージとしEnhance-IOを入れてみました。ただ、メインストレージには日々(使用領域をほぼ舐める)バックアップが入ってしまうため、サイズの小さいキャッシュだとHOTなデータが流れてしまう事が多く、ヒットレシオは30%くらいでした。

その後、ES3000v2というエンタープライズなPCI-E SSDが数枚手に入ったのでこれを VMware上の仮想マシンクローニングを高速化するためにライトバックキャッシュにしたかったのですが、ライトバックキャッシュとして使おうとするとhioドライバ (Fusion IOのドライバ名を真似している)の上がってくるタイミングとudevがenhance-ioのキャッシュセットを組み立てるタイミング、fstabをもとにOSがディスクをマウントするタイミングなどが合わず、ライトバックキャッシュとして使うとファイルシステムが壊れるという事態が起きました。

また、常にFPGAを全力で動かすことによりレイテンシを削減しているため、省電力機能といったものがなくカード自体が非常に発熱します。拡張カード周辺はかなり強い風量で空気を循環させないと、複数枚刺したときにOver Temperatureのログ出力とサーマルスロットリングを受ける状態でした。室温が常に18度というような環境であればいいのかもしれませんが、人が生きる環境だと春以降温度が上がるため厳しいです。
確かに性能はnvmeがなかった当時としてはかなり高かったかもしれませんが、発熱量とドライバと消費電力量的にちょっと使いにくいのでどうにかしたい思いが強くなりました…。ドライバについては、Debianでも問題なくソースからドライバをコンパイルすることによって動きましたが…。

そしてちょっと前に、3.2TBのSSDが数本手に入ったので50TBのディスクの前段キャッシュにしようとしたのですが、ここであることにハマりました。キャッシュのメタデータ保持に4Kページ使用時でSSDの容量の0.1%程度のサイズのメモリを消費するのですが、RAID5などでまとめた実効9TBのSSDとなると、メタデータのために9GBのRAMが必要になります。RAM自体の空きはあったはずなのですが、メタデータが巨大になると、それをメモリ上に展開するのに非常に時間がかかるようになり、起動時のキャッシュの組み上げ時にランダムにカーネルが刺さってpoweroffもできなくなることがありました(つまり電ぷち)。
検証の結果、WBで使う場合にはキャッシュサイズが大体2TBを超えてくるとfstabではなく自分のスクリプトでマウント(及び付随するサービスの起動)をどうにかする必要が出てきて、またSRPのようなブロックデバイスアクセスだとそもそも思ったようなキャッシュの動きをしてくれなかったので、最終的に諦めました。NFSだったらまたキャッシュのヒットも違ったのかもしれませんが、あまり大きすぎるサイズのキャッシュが来ることを想定していないようでした。もっと前に検証で気がつけた部分もあるのですが、いざそのときにならないとわからない部分もあるのです…。
bcacheも試したのですが、こちらは思ったほどいい動きをしませんでした。
結局
SSDだけでも結構な容量なので、検証に使うSSDなLUNと、データ保存に使うHDDのLUNを分けることにしました。HDDのLUNでもストレージサーバ側のメモリキャッシュが効くので、データがホットな分にはHDDでも十分なのですが、VMのクローニング時には読みと書き込みが1つのLUNに同時に走るので、接続が全二重なSAS-HDD(NL-SASですが)といえどバックの性能差が顕著に出ます。
SSDはベンチマーク的に良かったSmartArray P420にキャッシュとキャパシタをつみHW-RAIDにしました。P420もHPE以外のマシンで使おうとするといろいろ苦労がありましたが…。経験的にエンタープライズクラスのSSD(IntelのDC3610とかMicronのM5000DCとか)は壊れたことがないので、おそらくフラッシュメモリ部分の劣化が来ることはないと思うのですが、過去にコンシューマSSDでコントローラー側の故障と思われる原因でSSDが見えなくなったことが何度かあるのでRAID5を選択しました。ただ、パリティでSSDの3TBが持っていかれるというのがなかなか気分としてつらいです。RAID0でも良かったのではと思わなくもないですが…。
ストレージマシンにメモリマシマシ
これは手っ取り早く効果が出ます。特にメモリがある程度大きいマシンで、ストレージ以外に仕事をさせない前提なら/etc/sysctl.confで
vm.dirty_background_ratio = 35
vm.dirty_ratio = 90
とメモリの90%位を書き込みバッファにしてしまうとわかりやすく速くなります。ストレージサーバだけで128GB位メモリを持っているとほぼオンメモリで動く上に、VM上でごちゃごちゃ書き込んだとしても最終的にXFSの遅延書き込みによりシーケンシャルになるので、SSDにも優しいです。多分。当然、突然のシャットダウン時にデータを損失する可能性はありますが、全損してもデータ自体は違う筐体から最短1日前に戻せるのでそれは許容しようかと思いました。崩れても誰にも怒られないので、それよりは性能を重視したいです。(ただし何かあったときに誰の助けも受けられないので血を吐きながら泣いて復旧作業をしなければならない)
ストレージ接続
現状Infiniband+SRPを超えるものが見つかりません。非公式ながらESXi6.5でもSRPは動きますが、Mellanoxのディスコン扱いがひどいのでなにか別の手段を探そうとしているのですが、結局これを超えられません。助けて…
8GFCのIOPS性能に夢を見た時期もありましたが、FCターゲットをLinux上に作ろうとするとHBAをイニシエーターからターゲットモードに変更するという手間や、苦労して作った割に10G iSCSI/NFSのほうが総合的に性能が良かったりFCターゲットは負荷をかけると刺さったりしたので、FCターゲットはベンダから買うものであって作るものではないと実感しました。SCSTのFCターゲットは試していないのですが、もしかしたらこっちはLIO/targetcliの環境で起きたようなことはなかったかもしれません…が、もうスイッチ含めて手放してしまったので検証できません。
いくら10G-iSCSIでも、レイテンシやIOPS的にSRPのそれには追いつきません。SRPの代替としてはほぼ同じ原理のiSERがありますが、40G Etherを入れて初めてIBのSRPと渡り合えるレベルなので、それ以下の25GbEなどではせっかく環境を揃えても純粋なストレージインターコネクトとしてはデグレになってしまいます。
100G EtherのスイッチとNICが手に入ればいいのですが、HCAが3000円で買える上にRDMAできっちり40Gbpsが出るIBに比べると、いま時点のパフォーマンス観点からの選択肢としてはIBに歩があります。ただ、IB自体が特に仮想化ではディスコンの流れをたどっている部分があるので、あまりこれにベッタリするのもやめたいのですが…移住先がない…。
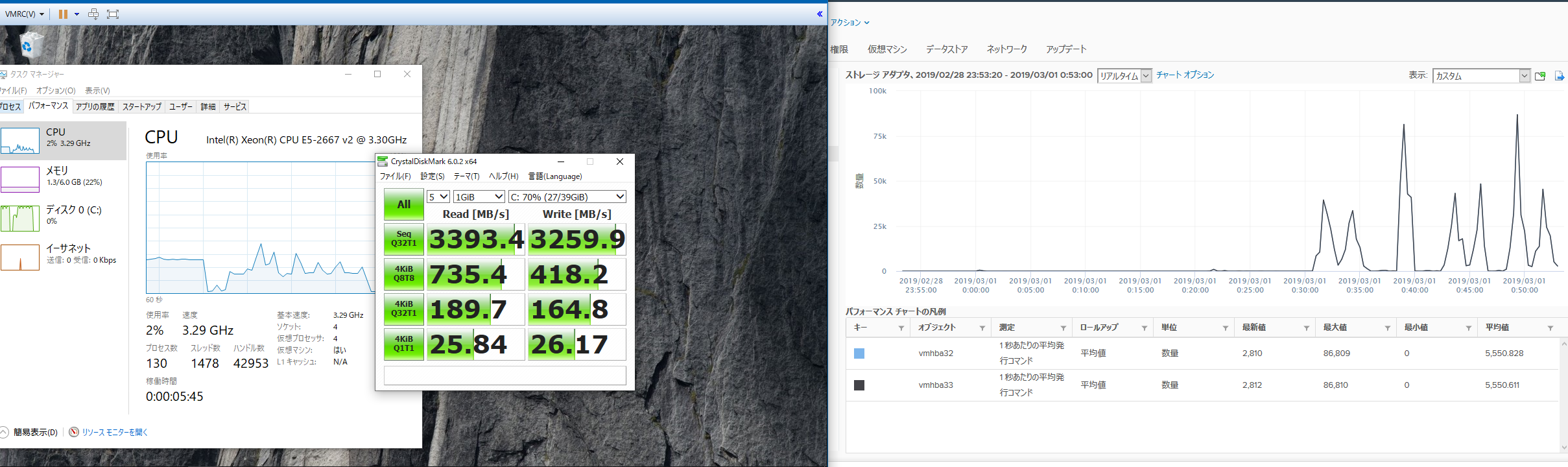
どの程度の性能かというと、1ホスト1LUNで160kIOPSの性能が出せ、帯域面では3.3GB/s程度出ます。ほぼストレージサーバーのメモリへの読み書き速度ですが、VMホストから見てもIOPSのカウンタは回っているためVM内のメモリ書き込みではなく、しっかりとHCA経由でIOがやり取りされています。
デュアルポート接続なのでもう少し帯域を出せないかと思いましたが、そもそもPCI-Eの2.0のx8が500MB*8レーン=4GB/sであり、IBの8b/10bエンコードを考えると4GBの80%なので3.3GB/sというのはほぼ理論値でした。1HCA/DP構成ではなく1ポートHCA*2の接続にするか、PCI-E 3.0対応のCX-3以降に置き換えればPCI-Eの帯域が倍になるのでもう少し出ると思うのですが、未検証です。複数HCAのIO分散は気になるのでいつか試してみたいです。
まとめ
・ストレージを強くしたいならbcacheやeioなどの階層化ストレージに夢を見ずにフルSSDやnvme構成にするのが一番シンプルで速い
・それ以上を求めるなら多少の耐障害性を落としてもメモリを許されるだけ乗せるしかない
・IB+SRPは間違いなく速いが、いろいろノウハウがいるうえに仮想化周りではIB自体が鎮火しているので今からIBに投資するのはやめたほうがいい
・NFS over RDMAとか今からIBで再流行しないかな…だめかな…
・vSANは…うん、それもまた人生だね!
今の流れとしては分散型のスケールアウトストレージ+賢いローカルキャッシュというものがイケてる構成ですが、主に電力事情で動かせるマシンが限られてくると1つのマシンをいかに強くできるかというスケールアップ型になってしまいます。
この構成だとストレージの冗長構成が取れず/取ろうとすると非常に厳しく、何かしらでストレージが不意にクラッシュすると即死ですが、これはこれで普段切り分けしやすいという点で使いやすい面もあります。
スケールアウト型を車で例えるとトルクベクタリングなど次世代の仕組みを組み込んだ車ですが、SRPなどはシンプルに基礎を抑えていて低回転域から高回転域まできっちりトルクの出る大排気量車のようなものです。それぞれにいい悪いはあるのですが、後者は時代の流れによりディスコンなのが悲しいです。
無限に電気を使えれば無限にマシンを増やしてスケールアウト型のストレージなどにも手を出したいのですが現実は厳しいです。
完全に趣味の話でした。おしまい。
[ コメントを書く ] ( 498 回表示 ) | このエントリーのURL |

最近はRAIDカードの検証などであれこれしていたのですが、その際にPCI-E 3.0でリンクでき、かつ自由に再起動できる遊んでいる資材が、自分の環境にはもらったGA-X79-UD-5とHPのML350pGen8しかありませんでした。
しかし、ML3530pはサーバにありがちな再起動に2分3分かかるのが苦痛なのと、物理的なアクセス(積んでいる場所)の制限によりカードの差し替えがつらいと言う問題があり、GA-X79-UD5に関しては10G+FCoEなCNAなカードや、ほぼ全てのRAIDカードなどのオプションROMを持った拡張カードを挿すとPOSTしなくなるという問題がありました。
なので、そろそろたたき台の板を更新しても良いかなと色々見ていたところ、謎のHUANAN X79というMBがオークションでXeon 2660v1とRegECCなDDR3メモリ4GBx4がついて2万円だったので、怖い物見たさと知的好奇心で買ってしまいました。そのメモを色々雑に書いておきます。
更新する先が2011v1と言うのも残念ですが、DDR3メモリやらなんやらが余っているのでDDR4に移行できないという…。
べつに宣伝をするわけではないので、気になった人は各々探してみてください。
余談ですが、最初HUMANと読みましたがHUANANなので検索するときは注意してください。
内容物
SATAケーブル、IOシールド、マニュアル、ドライバCD、Xeon 2660v1とRegECCなDDR3メモリ4GBx4、そして何故か親切にもCPUのサーマルグリスがついてきました。使いませんでしたが。
Xeon 2660v1はどうやら正規品らしいです。CPU-ZやSR0KKというSスペックを信じる限りは…。

メモリは、サーバでよく見るSamsungのDDR3 RDIMMでした。壊れていたら文句を言おうかと思ったのですが、Memtest86を2周してしまったので諦めます。
マニュアルはフロントパネル用ピンヘッダの配置と、OSへのドライバインストールなどをさらっと書いた程度の物(中国語)であり、Supermicroのような細かい接続ブロックダイアグラムは一切ありませんでした。
外見
リア端子は必要最低限、基板は割と堅い構成に見えます。

オンボードに謎のm-SATAコネクタがあるのですが、WifiなどのPCI-Eカードが刺さるのか、mSATAを使った場合オンボードのSATA3ポートのどちらかと排他になるのか、その後ろにあるジャンパピンは何なのか、どこにも何も書いてないので謎です。
起動できるCPUについて
XeonのES品・QS品、V1/V2何でもいけました。
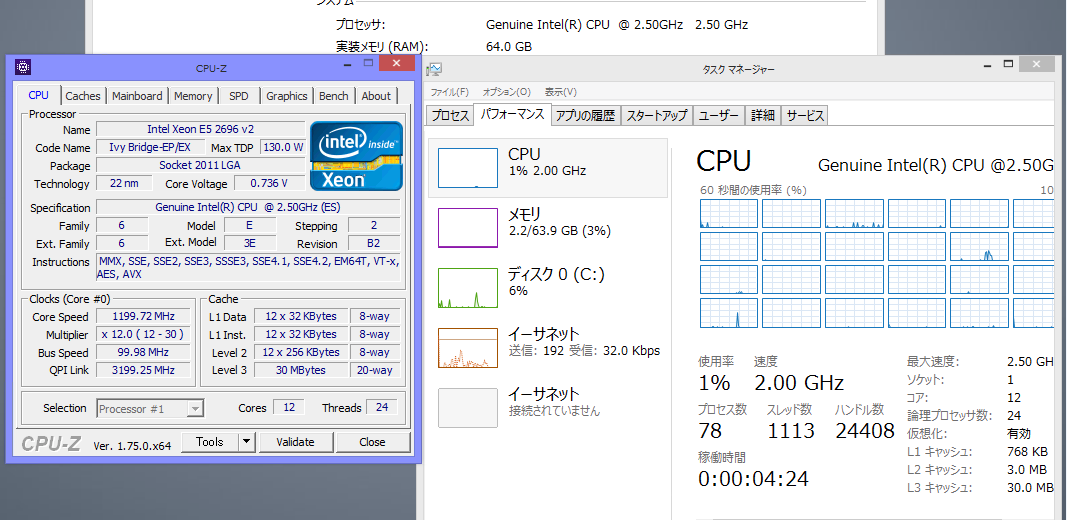
確認した限りの最大構成では、興味本位で買った12コアの2696v2のES品と、メモリも16GBのDDR3-1333Rx4の64GBまで確認しました。
X79で何故RDIMMがいけるのか謎で仕方がありませんが、CPU側にメモリコントローラを搭載しているからなのか、Welcome to ようこそ謎チャイニーズテクノロジーなのかはわかりません。
実はUD-5もv1のXeonに関してはES/製品版が起動できるのですが、RDIMMは認識できません。 このX79でもi7の3900/4900系を載せたら多分RDIMMは動かない気がしますが、未確認です。
その他
BIOSのリビジョンは4.6.5で、最終更新はこの記事を書いた時点で半年前の10月でした。
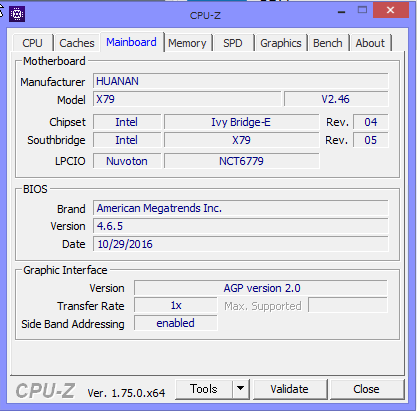
X79にしては息が長い気がしますが、公式製品ページが見つからないためBIOSのアップデートがどこから手に入るのかは謎です。
CPUのヒートシンクにはZalman FX70と言う物を利用しました。
まあじゃんぱらでたまたま安いのが見つかったのでこれにしたのですが、中々に芸術点が高い作りをしています。芸術的な作りが故に、持ち上げるときに左手小指と右手親指の2回指を切っているので、扱うときは気をつけましょう。
グラボはかれこれ長く使っている(500円で数枚買った)Matrox G550のPCI-E x1版を使って検証しました。どうせリモート(RDP/IP-KVM/SSH)で作業してしまうので起動画面さえ見えればいいと言う割り切りさえすれば、貴重なx8やx16レーンを使わずに普段余るx1にグラフィックを回せるので、この手のマザボ使用時の検証用途には安く手に入ればおすすめです。
ただしWDMなグラフィックドライバが出ていないのでWin8以降はドライバがあたりません。Win8以降は標準ドライバでそれなりに動きますが、間違えてメイン機で使おうとすると大変なことに…。
まとめ
謎なMBですが、オンボードデバイスが必要最低限になっているためか、カードとの相性もなく癖のない動きをしています。が、信頼できるかというと怪しいので、目の届く範囲外での使用は避けたい気もします。
しかし、良いか悪いかは別として、ES品が動いてしまい、かつ余ってる/割と安価に買えるRDIMMも使えると言う魅力もあるので、一概にダメとも言えないのが悩ましいところです。
なので、物好きな人が、知的好奇心を満たすために自己責任で試す分にはいいと思います。
以上です。
[ 2 コメント ] ( 2515 回表示 ) | このエントリーのURL |
社内で自宅に構成したNutanix CEのデモを行ったところ、好感触だったのでとりあえずシングルノードで構成して触ってもらうことにしました。 しかし、あいてるHWがリース切れでもらってきたML380G7だったため、ドハマりする結果になりました…。なんとか原因がわかったので後世のためにバッドノウハウを残します。
余談:導入のいきさつ
未だに後進的な開発方法を行っていたのでどうにかしたいと思ってはいたのですが、インフラに詳しい人がほぼいないうえ、自分もかかり切りになるわけにはいかない状況で(あと一々VM作成依頼とか受けたくない)、誰でも必要なときにVMを作れるNutanix CEは非常に良いソリューションでした。
ちなみに過去に開放するサーバのハイパーバイザを検討した結果:
VMware→vCenterServerがないのでクローンとか作るのが厳しいし、そのたびに一から作るのはあまりに効率が悪いので没 (出来なくはないけどSSHでログインしてvmkfstools 使えとかvmxファイルいじれとか非インフラの人にはもっと厳しい)
Linux KVM→同上 (そもそもアプリ開発チームにKVM使ったことある人いないのでは…)
HyperV→まあ妥当かなと思っていたけど社内にライセンスが2008R2Stdしかないのでメモリ32GB制限とRDP接続数制限…
もちろん、それぞれ良いところはあるのですが、どれもある程度のナレッジが必要なので、あまり深く考えずに使う、というのはちょっと厳しいかなと思いました。
なので、ちょっと暇が出来たので「とりあえず箱は用意したから好きに使っていいよ、ただし冗長性はないからいつ吹っ飛ぶか分からないから、必要なデータはgitデーモンなりSVNなりあとで本番仮想機の上に作るのでそっちに退避してね」というスタンスでNutanix CEを入れようとしたのですが…
構成
ハードウェア構成
筐体 HP Proliant ML380G7
ストレージコントローラ P410i (1G-FBWC付き)
ディスク構成 2.5インチSAS 300GB*8
CPU Xeon X5680*2
メモリ 48GB
OSバージョン
ce-2017.02.23-stable.img.gz
ディスクが8本あるのに全て300GBというNutanix CEのHDD500GB要件を満たさないため、「じゃあ全てRAID5でくっつけて一つにするか!」という安易な発想から、サポート外構成のディスク構成をとりました。ただ、SSDがないため、SSDだけは買ってもらい、HDDを一つ抜いてSSDに交換したので以下のようなディスク構成になりました。
Array A 300*7 RAID5 1.8TiB
Array B 240GB * 1 RAID0
USBにce-2017.02.23-stableを焼き、起動までは良かったのですが…
ハマり1 ディスクがSSDとして認識されない
みんなのハマりポイントなので情報は沢山ありました。SmartArrayはSSDとして認識するのですが、何故かOSにはそれを見せないようです。
echo 0 > /sys/block/【SSD】/queue/rotational
にてインストーラはごまかせました
ハマり2 CVM再起動後ストレージプールが死ぬ
CVM起動後、PrismからみるとArray Aも何故かSSDと認識され、おかしいなーと思いCVMを再起動したところ、ストレージプールへ一切の書き込みが出来なくなりました。
家に帰ってからも手持ちのP410コントローラを使い
Array A 1TB SATA HDD*2 RAID0
Array B 240GB SATA SSD * 1 RAID0
構成で同様のことを行ったのですが、やはり死にました。
余談ですがSmartArray P410がX79などのMBで起動しなかったため、メモリとコア数に余裕のある(Xeon L5640/6コア)懐かしのX58を引き出しました…。

原因
長時間の手探りの調査のあと、原因はSmartArrayで定義されたディスクが、ディスクのシリアルの代わりにコントローラのシリアルを返すことだと判明しました。
[root@NTNX-71f86937-A ~]# smartctl -a /dev/sda
=== START OF INFORMATION SECTION ===
Vendor: HP
Product: LOGICAL VOLUME
Revision: 6.64
User Capacity: 240,021,504,000 bytes [240 GB]
Logical block size: 512 bytes
Rotation Rate: 15000 rpm
Logical Unit id: 0x600508b1001cb8ae0693a3fdcc1e17ca
Serial number: PACCRID11320BPR <========これ
Device type: disk
Local Time is: Thu Mar 9 14:24:53 2017 PST
SMART support is: Unavailable - device lacks SMART capability.
=== START OF READ SMART DATA SECTION ===
Error Counter logging not supported
Device does not support Self Test logging
[root@NTNX-71f86937-A ~]# smartctl -a /dev/sdb
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-4.4.26-1.el7.nutanix.20170222.x86_64] (local build)
Copyright (C) 2002-13, Bruce Allen, Christian Franke,www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: HP
Product: LOGICAL VOLUME
Revision: 6.64
User Capacity: 2,000,342,441,984 bytes [2.00 TB]
Logical block size: 512 bytes
Rotation Rate: 15000 rpm
Logical Unit id: 0x600508b1001cec93d95097d47affa22f
Serial number: PACCRID11320BPR <========これ
Device type: disk
Local Time is: Thu Mar 9 14:24:56 2017 PST
SMART support is: Unavailable - device lacks SMART capability.
=== START OF READ SMART DATA SECTION ===
Error Counter logging not supported
Device does not support Self Test logging
[root@NTNX-71f86937-A ~]#hpacucli ctrl slot=1 show
Smart Array P410 in Slot 1
Bus Interface: PCI
Slot: 1
Serial Number: PACCRID11320BPR <========これ
…
このシリアルがCVMの初期設定時にxmlに書かれるのですが、このシリアルをCVMの中でマウントポイントとして使っているため、同じシリアルがあると二重マウントになりどちらかがアクセスできなくなります。
[root@NTNX-d16bad23-A ~]# virsh dumpxml NTNX-d16bad23-A-CVM
(省略)
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='native'/>
<source dev='/dev/disk/by-id/scsi-3600508b1001cec93d95097d47affa22f'/>
<backingStore/>
<target dev='sda' bus='scsi'/>
<serial>PACCRID11320BPR</serial> <========これ
<wwn>600508b1001cec93</wwn>
<vendor>ATA</vendor>
<product>LOGICAL VOLUME</product>
<alias name='scsi0-0-0-0'/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='native'/>
<source dev='/dev/disk/by-id/scsi-3600508b1001cb8ae0693a3fdcc1e17ca'/>
<backingStore/>
<target dev='sdb' bus='scsi'/>
<serial>PACCRID11320BPR</serial> <========これ
<wwn>600508b1001cb8ae</wwn>
<vendor>ATA</vendor>
<product>LOGICAL VOLUME</product>
<alias name='scsi0-0-0-1'/>
<address type='drive' controller='0' bus='0' target='0' unit='1'/>
</disk>
CVM上のマウントポイントは以下のようになります。
nutanix@NTNX-71f86937-A-CVM:172.20.1.114:~$ mount
(省略)
/dev/sdb1 on /home/nutanix/data/stargate-storage/disks/PACCRID11320BPR type ext4 (rw,nosuid,noatime,data=ordered,nodiscard,nodelalloc,init_itable=30)
/dev/sda4 on /home/nutanix/data/stargate-storage/disks/PACCRID11320BPR type ext4 (rw,nosuid,noatime,data=ordered,nodiscard,nodelalloc,init_itable=30)
none on /dev/cgroup type cgroup (rw,cpu,cpuacct,memory,freezer,net_cls)
この結果から、1つのSmartArrayコントローラ上で論理ディスクを2つ以上作ると死ぬ事が確定したので、これを回避する必要があります。どうにかコントローラからエクスポートするシリアルを変更できないか、CVM構成後にディスク情報を変えられないか調べたのですが、時間の無駄でした。
この記事を書きながらふと「ではlibvirt向けのxmlを書き出すところでstartctrlからの情報ではなくその都度ランダムに生成するようにすれば、あるいは…」とも思いましたが気力が尽きました。
対処法
今回の対処としては、光学ドライブに2.5インチのディスクをマウントする12.5mm厚のダミーマウンタを買い、SSDはAHCIに見せることにしました。

どうでも良いですが、ML380の光学ドライブを交換したあとにディスクの後ろに付いているスペーサに気がつきました。

めんどくさいのでそのままです。窪んでます。雑い。

ハマり3 何故かSmartArrayの通常ディスクがSSDとして認識されてしまう
かくして、マウントポイントが被る問題は対処できたのですが、今度は何故か何度CVMを作り直しても、通常のHDDがSSDとして認識されてしまいました。
これが今回の大きなハマりポイントでした。
Prismやnclからみても、HDDであるべきストレージがSSDと認識されてしまいます。もちろん、ホスト上の/sys/~/rotationalは1を返しています。1.5TのSSDが本当にあったら良かったんですが、残念ながらHDDです。

まあそのままでも動くので、階層化が全く機能しなくなるけどもう良いかなと心が折れかけていましたが、原因が見つかりました。
原因
Nutanix CEにinstallで入ると、インストールスクリプトの中でどのディスクがSSDであるかをhclリストの中から探し、その中になければ今回SSDとして認識されたディスク(cat /sys/~/rotational 0として認識したディスク)を/home/install/phx_iso/phoenix/hcl.jsonの中に追記し、それをCVMに渡すようです。
CVMは、起動時にそのjsonを元に、今アタッチされているディスクのうちどれがSSDかを確認するようです。アタッチされているディスクの情報は、libvirtのxmlに書かれたProduct名(今回は<product>LOGICAL VOLUME</product>と言う値)がCVMに渡るようです。
さて、この/home/install/phx_iso/phoenix/hcl.jsonですが、再インストールのためにrootで./cleanup.sh を行っても初期の状態には戻らないため、過去にecho 0 >/sys~をやって過去にSSDとして認識されてしまうと、そのディスクがずっとSSDとして残り続けるようです。これが原因でした。
対処法
/home/install/phx_iso/phoenix/hcl.jsonを編集し、該当行を消し、CVMを作り直します。もしくはもう一度USBメモリを作り直し、初期の状態にもどします。
今回は下記の行をまるっと削除し、再度installでログインしてCVMを作り直しました。
{
"nand_type": "MLC",
"capacity_gb": 240.02150400000002,
"interface": "SATA600",
"data": "true",
"last_edit": 1489090465,
"manufacturer": "Community Edition",
"boot": "true",
"model_string": "LOGICAL VOLUME",
"approved_by": "Nutanix, CE",
"model": "LOGICAL VOLUME",
"metadata": "true"
}
その後、無事にHDDとして認識されました。
まとめ
サポート外構成は、やめようね!!!
何故サポートしないか、それにはちゃんとした理由があると実感しました。つらかった…
少なくとも、NutanixにP410以前のSmartArrayカードはサポートされていないので使うべきではありません。特に1つのコントローラで2つ以上の論理ドライブを作成する場合は確実に死にます。
MegaRAIDカードの場合は、インストールスクリプト中でmegacliであれこれしてシリアルを抜き出しているようなので、それぞれのディスクをRAID0で見せる場合は大丈夫な気がしますが、複数のディスクでRAID5などを作成した場合は分かりません。
SmartArrayも、P420以降に関しては、ファームバージョン7くらいからHBAモードがあるのは確認しましたが、HBAモード時にディスクのSerialをどう返すかは未確認です。
しかしながら、このほぼ情報がないトラブルのおかげでずいぶんとnutanixがインストール時に何をするかを深いところまでみられたので、勉強にはなりました。あとncliやhpacucliも初めて使いましたが調査の段階で何度も様々なコマンドを打ったので、だいぶ慣れました。
多分運用が始まるとそれはそれで問題が出るので、何かあればまた記事にしようと思います。
[ 1 コメント ] ( 1516 回表示 ) | このエントリーのURL |
前編でまず2つの惨劇を体験しましたが、トラブルはまだ終わりません。
プライマリストレージサーバの置き換え
前編でプライマリを復旧したあと、しばらくそのままの環境で使っていましたが、その後バックアップサーバのST2000DL003が死にました。半年以内に3台のDM001と1台のDL003が連鎖的に死亡していくのをみて、さすがに怖くなってプライマリストレージサーバのHDDを全て交換することにしました。(ちなみに死亡したHDDに限って購入時のレシートが見つからないという)
グロ画像ことプライマリとバックアップサーバから引き抜いたDL003君とDM001君です

ストレージサーバの置き換えには、遊んでいたX8DTLにXeon L5630とメモリを適当に積み、ディスクには東芝製MD04ACA200を使う事とにしました。
惨事その3 RAIDアレイが突然死
X8DTLにはオンボードで LSI 1068Eから生える8ポートのJBODで見えるSATA/SASポートがあり、このポートを利用してmdraidでraid5のSRPデータストアを作成し、AHCIの方から生えているSATAポートを/などのOS用に割り当てることにしました。
当初はこれで問題なく動いていたのですが、構築から2週間後にZabbixから
kernel: mptbase: ioc0: WARNING - IOC is in FAULT state!!!
という見たくない感じのエラーが飛び、その後mdからディスクが1本もげました。
何故構築してから全く時間が経っていないのにディスクが故障?と思いましたが、とりあえず予備のMD04ACA200と交換することにしました。が、再構築中にmdがUU__U___になり死にました。その死に方も、一旦その状態になるとsmartctrl -x /dev/sdaなど、1068Eに繋がっている他のディスクに対して行うとエラーを返す、fdiskでも見えなくなるという状態でした。
この文章を書き起こしていても思い出したくないくらいのトラウマなのですが、全てのディスクをsmartやWindowsからHDTuneで読み書きテストをしてみても、特に問題は見つかりませんでした。仕方がないので、再度RAIDの初期化を行い、再度バックアップからの戻しを行いました。
しかし、また1ヶ月後に例のエラーが出て、ディスクアレイが死にました。
惨事その4 RAID HBAが突然死
おそらく、この状態になっていると言う事は、オンボードのLSIのチップが死んでいる?という可能性があったので、オンボードの1068Eを利用しないでLSI 2008チップを載せたD2607を追加し、JBODで見る設定にしました。何故このHBAかというと、手元にありかつ速度がそれなりに速くて接続されたディスクをJBODで見せられるというのが魅力だと感じたからでした。
が、こいつも1ヶ月後にmdが全崩壊を起こしました。
惨事その5 解決したと思わせてからのHBAの突然死
この辺でトラブルについてはほんともうお腹いっぱいだったのですが、この不定期に起きる悪夢の根本原因を探すことにしました。
しかし、何から調べたものか…と、困っていると、ディスクのsmartを取ろうとすると、smartを取得してからその情報を返すまで、非常にディスクのIOが遅くなっていることに気がつきました。
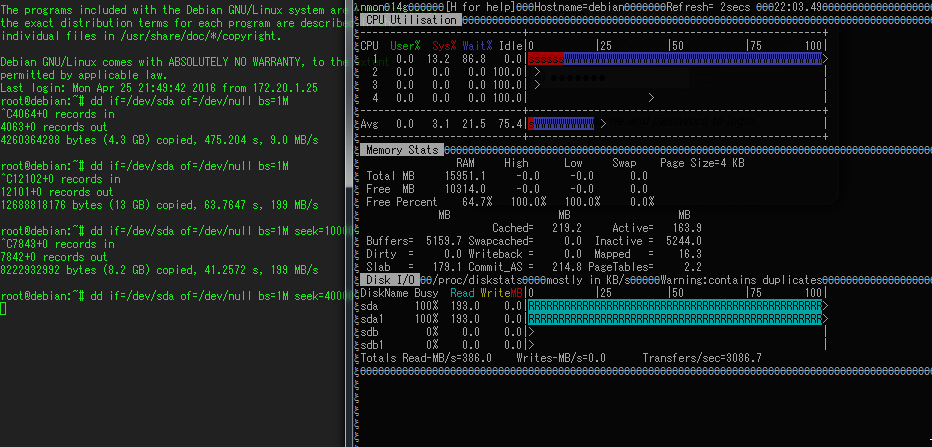
これを手がかりに、検証機でテストしてみると、何もないときはddで内容を読んでいても全く問題がないのですが、smartctrlを動かしながらddをすると、あるタイミングでsmartが刺さり、smartの内容を全く返さなくなり^Cでも中断できなくなり、かつIOがゼロになると言う問題が起きました。
何もせずにdd if=/dev/sda (D2607に繋がってるMD04ACA200) of=/dev/nullを行っているときの状態です。Readが193MB/s出ているので普通です。
その状態で、新しくSSHのセッションを張り、
while :; do smartctrl -x /dev/sda >/dev/null ;date; sleep 1 ; done
をした結果です。
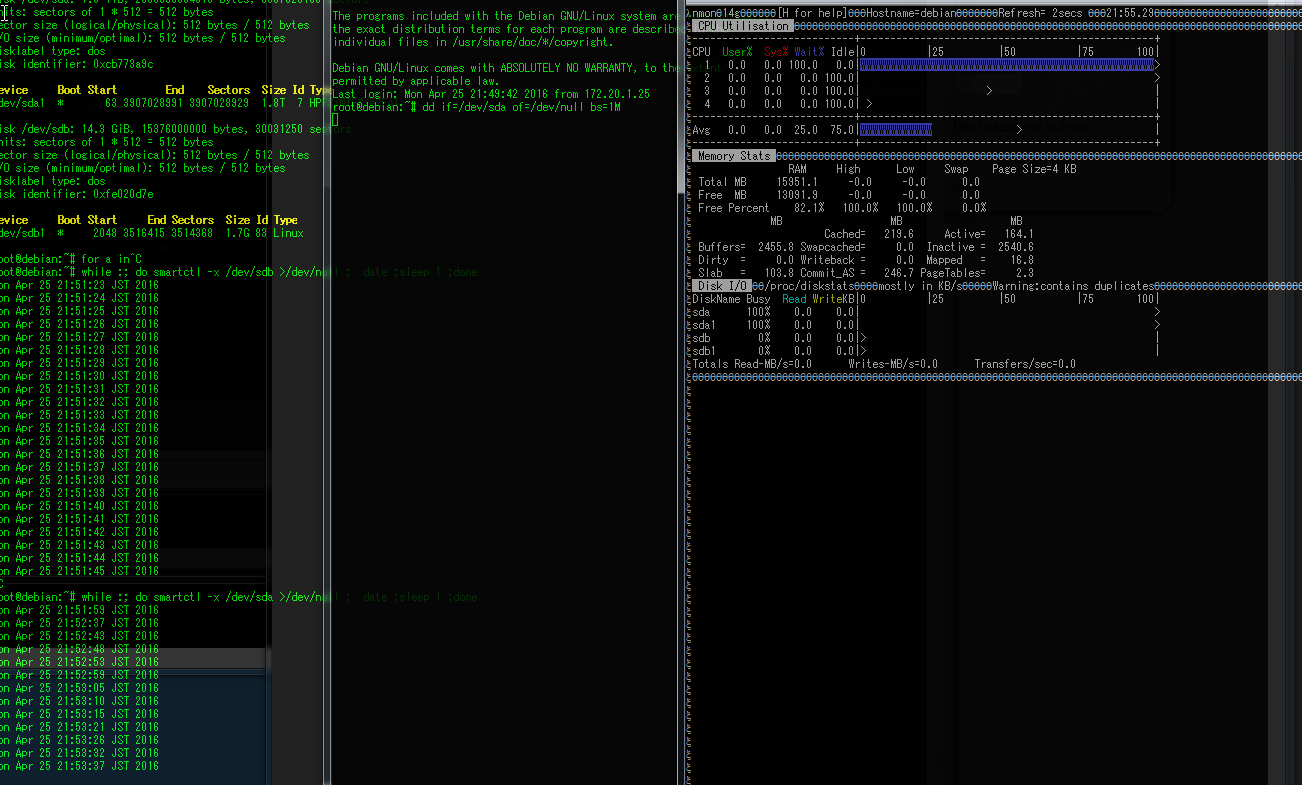
ddは続いているのですが、IOが0になり、かつDisk busyが100になり、CPUを1つI/O WAITで潰しています。
この内容で調べてみると、ぴったりではないのですが、D2607のファームウェア情報に、SMARTの情報異常を感知してコピーバックをする(予備ディスクに内容をコピーして異常時に備える)時にHBAが死ぬという情報があったので、とりあえずファームを新しくしてみました。
その結果、smartctrlをかけながらddをしても、smartを返す時にはIOは遅くなるものの、完全に刺さることはなくなりました。
また、Debianでsmartmontoolsを入れるとデフォルトで定期的にsmartdが各ディスクにSMARTクエリを飛ばすので、systemctl disable smartdを行い、ドライバもLSIから落としたものをビルドし、smart関連で刺さらないことを祈りました。ディスクへの情報取得で何かが起きていることはおそらく間違いないので、さすがにこれで解決したと思いました。いや、思いたかったのですが…
再びHBAが死にました。
再現性の調査
もしかしたらこの悪夢はLSI 2008チップと東芝のディスクの相性が原因で、他のLSI 2008チップを使っているHBAでも同じように起きるのでは?と思いいくつか試してみました。

検証環境で試した結果、以下の結果が分かりました。
・D2607だけではなく、HP OEMの LSI SAS 9212-4i(同じLSI2008チップを使うデフォルトでITモードで動くHBA)でもOSから複数のディスクでRAIDを組むと、バースト的な高負荷書き込みが連続すると不定期に死ぬ
・D2607はJBODを有効にせず、それぞれのディスクで1本のRAID0を作る(過去に8708EM2等で使われていた方法)を使うと検証期間中には問題が起きなかった(SMARTの取得は出来なくなりますが)
・MD04だけではなく、MD03、DT01、日立のHUA723でもSMARTの問題は起きる(これらのディスクは返す内容が大体同じ)
・SeagateのDM001、DL003、WDのCaviarGreen等ではSMARTの問題は起きない(日立系ディスクに比べて非常に簡素な内容しか返さない)
・LSI 2108を載せたボードでは、JBODは出来ないがHBA上でRAIDを組む分には問題なさそう(短期間しか試してないので怪しい)
以上のことから、LSI のチップでEnable JBODを有効にしてJBODでディスクをみていたり、ITモードで動くHBAと日立系のディスクは問題があるのかもしれないという結論に達しました。
ディスク全交換 そしてトラブルは静まる
上述のテストをしてる間に、秋葉原のBUYMOREでMG03ACAがバルクで入荷し、非常に安かったので一つ買ってみたところ問題が起きなさそうだったので、結局ディスクを全てMG03ACA300に交換してしまいました。MG03はSMARTでSAS系の情報を返すNL-SAS製品で、MD/DTシリーズとは動きが違うようでした(噂ではMGシリーズは富士通の流れをくむディスクで、それ以外は日立の流れをくむらしい。富士通のSASディスクでSMARTを見たことないので確証はありませんが、近いとは思います)。もうこのトラブルとおさらばできるのなら多少の出費は厭わない、という感じです。
このディスクに交換したところ、D2607でJBODで見ていても過去のトラブルが嘘のような平凡な日々が訪れました。少なくとも、今のところは…。
まとめ
今回の問題を回避するには、少なくともLinux上では
・LSIのチップに日立系のディスクを混ぜないこと
・LSIのチップで日立系のディスクを使うのなら、HBA自体のRAIDを利用すること(少なくともJBODで見るよりはトラブらない)
・日立系ディスクをJBODで見たいなら、オンボードのAHCI/SCUを使う事(smart取得時の速度低下は起きるが死ぬ事はなかった)
・2012年頃のSeagateのディスクはやばい(DM01が3/8で36%の故障率、DL003が1/6で16%の故障率)
と言うのが今のところの結論です。日立系のディスクと言っても、ニアラインSASや10kRPMのSASドライブではまた違うと思いますが、少なくともデスクトップ向けのディスクとLSIのチップは避けるべきのようです。
また、DM001の故障率は有名なBACKBLAZEでもST3000DM001が導入からちょうど2-3年で20-40%の割合で故障しているので、奇しくもこのデータと近い値が出てしまいました。このヤバいディスクがINしてるシステムでまだ問題が起きていないのであれば、早急に交換をおすすめします。(大半のディスクはもう死んでこの世にいないかもしれませんが)
1台2台がばらばらの時期に壊れてくれるのであれば良いのですが(良くはない)、まさか連続死を起こされるとは…。まあ、それを見越した設計でも最後の砦を壊したのはこの手でしたが。
この一件で、バックアップの重要性を身をもって実感することになり、いくつかのデータは仮想マシンではなく物理マシンにrsyncするようになりました。そしてディスクが安く売ってると買ってバックアップサーバを作らなくてはと言う強迫観念に駆られるという傷跡を残しました。
せめてもの救いは、オペミスしたのが自分の環境だったことで、仕事でやらなくて良かったという点です。個人的には仕事のデータなんかよりこちらの方がよほど大事ですが…。
かなり長い間悩んだ内容だったので記事自体も長くなってしまいましたが、誰かの役に立つことを願い一応まとめてみました。ストレージ関係の悪夢はほんとつらいので誰も見ないに越したことはないのですが。
[ コメントを書く ] ( 1033 回表示 ) | このエントリーのURL |
<<最初へ <戻る | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 進む> 最後へ>>