まずFreeNAS8.0RCの感想ですが、やっぱりまだ待ちかなあというのが本音です。
なおFreeNASの8.0RC5ではreadonlyで/がマウントされるのでmount -uw /しないとファイルが編集できません。最初にはまった点です。
1 つめは、DiskVolumeを作成するときに1とか2などの数字のみのボリュームを作ると「作成はされWebUIから見えるけど設定画面に行こうとするとそんなデバイスはないといわれる」という状態になりました。消すことは出来たのでvolとかTestという名前で作ったら問題なく作成できましたが…。
2 つめは、FreeNAS 8.0だとAHCIが有効になっていると/dev/gpt/にadaXとしてドライブがマウントされるのですが、ホットスワップしてから/dev/gpt 以下にマウントする方法が見つかりませんでした。camctrl devlistコマンドでデバイスは確認できるのですが…
3つめは、何故か起動時のBeepがならないという事。細かいかもしれないですが気にすると解決までその一点ではまるのが悪い癖です…。pfsenseで使われている Beepコマンドを使おうと思っても/dev/speakerが作成できず、/boot/loader.confni
Loadspeaker=trueとか色々試したのですが有効になりませんでした。
そんなわけで結局0.7.2のamd64版を使うことにしました。
今更FreeNASが云々と書いてももっと詳しい記事があるので書きませんがはまった点だけ何点かメモしておきます。
・/etc/crontabを編集しても起動時に初期化されるのでWebUIのSystem→Advancedから編集する。WebUIのCronにはない@reboot等の設定はCommand scriptsから編集する。
・ZFSをホットスワップするときはzpool offline tank devしてzpoolからデバイスをオフラインにする。atacontrol detach ataXでOSからのアクセスをとめたあとでもいい。
FreeBSD7だとahci認識されたHDDもatacontrolから設定する
実行する前
/root: zpool status
pool: vol
state: ONLINE
scrub: resilver completed after 0h0m with 0 errors on Sat Apr 23 15:54:26 2011
config:
NAME STATE READ WRITE CKSUM
vol ONLINE 0 0 0
raidz1 ONLINE 0 0 0
ad4 ONLINE 0 0 0
ad6 ONLINE 0 0 0
ad10 ONLINE 0 0 0
ad12 ONLINE 0 0 0
ata2(ad4)をOSからアクセスできなくする。実験用なので古いHDDが混ざってます。
/root: atacontrol list
ATA channel 2:
Master: ad4 <ST3408111AS/3.AAE> SATA revision 2.x
Slave: no device present
ATA channel 3:
Master: ad6 <ST340215AS/3.AAC> SATA revision 2.x
Slave: no device present
ATA channel 4:
Master: ad8 <ST340014AS/3.43> SATA revision 1.x
Slave: no device present
ATA channel 5:
Master: ad10 <ST340215AS/3.AAC> SATA revision 2.x
Slave: no device present
ATA channel 6:
Master: ad12 <WDC WD400JD-55MSA1/10.01E01> SATA revision 2.x
Slave: no device present
ATA channel 7:
Master: ad14 <SAMSUNG HD040GJ/P/ZG100-46> SATA revision 1.x
Slave: no device present
/root: atacontrol detach ata2
/root: zpool status
pool: vol
state: DEGRADED
scrub: resilver completed after 0h0m with 0 errors on Sat Apr 23 15:54:26 2011
config:
NAME STATE READ WRITE CKSUM
vol DEGRADED 0 0 0
raidz1 DEGRADED 0 0 0
ad4 REMOVED 0 0 0
ad6 ONLINE 0 0 0
ad10 ONLINE 0 0 0
ad12 ONLINE 0 0 0
zpoolからad4を除外する
/root: zpool offline vol ad4
/root: zpool status
pool: vol
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
scrub: resilver completed after 0h0m with 0 errors on Sat Apr 23 15:54:26 2011
config:
NAME STATE READ WRITE CKSUM
vol DEGRADED 0 0 0
raidz1 DEGRADED 0 0 0
ad4 OFFLINE 0 0 0
ad6 ONLINE 0 0 0
ad10 ONLINE 0 0 0
ad12 ONLINE 0 0 0
そしたらHDDのホットスワップをしてみます。こういうケースだと無駄にHDDを抜き差ししたくなりますね。「Cover me while i reload!!!」とか言いながら。
ホットスワップが終わったらatacontrolでディスクの再認識をします
/root(115): atacontrol attach ata2
Master: ad4 <ST3408111AS/3.AAE> SATA revision 2.x
Slave: no device present
ここでSATA1のHDDを挿すとカーネルパニックが起きます。これだけ実験用HDDがあるとたまに地雷が混ざってるので怖いです。これはラジオデパートで40GのSATA HDDが400円で大量に流れた時にまとめて買ったものです
HDDSentinelで見た限りだと何故か起動時間が2h等しかないHDDもあったので、HDDに張ってあるラベルなどからサーバーの保守パーツっぽいです。

容量的にはゴミですが、自分みたいに実機で色々実験するとき(特にRAIDとかファイルシステムの評価の時)には弾数が必要になるのでそう言う人にはもってこいです。
実はまだあったりするのですが引っ張り出してくるのがしんどいのでやめました。さすがにこれは自分でもやりすぎた感が…w
・zpoolからディスクをアクティブにするときにzpool online tank devをすると元のデバイスだと同じHDDとしてアクセスしようとするらしくzpoolが応答しなくなって死ぬのでzpool replace tank devをする
/root: zpool replace vol ad4
/root: zpool status
pool: vol
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scrub: resilver in progress for 0h0m, 5.80% done, 0h7m to go
config:
NAME STATE READ WRITE CKSUM
vol DEGRADED 0 0 0
raidz1 DEGRADED 0 0 0
replacing DEGRADED 0 0 0
ad4/old OFFLINE 0 0 0
ad4 ONLINE 0 0 0 131M resilvered
ad6 ONLINE 0 0 0 201K resilvered
ad10 ONLINE 0 0 0 198K resilvered
ad12 ONLINE 0 0 0 140K resilvered
しばらくするとリビルドがおわります。リビルドは使ってる容量に比例して増えるようです
/root: zpool status
pool: vol
state: ONLINE
scrub: resilver completed after 0h1m with 0 errors on Sat Apr 23 18:06:31 2011
config:
NAME STATE READ WRITE CKSUM
vol ONLINE 0 0 0
raidz1 ONLINE 0 0 0
ad4 ONLINE 0 0 0 2.20G resilvered
ad6 ONLINE 0 0 0 781K resilvered
ad10 ONLINE 0 0 0 752K resilvered
ad12 ONLINE 0 0 0 497K resilvered
errors: No known data errors
・シェルから全て設定してしまいましたが、WebUIからも一応設定できます。クリックする数が多すぎるのでやめましたが。
・シェルから設定するとWebUIのデバイスには出てきません。
・シェルから設定してしまうとPC起動時にZFSは自動的にマウントされないのでzfs set mountpoint=/mnt/point tankname等でマウントポイントを指定したあと、WebUIのCommand scriptsの項目にzfs mount -aと記述しておく
この辺が分かればZFSライフを満喫できるようになると思います。
あとはスナップショットがありますがこの辺はググって出てくる情報と同じなのでで省略します。
ちなみにHDD4台使ってRAIDZ1(RAID5相当)を組んだときの速度
CPU E3300@定格、Mem2G
4G書き込み
/root: dd if=/dev/zero of=/mnt/vol/4G bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes transferred in 32.628626 secs (128546756 bytes/sec)
CPU: 0.0% user, 0.0% nice, 38.5% system, 1.9% interrupt, 59.6% idle
4G読み込み
/root: dd of=/dev/null if=/mnt/vol/4G bs=1M
4000+0 records in
4000+0 records out
4194304000 bytes transferred in 25.032930 secs (167551460 bytes/sec)
CPU: 0.0% user, 0.0% nice, 29.3% system, 3.2% interrupt, 67.5% idle
ブロックサイズが大きければ結構早いと言うことが分かりました。
しかしメインファイルサーバとの同期でrsync等を走らせたりして書き込みが発生するとメモリをがつがつ消費していくのでやっぱり割と高性能なHWを使うべきですね。
まあ、バックアップ機なので十分ですけどね。
[ コメントを書く ] ( 1908 回表示 ) | このエントリーのURL |
Vyattaを2-3日いじってみて中々pfsenseとは性格が違ったので、そのときの備忘録としてのメモとベンチなどを取ってみました。
ついでにどう違うか比較してみました。
Vyattaバージョン
vyatta@vyatta# uname -a
Linux vyatta 2.6.35-1-586-vyatta #1 SMP Fri Feb 4 05:07:37 PST 2011 i686 GNU/Linux
pfsenseバージョン
2.0-RC1 (i386)
built on Fri Apr 1 20:54:38 EDT 2011
amd64を使うべきか悩みましたが2Gしかメモリ積んでいないし相手が32ビットなのであえて32ビット版を使っています。
使用したハードウェア構成
このご時世仮想マシンではなくて実マシンを使っています。HDDも結構余ってるのでHDDに入れて実験しました。
Vyattaとpfsenseを入れたマシン
MB: P5M2/2GBL
これのSASオミット版です
Mem DDR2 800(667動作) 2G*1
CPU PentiumDC 5200@定格
NIC Broadcom BCM5721 PCI-E Gb LAN*2(オンボード)

写真にはDualportなNICが刺さってますが実験の時には抜きました。ifconfigしたときにeth0から6まで並ぶのを見るのは幸せな気分になれる反面間違えが増えますw
AB!(Apache Bench)&IperfされるNAPT内側のマシン構成
OS BacktrackLinux 4 R2
MB TPower I45
CPU E5400@定格
Mem DDR2 800 2GB*2
NIC RTL8111/8168B PCI Express Gigabit Ethernet controller
いつもの実験用バラックマシンです。BTはUSBに入れておくとサクッと実験用マシンを作れるので便利です。
NAPT外側マシン
OS Ubuntu 10.0.4 amd64
MB TYAN-Toledo-i3210W-i3200R-S5220
CPU C2Q6600@定格
Mem Mem DDR2 800 2GB*2
NIC Intel 82573L Gigabit Ethernet Controller*2
信頼のintelNIC
基本設定
---Vyatta---
Vyatta はルーターとして注力してるだけあって、vbashと呼ばれる(いわゆるCISCOのIOSライクな体系の)コマンドを持った独自のシェルを持っていて、方言さえ吸収できればそこらのネットワーク機器をいじったことのある人なら勘で設定できるようになってます。
Configureでコンフィグレーションモードに入ってset interface ethernet ethx addressでアドレスを固定して…といった感じです。
ちなみに、デフォルトでは全てAcceptになっていてパケットは全て通ります。
ただ、インストールが終わるといきなり$プロンプトなので、初心者向けかと言われるとちょっと悩みます(初心者がこんなものいじるかというのは置いておいて w)。ドキュメントは揃っているので必要なことは全てドキュメントを読めば記述してありますが、どちらかというとこの手の機器をいじったことのある中級者向けだと思います。
ちなみにvbashと言いつつも中身はDebianベースなのでsudo bash等と打てばrootで普通のbashが使えます。aptなどもレポジトリを追加すれば普通のパッケージも入ります。
一応WebUIも持っているは持っていますが基本はSSH/S0(シリアルポート)などからCLIで設定することになると思います。
---pfsense---
インストールが終わったらインターフェースのIPを指定すれば最初からDHCPdが有効になるので、そこから初期設定含めてWebUIから行うのがメインです。次へ次へで基本設定は終わるのでわかりやすいのはこっちだと思います。
pfsenseはFirewallなので、デフォルトは外からのパケットは全て破棄されます。たまにこれを忘れて繋がらないと悩むことがありますw
NAT,NAPTなんかはこっちの方が直感的なUIなので設定しやすいです。
設定すればSSHも使えるので、tcsh等のシェルからFWなどの設定をしようと思えば色々設定できますが、下手にいじるとWebUIがバグることがあるので注意が必要です。
BSDなのでPortsも使えます。まあBSDを使うような人はやろうと思ったら何でも出来ると思いますが。
WebUI
---vyatta---
GUIといっても簡易的なものです。
コマンドがディレクトリになっていて、そこに値を入れるようになっています。
vbashコマンドと対応しているので、CLIがわからないとわかりづらいと思います。
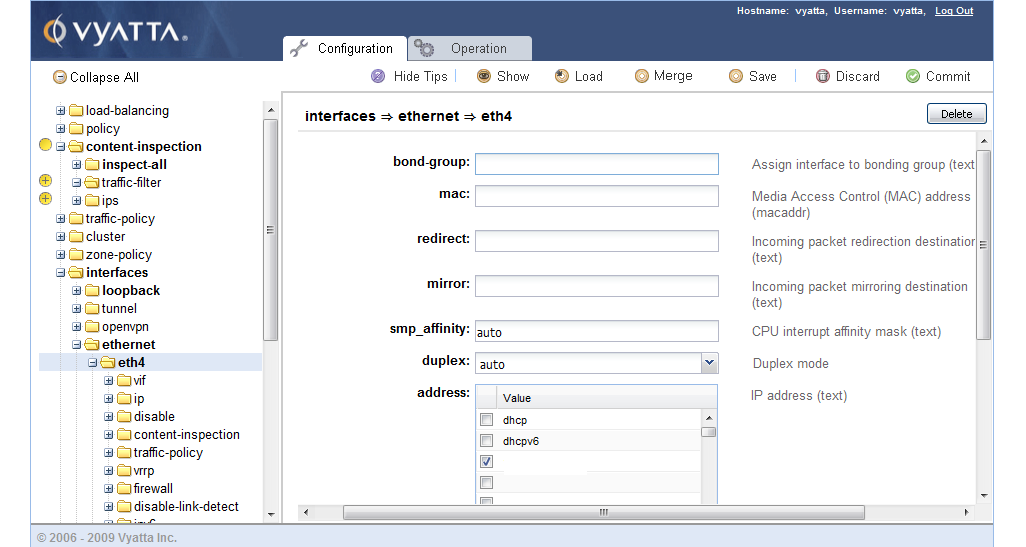
DNATのポリシーをいじっているとき、SSHとWebUIからいじっていたらWebUIからCommitした瞬間SSHの方の設定がCommit出来なくなってDeleteすら出来なくなったというバグ?があったので同時にいじるのはおすすめしません
---pfsense---
Vyattaとは全く違って高機能です。
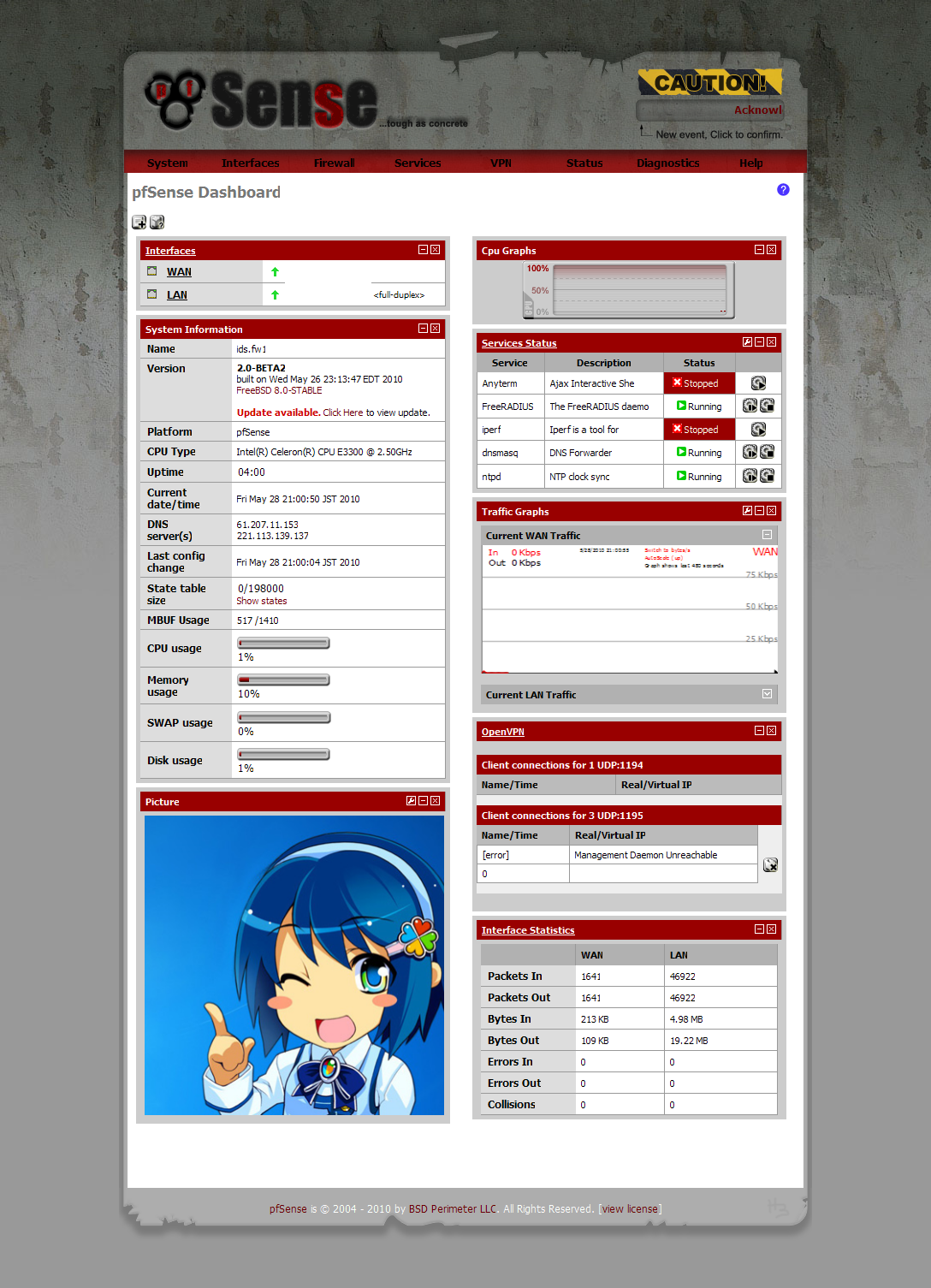
市販のBBルータのようなUIなのである程度わかれば苦労はないと思います。
逆に設定するときにはトップから一々辿らないといけないとも言えますが。
viで/cf/conf/config.xmlを直に編集すればCUIから全て設定できると言えばできますが…。
Config
---vyatta---
まずVyattaの設定です。基本的なNAPTのみを有効にした場合の性能です。
config
interfaces {
ethernet eth4 {####LANインターフェース########
address 192.168.3.45/24
duplex auto
hw-id 00:18:f3:7d:5f:c2
smp_affinity auto
speed auto
}
ethernet eth5 {####WANインターフェース########
address 192.168.1.46/24
duplex auto
hw-id 00:18:f3:7d:5f:c3
smp_affinity auto
speed auto
}
loopback lo {
}
}
service {
https {
}
nat {
rule 10 { ####ApacheBenchのNAPTエントリ####
destination {
port 80
}
inbound-interface eth5 ####Eth5が外側のインターフェース####
inside-address {
address 192.168.3.46 ####←NAPT先マシン####
}
protocol tcp
type destination
}
rule 40 {########Iperf用エントリ########
destination {
port 5001
}
inbound-interface eth5
inside-address {
address 192.168.3.46
}
protocol tcp
type destination
}
rule 100 { ####内側から外側へ出るエントリ####
outbound-interface eth5
type masquerade
}
}
ssh {
port 22
protocol-version v2
}
}
system {
config-management {
commit-revisions 20
}
console {
device ttyS0 {
speed 9600
}
}
gateway-address 192.168.1.1
host-name vyatta
login {
user vyatta {
authentication {
encrypted-password ****************
}
level admin
}
}
name-server 192.168.1.18
ntp {
server 0.vyatta.pool.ntp.org {
}
server 1.vyatta.pool.ntp.org {
}
server 2.vyatta.pool.ntp.org {
}
}
package {
auto-sync 1
repository community {
components main
distribution stable
password ****************
url http://packages.vyatta.com/vyatta
username ""
}
}
syslog {
global {
facility all {
level notice
}
facility protocols {
level debug
}
}
}
time-zone GMT
}
一般的なNAPT用設定です。
最初はDNAT元アドレスにインターフェースアドレスを指定しないといけないのかと思った(つまり固定IPが必要だと思った)のですがPortを指定しておけばAddressを指定しなくても問題ない(=動的アドレスでも大丈夫)みたいです。
---pfsense---
NAPTだけを有効にした状態です。細かいことはいじってないです。
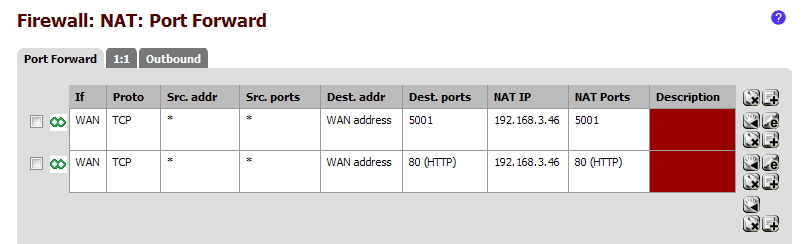
Iperf によるスループット
ーーーVyatta Iperfーーー
root@1:/home/owner# iperf -c 192.168.1.46 -i 1 -w 128K -t 30
------------------------------------------------------------
Client connecting to 192.168.1.46, TCP port 5001
TCP window size: 256 KByte (WARNING: requested 128 KByte)
------------------------------------------------------------
[ 3] local 192.168.1.22 port 57698 connected with 192.168.1.46 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 1.0 sec 111 MBytes 934 Mbits/sec
[ 3] 1.0- 2.0 sec 111 MBytes 935 Mbits/sec
[ 3] 2.0- 3.0 sec 112 MBytes 936 Mbits/sec
[ 3] 3.0- 4.0 sec 112 MBytes 939 Mbits/sec
[ 3] 4.0- 5.0 sec 111 MBytes 935 Mbits/sec
[ 3] 5.0- 6.0 sec 112 MBytes 936 Mbits/sec
[ 3] 6.0- 7.0 sec 112 MBytes 937 Mbits/sec
[ 3] 7.0- 8.0 sec 112 MBytes 937 Mbits/sec
[ 3] 8.0- 9.0 sec 112 MBytes 940 Mbits/sec
[ 3] 9.0-10.0 sec 112 MBytes 938 Mbits/sec
[ 3] 10.0-11.0 sec 111 MBytes 931 Mbits/sec
[ 3] 11.0-12.0 sec 112 MBytes 942 Mbits/sec
[ 3] 12.0-13.0 sec 110 MBytes 925 Mbits/sec
[ 3] 13.0-14.0 sec 112 MBytes 936 Mbits/sec
[ 3] 14.0-15.0 sec 112 MBytes 940 Mbits/sec
[ 3] 15.0-16.0 sec 111 MBytes 933 Mbits/sec
[ 3] 16.0-17.0 sec 112 MBytes 943 Mbits/sec
[ 3] 17.0-18.0 sec 111 MBytes 935 Mbits/sec
[ 3] 18.0-19.0 sec 111 MBytes 935 Mbits/sec
[ 3] 19.0-20.0 sec 112 MBytes 935 Mbits/sec
[ 3] 20.0-21.0 sec 112 MBytes 935 Mbits/sec
[ 3] 21.0-22.0 sec 112 MBytes 939 Mbits/sec
[ 3] 22.0-23.0 sec 111 MBytes 934 Mbits/sec
[ 3] 23.0-24.0 sec 113 MBytes 944 Mbits/sec
[ 3] 24.0-25.0 sec 111 MBytes 933 Mbits/sec
[ 3] 25.0-26.0 sec 111 MBytes 931 Mbits/sec
[ 3] 26.0-27.0 sec 112 MBytes 936 Mbits/sec
[ 3] 27.0-28.0 sec 113 MBytes 946 Mbits/sec
[ 3] 28.0-29.0 sec 111 MBytes 930 Mbits/sec
[ 3] 29.0-30.0 sec 112 MBytes 939 Mbits/sec
[ 3] 0.0-30.0 sec 3.27 GBytes 936 Mbits/sec
そのときのCPU使用率
ATOP - vyatta 2011/04/02 18:05:01 3 seconds elapsed
PRC | sys 0.03s | user 0.00s | #proc 85 | #zombie 0 | #exit 0 |
CPU | sys 0% | user 0% | irq 3% | idle 196% | wait 0% |
cpu | sys 0% | user 0% | irq 3% | idle 97% | cpu000 w 0% |
cpu | sys 0% | user 0% | irq 1% | idle 99% | cpu001 w 0% |
CPL | avg1 0.00 | avg5 0.00 | avg15 0.00 | csw 70 | intr 104834 |
MEM | tot 2.0G | free 1.9G | cache 38.2M | buff 7.4M | slab 8.8M |
SWP | tot 0.0M | free 0.0M | | vmcom 61.4M | vmlim 1.0G |
NET | transport | tcpi 9 | tcpo 9 | udpi 0 | udpo 0 |
NET | network | ipi 170928 | ipo 170928 | ipfrw 170919 | deliv 9 |
NET | eth5 97% | pcki 242124 | pcko 121368 | si 978 Mbps | so 22 Mbps |
NET | eth4 97% | pcki 121373 | pcko 242131 | si 22 Mbps | so 978 Mbps |
NET | lo ---- | pcki 8 | pcko 8 | si 1 Kbps | so 1 Kbps |
PID SYSCPU USRCPU VGROW RGROW RDDSK WRDSK ST EXC S CPU CMD 1/1
4332 0.03s 0.00s 0K 0K 0K 0K -- - R 1% atop
1671 0.00s 0.00s 0K 0K 0K 0K -- - S 0% bgpd
1657 0.00s 0.00s 0K 0K 0K 0K -- - S 0% ripd
すごい、NAPTして1Gのトラフィック流してもCPU使用率は僅かです。さすがCiscoの機材にも勝つ性能があると言っているだけはあります。
---pfsense iperf---
owner@Server:~$ iperf -c 192.168.1.45 -w 128K -i 1 -t 30
------------------------------------------------------------
Client connecting to 192.168.1.45, TCP port 5001
TCP window size: 256 KByte (WARNING: requested 128 KByte)
------------------------------------------------------------
[ 3] local 192.168.1.14 port 57503 connected with 192.168.1.45 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 1.0 sec 112 MBytes 942 Mbits/sec
[ 3] 1.0- 2.0 sec 112 MBytes 940 Mbits/sec
[ 3] 2.0- 3.0 sec 112 MBytes 940 Mbits/sec
[ 3] 3.0- 4.0 sec 113 MBytes 944 Mbits/sec
[ 3] 4.0- 5.0 sec 112 MBytes 941 Mbits/sec
[ 3] 5.0- 6.0 sec 112 MBytes 942 Mbits/sec
[ 3] 6.0- 7.0 sec 112 MBytes 941 Mbits/sec
[ 3] 7.0- 8.0 sec 112 MBytes 940 Mbits/sec
[ 3] 8.0- 9.0 sec 113 MBytes 946 Mbits/sec
[ 3] 9.0-10.0 sec 111 MBytes 933 Mbits/sec
[ 3] 10.0-11.0 sec 112 MBytes 942 Mbits/sec
[ 3] 11.0-12.0 sec 112 MBytes 940 Mbits/sec
[ 3] 12.0-13.0 sec 112 MBytes 942 Mbits/sec
[ 3] 13.0-14.0 sec 112 MBytes 938 Mbits/sec
[ 3] 14.0-15.0 sec 112 MBytes 942 Mbits/sec
[ 3] 15.0-16.0 sec 112 MBytes 941 Mbits/sec
[ 3] 16.0-17.0 sec 113 MBytes 945 Mbits/sec
[ 3] 17.0-18.0 sec 112 MBytes 939 Mbits/sec
[ 3] 18.0-19.0 sec 112 MBytes 944 Mbits/sec
[ 3] 19.0-20.0 sec 112 MBytes 939 Mbits/sec
[ 3] 20.0-21.0 sec 112 MBytes 938 Mbits/sec
[ 3] 21.0-22.0 sec 112 MBytes 939 Mbits/sec
[ 3] 22.0-23.0 sec 113 MBytes 944 Mbits/sec
[ 3] 23.0-24.0 sec 112 MBytes 941 Mbits/sec
[ 3] 24.0-25.0 sec 112 MBytes 943 Mbits/sec
[ 3] 25.0-26.0 sec 112 MBytes 939 Mbits/sec
[ 3] 26.0-27.0 sec 113 MBytes 945 Mbits/sec
[ 3] 27.0-28.0 sec 112 MBytes 938 Mbits/sec
[ 3] 28.0-29.0 sec 112 MBytes 941 Mbits/sec
[ 3] 29.0-30.0 sec 112 MBytes 944 Mbits/sec
[ 3] 0.0-30.0 sec 3.29 GBytes 941 Mbits/sec
そのときのCPU使用率@top
last pid: 27079; load averages: 0.00, 0.02, 0.04 up 0+00:27:40 00:35:07
33 processes: 1 running, 32 sleeping
CPU: 0.0% user, 0.0% nice, 0.0% system, 64.1% interrupt, 35.9% idle
Mem: 36M Active, 17M Inact, 48M Wired, 356K Cache, 33M Buf, 1890M Free
Vyattaは単純なスループット測定時には10%もCPUを使っていなかったので、それを考えるとpfsenseはCPUを食います。
まあ、裏でPacketFilterが動いてパケットを見ているので仕方がないのですが。
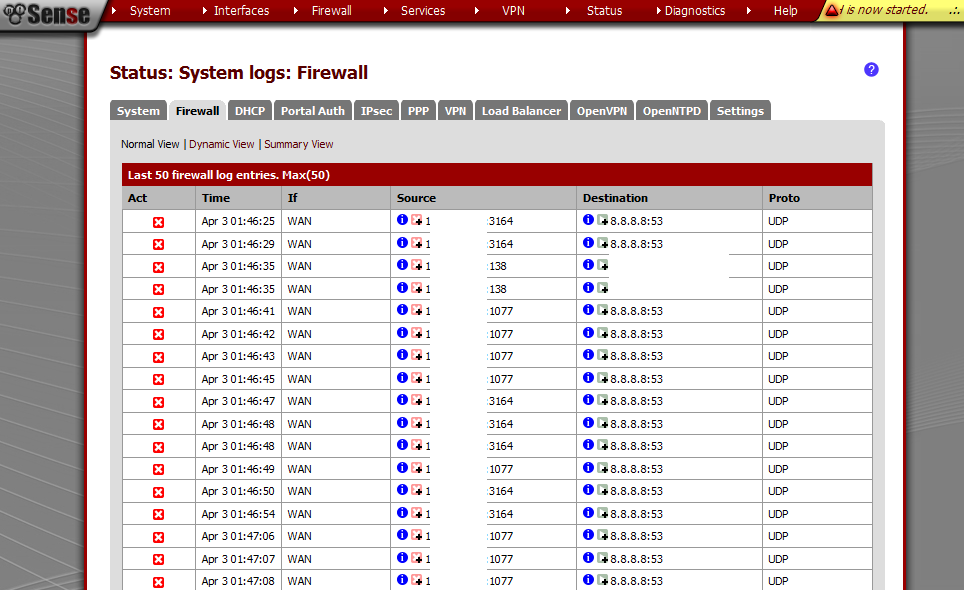
ApacheBench
---Vyatta ApacheBench---
AB先はApacheデフォルトのIt works!!ページです。
<html><body><h1>It works!</h1></body></html>
※試した限りどうもLighttpdの方がセッションを捌くのが早いのでLighttpdを使っています。
root@1:/home/owner# ab -n 10000 -c 500 http://192.168.1.46/index.html
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.1.46 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: lighttpd/1.4.19
Server Hostname: 192.168.1.46
Server Port: 80
Document Path: /index.html
Document Length: 45 bytes
Concurrency Level: 500
Time taken for tests: 0.680 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 2781112 bytes
HTML transferred: 450180 bytes
Requests per second: 14707.29 [#/sec] (mean)
Time per request: 33.997 [ms] (mean)
Time per request: 0.068 [ms] (mean, across all concurrent requests)
Transfer rate: 3994.40 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 3 6 1.9 6 18
Processing: 4 9 7.0 9 219
Waiting: 3 8 7.0 7 217
Total: 8 15 7.7 14 224
Percentage of the requests served within a certain time (ms)
50% 14
66% 15
75% 15
80% 15
90% 16
95% 26
98% 37
99% 40
100% 224 (longest request)
長いですが要はFailed requests: 0で
Complete requests: 10000のTime taken for tests: 0.680 secondsなので、500同時セッションで10000回のアクセスを0.6秒でセッションを捌ききりました、ということです。
CPU使用率は1秒かからなかったのでatopで観測できませんでした。
ちなみにあんまりnの回数を増やすとセッションのキューに入ってしまうらしく一時待ち時間が入ってしまい、完了まで時間がばらついてしまうのでこの値になっています。configを色々いじってもいまいち効果がでなかったのでデフォルトのconfigです。
---pfsense ApacheBench---
root@1:/home/owner# ab -n 10000 -c 500 http://192.168.1.45/index.html
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
中略
Server Software: lighttpd/1.4.19
Server Hostname: 192.168.1.45
Server Port: 80
Document Path: /index.html
Document Length: 45 bytes
Concurrency Level: 500
Time taken for tests: 1.060 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 2788340 bytes
HTML transferred: 451350 bytes
Requests per second: 9431.15 [#/sec] (mean)
Time per request: 53.016 [ms] (mean)
Time per request: 0.106 [ms] (mean, across all concurrent requests)
Transfer rate: 2568.09 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 5 14 4.0 13 27
Processing: 6 21 34.9 16 702
Waiting: 6 19 34.8 15 700
Total: 15 35 35.1 28 721
Percentage of the requests served within a certain time (ms)
50% 28
66% 33
75% 37
80% 39
90% 42
95% 43
98% 46
99% 272
100% 721 (longest request)
マシンを起動しっぱなしでGWだけ入れ替えたので基本的にVyattaと同じコンディションですが、Time taken for tests: 1.060 secondsなのでやはりVyattaには単純な性能では劣ります。
Firewall
Vyatta
VyattaのFWは、いわゆるACL形式のソース/ディストIPアドレス、ポート、プロトコルで指定する条件合致型です。元々の意味のFirewallですね。
50個ほど作ってみましたがこの程度だと特にAB/Iperfの値に変化はありませんでした。
pfsense
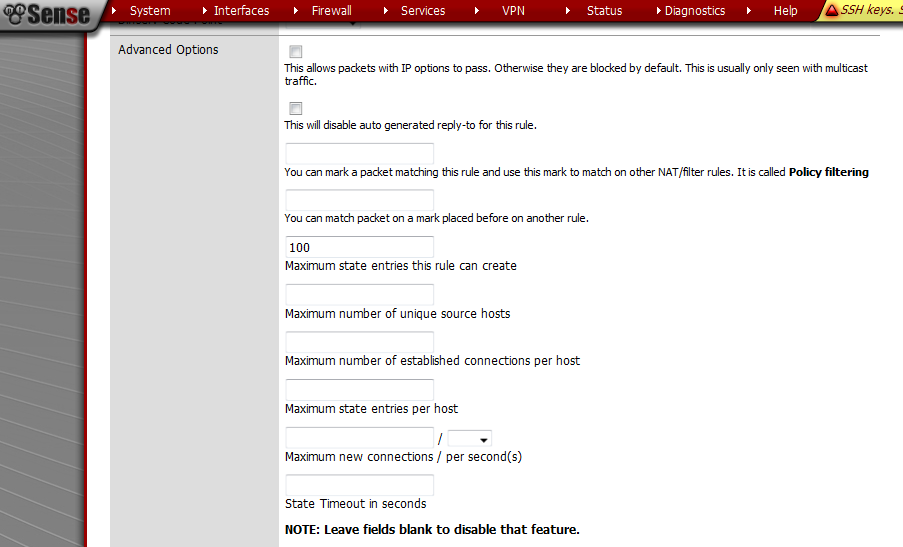
さすがFWなだけあって、たとえば一気にセッションを張ろうとしても100セッション以上はDropする、というような設定にすることも出来ます。
oot@1:/home/owner# ab -n 10000 -c 500 http://192.168.1.45/index.html
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.1.45 (be patient)
apr_socket_recv: Connection timed out (110)
Total of 99 requests completed
という感じで100セッション以上は張ることが出来なくなりました。
ブロックする対象はn秒間にN回新しいセッションを張る、それプラスSynフラグやらRSTフラグなど、その他諸々いじれる項目は多岐にわたります。
そしてこれらの条件に合致するとロックアウトされます。それをくらうとしばらくホストに接続できなくなります。
また、あまりにやり過ぎるとDiagnostics:→Tables→Virusportに隔離されるので、ここから削除しないとそのIPは一生繋がりません
IPS(Snort)
SnortとはOpensourceなIPSで、パケットの中身をみてたとえばHTTPのヘッダに変なものが含まれていないか等の検査をするL7パケット精査ソフトウェアです。有効にするとかなり重くなります。
---vyatta---
上に書いてある設定に
[edit]
vyatta@vyatta# set content-inspection inspect-all enable
[edit]
vyatta@vyatta# set content-inspection traffic-filter preset all
[edit]
vyatta@vyatta# set content-inspection ips actions priority-1 alert
[edit]
vyatta@vyatta# set content-inspection ips actions priority-2 alert
[edit]
vyatta@vyatta# set content-inspection ips actions priority-3 alert
でSnortを有効化します。
---pfsense---
有効にするにはPackageからSnortを選んでインストールするだけです。
Snortの設定に関して言えばGUIから設定できるpfsenseの方がわかりやすいです。
IPSを有効にした状態での性能
---snortvyatta iperf---
root@1:/home/owner# iperf -c 192.168.1.46 -i 1 -w 128K -t 30
------------------------------------------------------------
Client connecting to 192.168.1.46, TCP port 5001
TCP window size: 256 KByte (WARNING: requested 128 KByte)
------------------------------------------------------------
[ 3] local 192.168.1.22 port 38723 connected with 192.168.1.46 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 1.0 sec 26.2 MBytes 220 Mbits/sec
[ 3] 1.0- 2.0 sec 25.7 MBytes 216 Mbits/sec
[ 3] 2.0- 3.0 sec 25.8 MBytes 217 Mbits/sec
[ 3] 3.0- 4.0 sec 25.9 MBytes 217 Mbits/sec
[ 3] 4.0- 5.0 sec 25.1 MBytes 211 Mbits/sec
[ 3] 5.0- 6.0 sec 25.8 MBytes 217 Mbits/sec
[ 3] 6.0- 7.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 7.0- 8.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 8.0- 9.0 sec 26.1 MBytes 219 Mbits/sec
[ 3] 9.0-10.0 sec 25.9 MBytes 217 Mbits/sec
[ 3] 10.0-11.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 11.0-12.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 12.0-13.0 sec 25.9 MBytes 217 Mbits/sec
[ 3] 13.0-14.0 sec 25.4 MBytes 213 Mbits/sec
[ 3] 14.0-15.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 15.0-16.0 sec 25.8 MBytes 216 Mbits/sec
[ 3] 16.0-17.0 sec 25.9 MBytes 217 Mbits/sec
[ 3] 17.0-18.0 sec 25.2 MBytes 211 Mbits/sec
[ 3] 18.0-19.0 sec 25.7 MBytes 216 Mbits/sec
[ 3] 19.0-20.0 sec 25.8 MBytes 216 Mbits/sec
[ 3] 20.0-21.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 21.0-22.0 sec 25.4 MBytes 213 Mbits/sec
[ 3] 22.0-23.0 sec 25.3 MBytes 212 Mbits/sec
[ 3] 23.0-24.0 sec 25.2 MBytes 212 Mbits/sec
[ 3] 24.0-25.0 sec 25.8 MBytes 216 Mbits/sec
[ 3] 25.0-26.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 26.0-27.0 sec 25.3 MBytes 212 Mbits/sec
[ 3] 27.0-28.0 sec 25.9 MBytes 217 Mbits/sec
[ 3] 28.0-29.0 sec 26.0 MBytes 218 Mbits/sec
[ 3] 29.0-30.0 sec 25.9 MBytes 217 Mbits/sec
[ 3] 0.0-30.0 sec 773 MBytes 216 Mbits/sec
CPU使用率
ATOP - vyatta 2011/04/02 21:41:55 3 seconds elapsed
PRC | sys 1.29s | user 1.70s | #proc 84 | #zombie 0 | #exit ? |
CPU | sys 16% | user 56% | irq 34% | idle 94% | wait 0% |
cpu | sys 15% | user 54% | irq 26% | idle 5% | cpu001 w 0% |
cpu | sys 1% | user 1% | irq 8% | idle 90% | cpu000 w 0% |
CPL | avg1 0.43 | avg5 0.13 | avg15 0.04 | csw 718 | intr 33820 |
MEM | tot 2.0G | free 1.8G | cache 45.3M | buff 6.7M | slab 9.6M |
SWP | tot 0.0M | free 0.0M | | vmcom 209.4M | vmlim 1.0G |
NET | transport | tcpi 5 | tcpo 5 | udpi 0 | udpo 0 |
NET | network | ipi 40968 | ipo 84660 | ipfrw 84655 | deliv 5 |
NET | eth5 22% | pcki 56482 | pcko 28272 | si 228 Mbps | so 5298 Kbps |
NET | eth4 22% | pcki 28536 | pcko 56396 | si 5345 Kbps | so 228 Mbps |
NET | lo ---- | pcki 4 | pcko 4 | si 0 Kbps | so 0 Kbps |
PID SYSCPU USRCPU VGROW RGROW RDDSK WRDSK ST EXC S CPU CMD 1/1
3464 1.27s 1.70s 0K 0K 0K 0K -- - R 98% snort
3787 0.02s 0.00s 0K 0K 0K 0K -- - R 1% atop
1693 0.00s 0.00s 0K 0K 0K 0K -- - S 0% bgpd
106 0.00s 0.00s 0K 0K 0K 0K -- - S 0% bdi-default
3786 0.00s 0.00s 0K 0K 0K 0K -- - S 0% flush-8:0
予測はしていましたがかなり全体のパフォーマンスが落ちました。
まあ、それでも100Mbps以上の速度はあるので現在の環境なら問題ないですけどね。あとは見るパケットをもっと限定するとかチューンが必要だと思います。
---pfsense---
root@1:/home/owner# iperf -c 192.168.1.45 -i 1 -w 128K -t 30
------------------------------------------------------------
Client connecting to 192.168.1.45, TCP port 5001
TCP window size: 256 KByte (WARNING: requested 128 KByte)
------------------------------------------------------------
[ 3] local 192.168.1.22 port 47776 connected with 192.168.1.45 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 1.0 sec 75.9 MBytes 637 Mbits/sec
[ 3] 1.0- 2.0 sec 21.5 MBytes 180 Mbits/sec
[ 3] 2.0- 3.0 sec 23.3 MBytes 196 Mbits/sec
[ 3] 3.0- 4.0 sec 24.6 MBytes 206 Mbits/sec
[ 3] 4.0- 5.0 sec 28.6 MBytes 240 Mbits/sec
[ 3] 5.0- 6.0 sec 31.1 MBytes 261 Mbits/sec
[ 3] 6.0- 7.0 sec 34.5 MBytes 289 Mbits/sec
[ 3] 7.0- 8.0 sec 36.6 MBytes 307 Mbits/sec
[ 3] 8.0- 9.0 sec 40.7 MBytes 341 Mbits/sec
[ 3] 9.0-10.0 sec 46.5 MBytes 390 Mbits/sec
[ 3] 10.0-11.0 sec 37.9 MBytes 318 Mbits/sec
[ 3] 11.0-12.0 sec 43.9 MBytes 368 Mbits/sec
[ 3] 12.0-13.0 sec 48.3 MBytes 405 Mbits/sec
[ 3] 13.0-14.0 sec 50.9 MBytes 427 Mbits/sec
[ 3] 14.0-15.0 sec 53.8 MBytes 451 Mbits/sec
[ 3] 15.0-16.0 sec 54.6 MBytes 458 Mbits/sec
[ 3] 16.0-17.0 sec 55.5 MBytes 466 Mbits/sec
[ 3] 17.0-18.0 sec 55.3 MBytes 464 Mbits/sec
[ 3] 18.0-19.0 sec 54.4 MBytes 457 Mbits/sec
[ 3] 19.0-20.0 sec 55.8 MBytes 468 Mbits/sec
[ 3] 20.0-21.0 sec 54.0 MBytes 453 Mbits/sec
[ 3] 21.0-22.0 sec 22.6 MBytes 190 Mbits/sec
[ 3] 22.0-23.0 sec 27.2 MBytes 229 Mbits/sec
[ 3] 23.0-24.0 sec 29.5 MBytes 247 Mbits/sec
[ 3] 24.0-25.0 sec 32.9 MBytes 276 Mbits/sec
[ 3] 25.0-26.0 sec 35.8 MBytes 300 Mbits/sec
[ 3] 26.0-27.0 sec 38.0 MBytes 319 Mbits/sec
[ 3] 27.0-28.0 sec 39.9 MBytes 334 Mbits/sec
[ 3] 28.0-29.0 sec 41.7 MBytes 350 Mbits/sec
[ 3] 29.0-30.0 sec 44.5 MBytes 373 Mbits/sec
[ 3] 0.0-30.0 sec 1.21 GBytes 347 Mbits/sec
ブレが…
一応全てのルールは有効にしてあるのですがVyattaとは有効になってる状態が違う可能性があるので横並びの比較は出来ません。
このようにどの程度メモリを割り当てるかという設定によっても変わってくると思います。

Vyattaにもこれがあると思うんですが疲れたので誰かこれを変更したらどうなるかベンチとって教えてください(他力本願
IPSを有効にした状態でのAB
---snortvyatta AB---
root@1:/home/owner# ab -n 10000 -c 500 http://192.168.1.46/index.html
This is ApacheBench, Version 2.3 <$Revision: 655654 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Server Software: lighttpd/1.4.19
Server Hostname: 192.168.1.46
Server Port: 80
Document Path: /index.html
Document Length: 45 bytes
Concurrency Level: 500
Time taken for tests: 3.918 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 2780000 bytes
HTML transferred: 450000 bytes
Requests per second: 2552.52 [#/sec] (mean)
Time per request: 195.885 [ms] (mean)
Time per request: 0.392 [ms] (mean, across all concurrent requests)
Transfer rate: 692.97 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 55 383.0 12 3802
Processing: 0 13 23.6 12 244
Waiting: 0 13 23.6 12 244
Total: 1 68 385.3 24 3816
Percentage of the requests served within a certain time (ms)
50% 24
66% 24
75% 24
80% 24
90% 25
95% 28
98% 225
99% 3023
100% 3816 (longest request)
IPS無効時には0.6秒しかかからなかったのにIPSを有効にすると7倍近くかかるようになってしまいました。
L7まで見るIPSなので納得は出来ますが思いの外パフォーマンスの低下が大きいです。
ちなみにLogにはアタックログが残ります。AlertではなくてDropにしておけばそのIPはもうさよなライオンします。
vyatta@vyatta:~$ show ips log
================================================
IPS events logged since Sat Apr 2 19:15:19 2011
================================================
2011-04-02 19:16:51.218303 {TCP} 192.168.1.22:49146 -> 192.168.3.46:80
(bad-unknown) Potentially Bad Traffic (priority 2)
[129:5:1] stream5: Bad segment, overlap adjusted size less than/equal 0
---------------------------------------------------------------------------
2011-04-02 19:16:51.218316 {TCP} 192.168.1.22:49147 -> 192.168.3.46:80
(bad-unknown) Potentially Bad Traffic (priority 2)
[129:5:1] stream5: Bad segment, overlap adjusted size less than/equal 0
---------------------------------------------------------------------------
pfsense
root@1:/home/owner# ab -n 10000 -c 500 http://192.168.1.45/index.html
中略
Server Software: lighttpd/1.4.19
Server Hostname: 192.168.1.45
Server Port: 80
Document Path: /index.html
Document Length: 45 bytes
Concurrency Level: 500
Time taken for tests: 1.229 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 2787784 bytes
HTML transferred: 451260 bytes
Requests per second: 8139.71 [#/sec] (mean)
Time per request: 61.427 [ms] (mean)
Time per request: 0.123 [ms] (mean, across all concurrent requests)
Transfer rate: 2215.99 [Kbytes/sec] received
確かに遅くはなっていますが無効の時と大差ないですね
結論
古い環境や基礎的なルーティングだけあればいいなら Vyatta、パケットフィルタやその他諸々詰め込みたいならpfsenseを選ぶべき
という「んなこと常識だろ!」という結論が出ました。それにしてもVyattaの軽さは凄いと思いました。ゲームでレイテンシを出したくないらVyattaを使うのがいいのではないですかね。
反面、ごてごてしてるながらもやはりpfsenseは高性能でした。
またちょっとネットワーク環境を変えようと思っているので、そのときはpfsenseを本格的に使おうかなと思っています。
[ コメントを書く ] ( 2564 回表示 ) | このエントリーのURL |
昔にも似たようなことをやったので、前からこのブログを見てる人はなぜまた同じようなことを?と思うかもしれないですが、気になったことがあったのでまた検証してみました。今回は自分が気になったので調べた結果、というのがかなり強いので、いまさら役に立つかどうかは分からない上に冗長です。
そもそも何でこんなことをしようと思ったのかというと、サブサブマシンで使っていたMSIのP35-EFINITYでマルチモニタを構築するために使っていたx16を削ってx1にしたGeforce8400GSがやっぱり7のエアロを有効にするともたつくので、これを快適だと思えるレベルにするにはどの程度能力があればいいのかという点を調べるために始めたのです。
特に、1920*1200の画面を複数枚出していたり、リモートデスクトップを開いていると (特にRDP上でエアロを有効にしてる場合)パフォーマンスの低下が結構あります。
あと、この文章書いていて気がついたのですがFoobar2000などのスペアナを表示していてもなぜか重くなります。1680*1050のディスプレイ1枚のみしか出していないときはそれ程ひどい遅延はなかったのですが。
そしてついでだから前回検証しなかったPCI-Express Gen1とGen2でどの程度違うのかというのも検証してみました。実に2年半越しの再検証です。そろそろGen3が出ますが。
まあ、エアロの問題は前回のエントリにあるようにx16を2本持っているNF608iが手に入ったのでx16のGF9400とGF7600GTを使用することによって解決したのですが。
検証方法はグラボの端子をマスキングするという原始的な方法を使用してリンク速度を落とし、その状態で3Dmark06をまわし、どの程度のスコアが出るか測定します。
ベンチが終わったらエアロを一通りいじってみて反応を見ます。

ちなみにマスクの方法はこうです。当たり前ですが真似するときは自己責任でやってください。下手すると燃えるかもしれないですが燃えたとしても僕は知りません、

以前使ったので画像は残っていたのですが、元ページへのリンクが見つからなかったので知ってる人がいたら教えてください
構成 1 P45チップ@Gen2
M/B Biostar TP I45
CPU E5400@3.7GHz
mem Umax Pulser 4GB@900MHz
GPU leadtek Winfast PX8800GT(G92チップ版Gen2対応GF8800GT)
OS Win7x64
電源 Zippy P2G-6510P 510W

経験的に、CPUの速度を上げたほうがグラボの速度も上がり、PCI-Expressの帯域を有効に使えるのでCPUはOCしています。
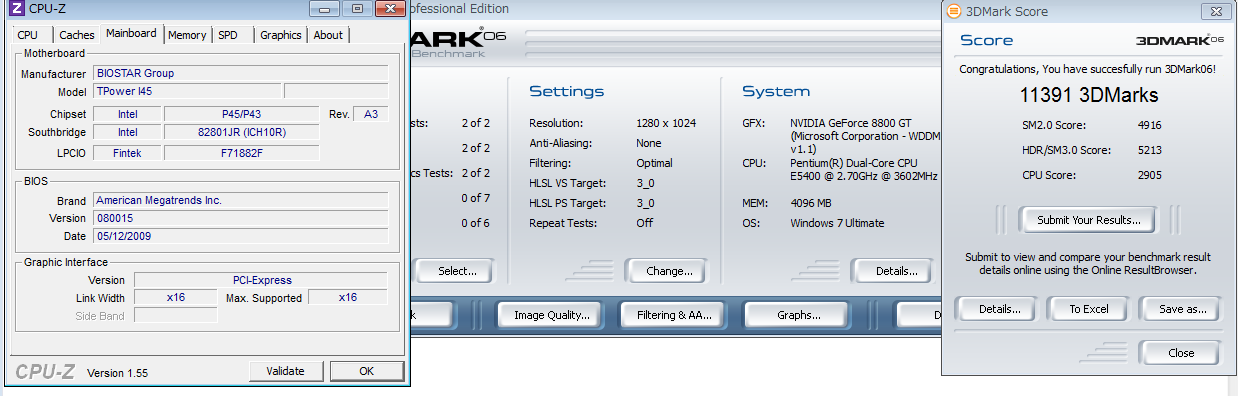
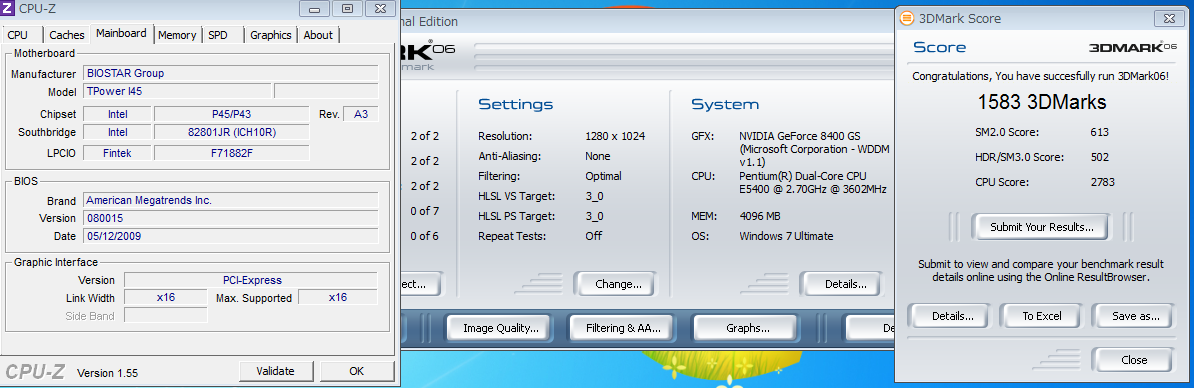
ちなみに、この構成でGF8400@x1を動かすとこんな速度になります。GF8400はGen1までの対応なのでどの板にさしても変わらないです。

これだとさすがにエアロは遅いというかもたつきが気になります。というかWin7から「グラフィックのパフォーマンスが低下してるのでエアロ切ることをお勧めします」といわれます。まあ、エアロ切ってもあんまり変わらなかったりするんですけどね。
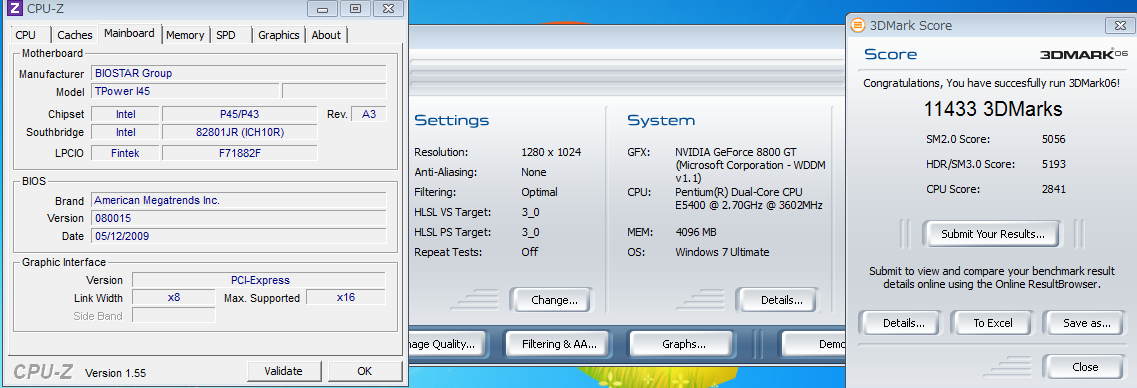
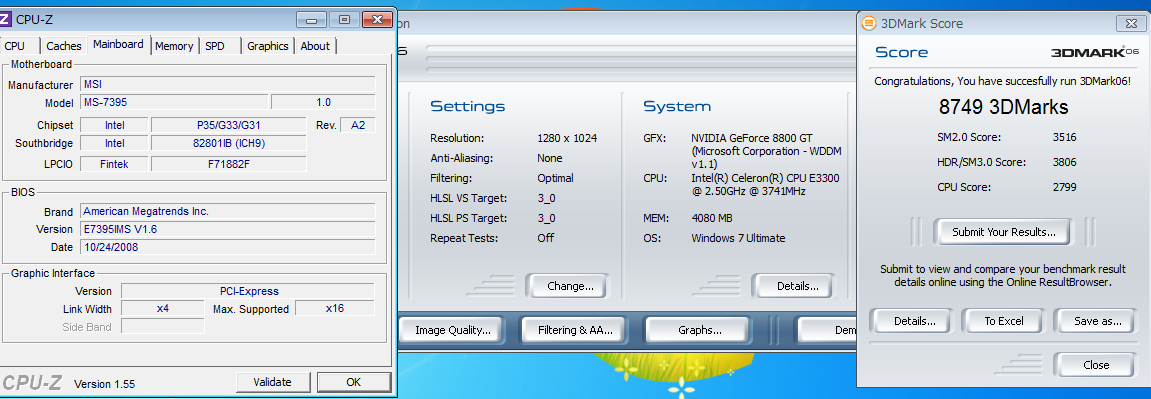
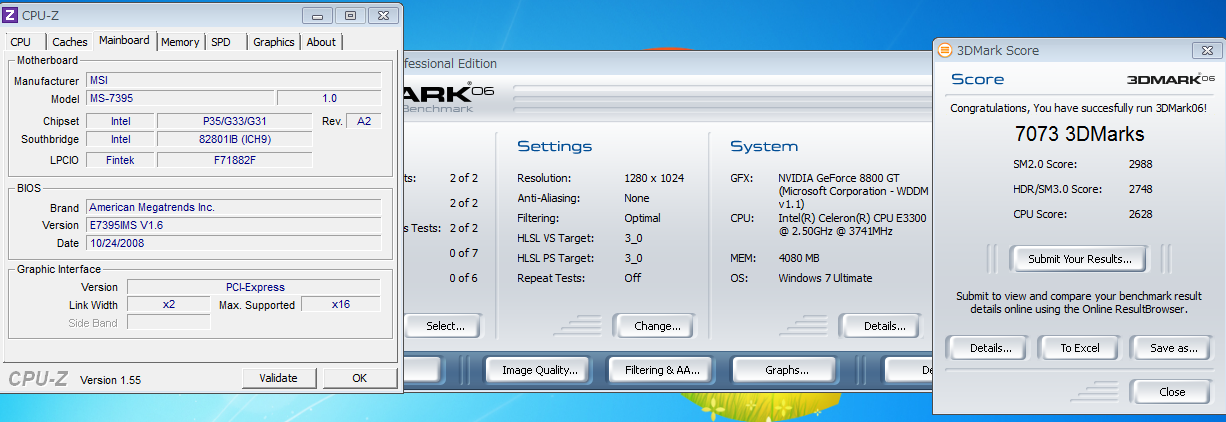
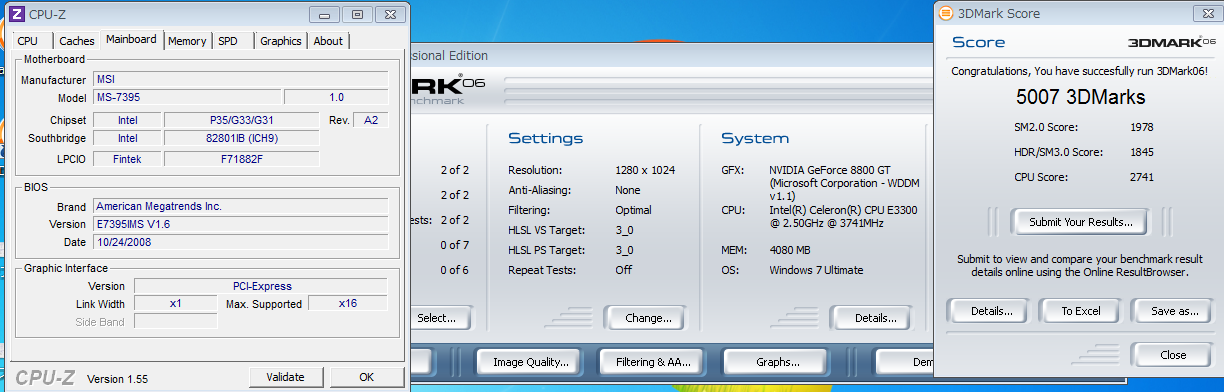
そしてGF88GTのスコア。
x16
x8
x4
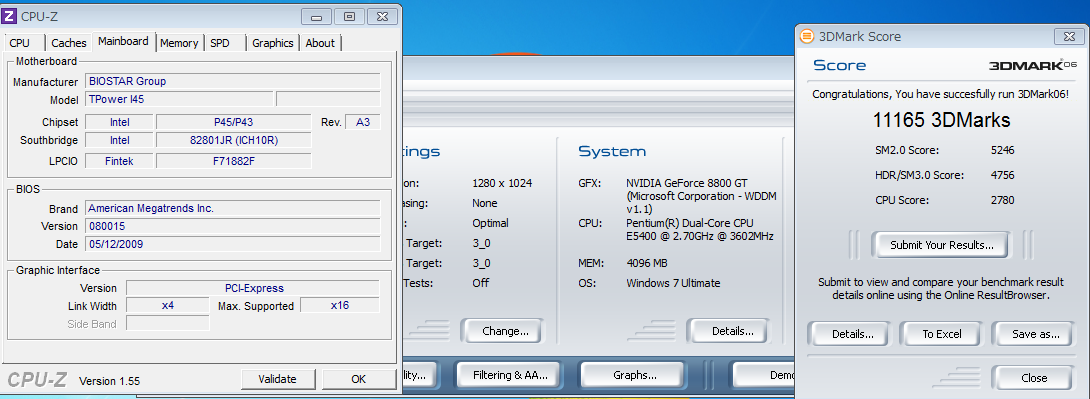
x1

いじった感想、ゲームをする分にもx4程度のリンク(Gen1のx8相当)とGF88GTクラスのグラボがあれば大丈夫だと思います。
驚いたのが、x1でのスコアです。前回では3-4000程度で頭打ちになっていたのですが、今回はそれの倍近く出ました。HW構成が変わっているとはいえ、こんなスコアが出るとは驚きでした。もちろんもたつき、遅延もありませんでした。
x1のグラボがこんなに速いわけがないと思い、ためしにOCを解除してまた
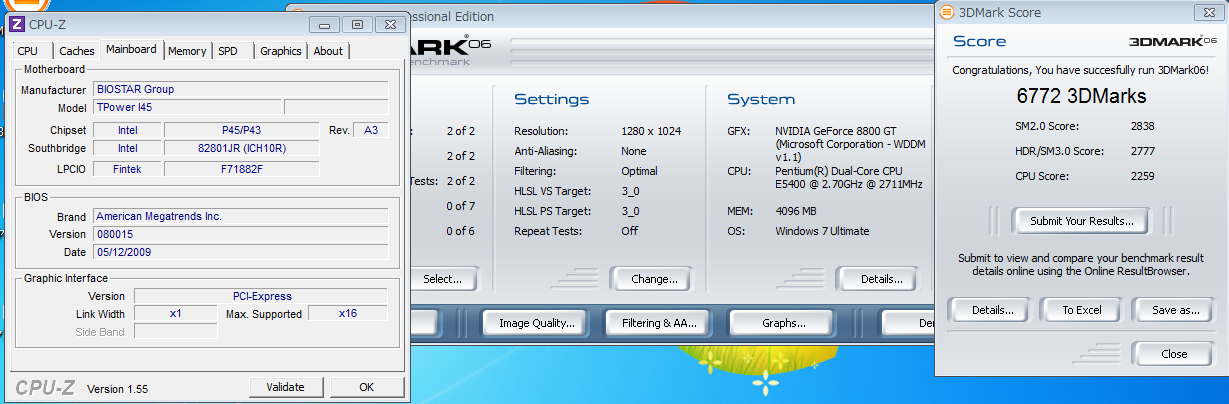
それでもやっぱり6000は出ています。前回の結果からするとこの結果は正直予想外でした。
これはすべての結果を出した後から気になってやったことなので時系列がずれますが、前回のテストに使ったGPUのワンランク上のHD3870でもx1でのスコアをサンプリングしてみました。

Gen2なので前回のx2相当になるので大体4-5000くらいになれば正しいのですが、やはり88GTと同じ程度になりました。
そうなると前回は何がボトルネックになっていたのかという話になるのですが、調べたところ前回使ったP5SD2-VMはSISチップセットを使っていてメモリアクセスがシングルチャンネルとのことだったので、、ためしにメモリをシングルチャンネルにしてCPUをCore2E6420と同じ266*8にして前回に近い状態にしてみました。

CPUとメモリアクセスがネックになっていたのは確かにありますが、それでも前回より成績がいいです。
原因を予想するなら、おそらくSiSのチップセットがNoobだったのでしょう。
今度は退役したP35でテストしてみます。どうでもいいですがEFINITYはメモリスロットの配色がチャンネルAとBで分けられているのが罠があります。他の板と同じように先に同じ色同士にさすとシ ングルチャンネル動作になるのでパフォーマンスが落ちます。分かる人なら気がつくかもしれませんが、自分はどっちの意味で色分けされているのか気になってマ ニュアルを読みました。紛らわしい。
本来なら石もそろえるべきだったのですが、バックパネルつきのCPUクーラーをはずすのはちょっと面倒だったので手元にあったE3300をOCしています。
まあ、L2のサイズが違うだけで殆ど両者で違いはないんですけどね。
構成2 P35チップ@Gen1
M/B MSI P35 Neo3-EFINITY
CPU E3300@3.7GHz
以下同上
ためしにGf8400のスコアを取ってみます。
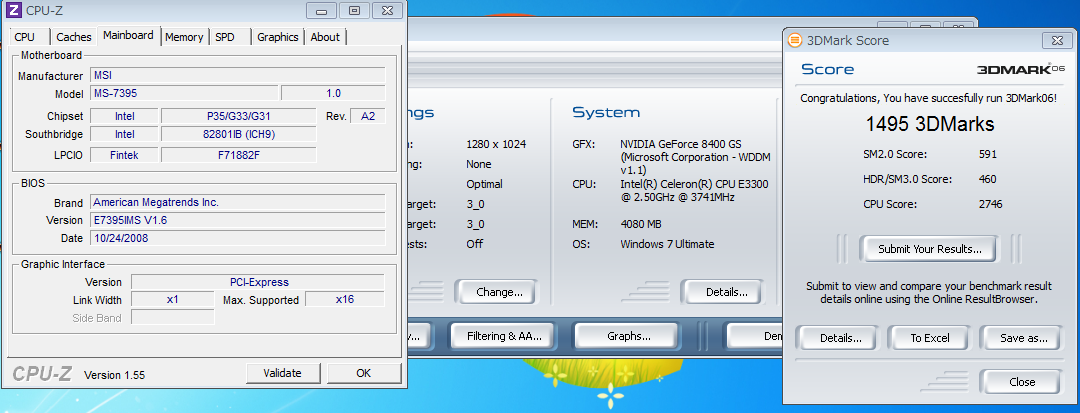
違うHW上でもCPUが若干遅いですが大体誤差の範囲ですね。
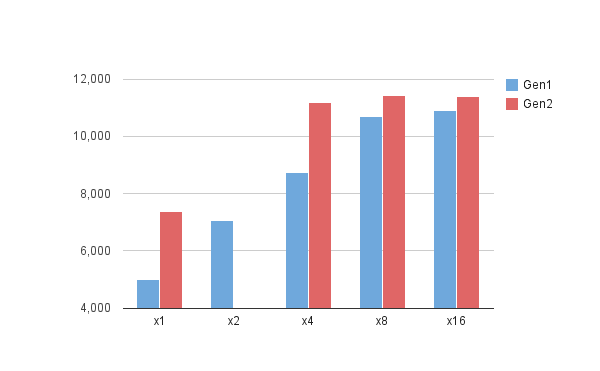
そして88GTのスコア。
x16

x8
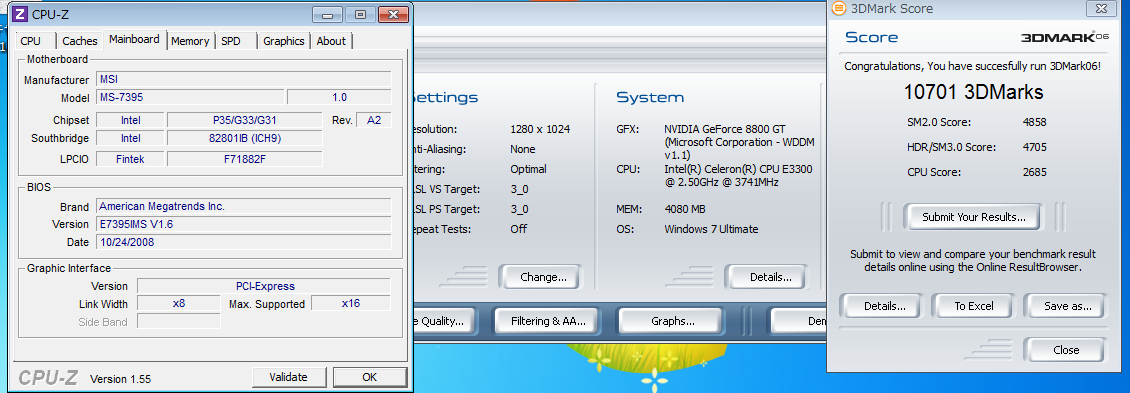
x4
x2
x1
Gen2では面倒だったのでやらなかったx2での速度もとってみました。
結果として、Gen2でのx1と同じくらいの速度になりました。それ以外の速度に関しても大体Gen2のリンク速度の1/2での速度という感じになったので、理論的には正しいかと思います。PCI-Eのデータ通信量をモニタするソフトを見つけられなかったので、実際どの程度のデータが流れているかは不明ですが、大体Gen1でもx8程度のリンク速度があればGF88GT程度(今で言うならGF GT440とかRadeon HD5670クラス?)ならグラボの限界近くまで引き出しているようです。
エアロのレスポンスのほうは、88GTだとGen1のx1でも快適に動きます。
実験の結果のとおり、88GTだとx1でも快適に動いてしまったので、それならどのクラスならこの環境でも満足に動くのか気になって試してみましたが、結論としてはGefoなら7600GT-7600GSクラスはほしいなと思いました。

8400GSでもx16であればまあ動くのですが、透過ウィンドウ(Teratermとか)を動かすとなるとこれくらいの能力はほしいです。
ちなみに8400GSはx16でもこの程度です。
ハードウェアの構成が書いていないので一概には言えませんが、一応近い値は出たのでこのページでいうところの3dmark3-4000はあったほうが快適に動くのではないかと思います。
まあ、そんなローエンドグラボいまどき市場になかなかないので、ゲームしないならほとんど気にしなくていいとも思いますが、"快適に高解像度ディスプレイを複数使うためにグラボを買いたいけど中古などで安く済ませたい"という人の目安にでもなればと思います。今ならGF210やらHD5450などが消費電力と性能的と価格的にもいいと思いますが。
まとめ
・エアロを高解像度で使いたいならゲームをしないにしてもある程度の性能はほしい(最低GF9400以上)
・低解像度モニタならべつにGF8400でもかまわない
・もともとの性能があれば(GF8600クラスとか)削ってx1にさしてもサブモニタとしては普通に動く
・Gen2 ならデュアルGPU(GTX295とかHD4870x2とか)や現行ハイエンドGPU以外ならx8でも十分なのでは?
・信頼のIntelチップセット
といったところですかね。そろそろ実験マシンの環境が古くなってきた感が強いですが、常時稼動しているわけでもない上に結構処理も速いので今のところ置き換える予定はないですね。というか古い資産がありすぎて逆に移行できないというジレンマ
おまけ


最初はHD4890を使おうと思ったのですが8ピンコネクタと6ピンコネクタを要求する上に、Zippy P2G-6510Pには6ピンコネクタがないので変換コネクタを合体しまくって使おうと思いましたが怖いのでやめました。一応12V一本から32A取れるので大丈夫だとは思うのですがさすがに燃やしたくはないのでw
予想外の結果や物理的な作業や3dmarkにかかる時間などを含めてかなり長い時間を使ってしましました
[ コメントを書く ] ( 1579 回表示 ) | このエントリーのURL |
不良だったメモリが帰ってきたので板に取り付けMemtest+を回している間にマザーの取説を読んでいたら気になる記述がありました
http://dlcdnet.asus.com/pub/ASUS/mb/soc ... ws_pro.zip

>DDR3-1600は各チャンネルにメモリ1枚としてサポートされます
今DDR3の1600を6枚使っているのですが、それはつまり…どういう事だってばよ!?
色々調べているうちにそれっぽいフォーラムを見つけました。
http://forums.extremeoverclocking.com/t308357.html
http://en.wikipedia.org/wiki/Bloomfield ... ocessor%29
The Core i7 has three memory channels, and the channel bandwidth can be selected by setting the memory multiplier. However, in early benchmarks, when the clock rate is set higher than a threshold (1333 for the 965XE) the processor will only access two memory channels simultaneously. A 965XE has higher memory throughput with 3xDDR3-1333 than with 3xDDR3-1600, and 2xDDR3-1600 has almost identical throughput to 3xDDR3-1333.[13
要するに規定以上の速度のメモリを取り付けると同時に2chしかアクセスしないって事ですかね?
探してもどうもそれっぽい解が見当たらないので色々試してみました
構成
M/B ASUS P6TWS-PRO
Mem GeIL GVP34GB1600C9DC@1656MHz
CPU Corei7 950@166*23MHz
手っ取り早くできるベンチとしてClystalMark2004 R3のMemoryの項を実行して結果を見てみました
まず1600-2Gを1枚で起動してみる

2Gだと正確な時間はとっていませんが起動にも若干の時間がかかりました。
4G
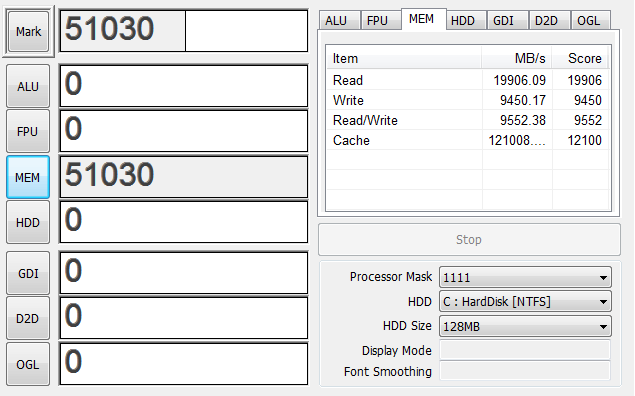
デュアルチャンネルが有効になったので速度が2倍近くになりました。
6G
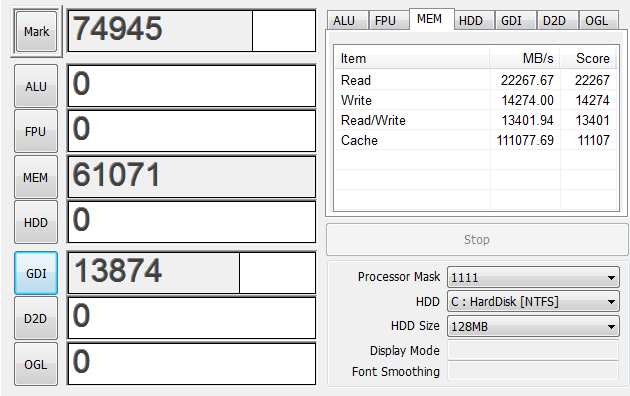
WriteとRead/Writeはシングルチャンネルの4555から14274まで増えたのでトリプルチャンネルは有効になっているようです
ここでもし中途半端な本数のメモリを刺したらどう動くのか気になったのでやってみました。
8G
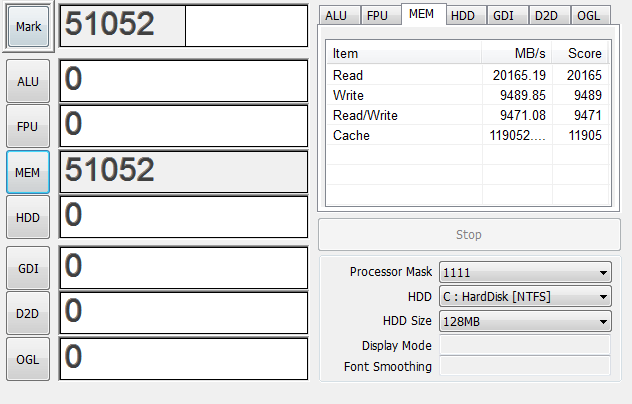
スコアとしてはデュアルチャンネルと同じ値になりました。これまでの板は4本でデュアルx2だったので納得できます。
しかし何故か表示上ではTripleChannelと表示されています。
ここでわかったのは
A B C ←バンク
010101 ←チャンネル
||||||←メモリスロット
111x1x
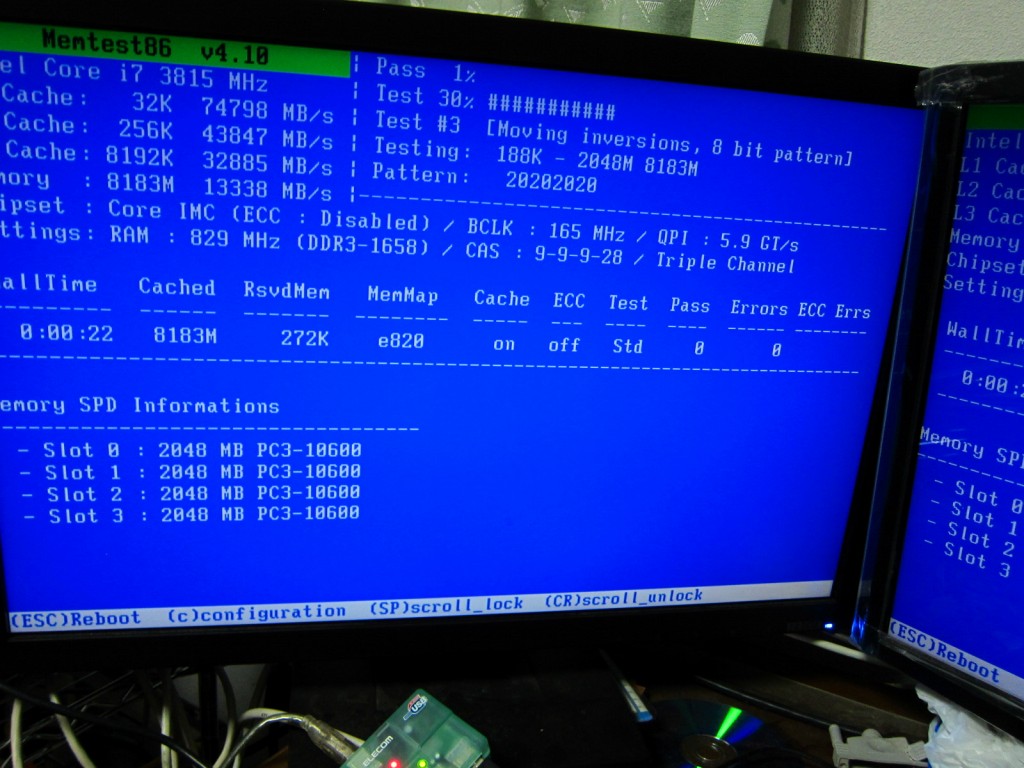
こう刺すとTripleChannelと表示され
||||||
1111xx
こうするとDualChannelと表示されますが、速度に差はないようです。
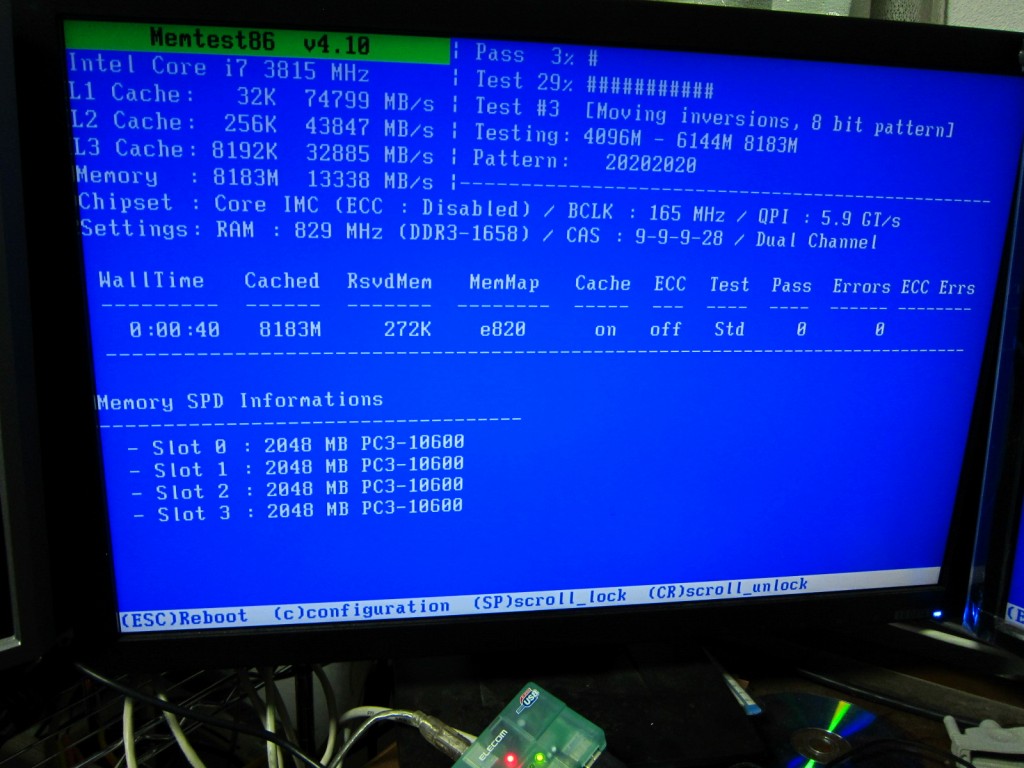
ちなみに
1x1xxx
こうだとデュアルですが
11xxxx
こうだとシングルチャンネルになります。原理を考えるともっともな動きですね。
あと、少なくともどこかのバンクのチャンネル0に1本はメモリが刺さっていないといけないようで
x1xxxx
x1x1xx
x1x1x1
これらではPOSTしませんでした。この辺の動きはメーカー依存な可能性が高いですが。
話を戻してデュアルともトリプルチャンネルとも言えない10Gで起動してみる。
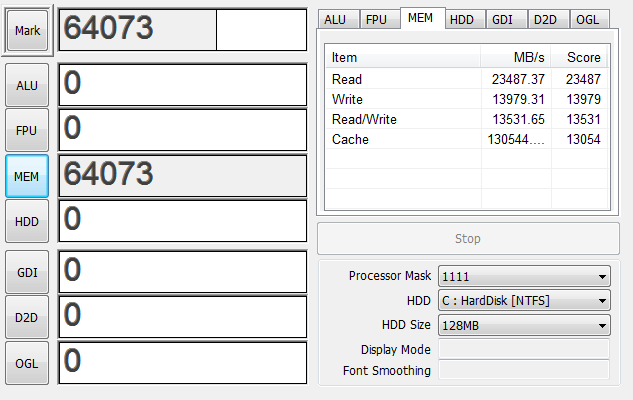
あれ…?速くなってる…?
もしかして先頭6Gがトリプルチャンネルで動いてケツ4Gがデュアルチャンネルで動いてる…?いやそんなキモイ動き許されるはずが…
仮想マシンを量産して9Gほど使った上でベンチを再度とってみる
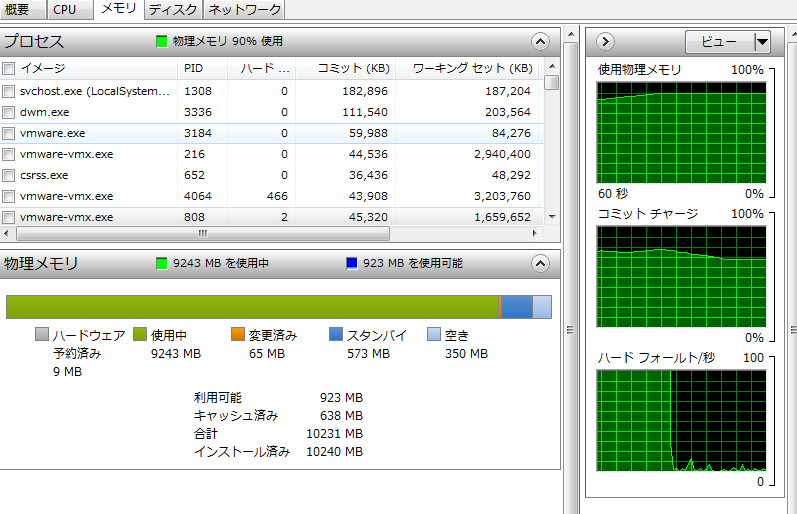
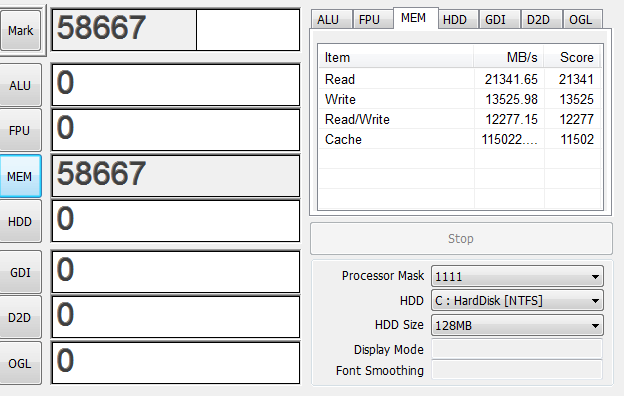
仮想マシンが動いてることを考えるとそこまで落ち込んでないですね
解せぬ
よくわからないので考察は後にして12Gで起動してみる
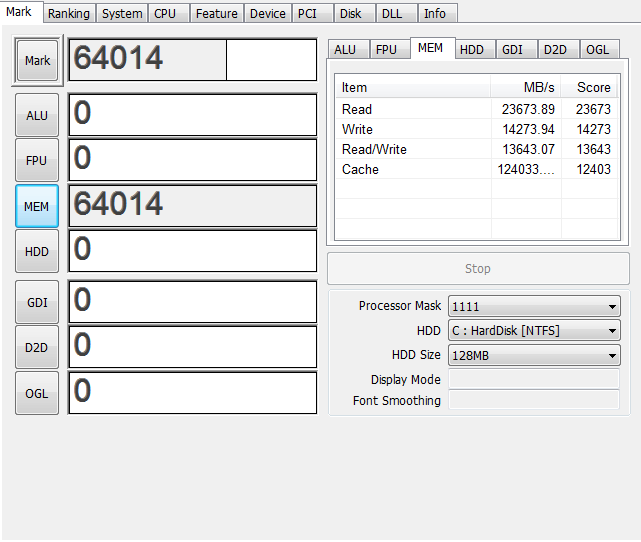
6Gの時とほぼ変わらないのでこれはトリプルチャンネルが働いてるって事でいいんですかね…?
まあ、動いてるしいいんじゃないかな
そして考えるのをやめた。
結論:メモリスロットが空いてるなら空いてるだけぶち込め
「そんな結論で大丈夫か?」
「大丈夫だ。問題ない」
[ コメントを書く ] ( 1506 回表示 ) | このエントリーのURL |
前回から「いかに速いファイル置き場を作るか」という目的を達成すべく色々実験してみました。そのせいで数字多いよ!
まずはUbuntu10で実験。
root@1:/# uname -a
Linux 1 2.6.32-24-server #39-Ubuntu SMP Wed Jul 28 06:21:40 UTC 2010 x86_64 GNU/Linux
マシンはいつものです。
product: TYAN-Toledo-i3210W-i3200R-S5220
product: Intel(R) Core(TM)2 Quad CPU @ 2.40GHz
MemTotal: 4048444 kB
特に断りがない限りファイルシステムはmkfs.ext4で作成。ベンチ方法は/dev/zeroからddで書き込み。今思ったらシーケンシャルW/Rしかみてないですね。
Bonnie++使うべきだったんじゃねと思うけど参考値程度に
RAID0
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid0 sde1[3] sdb1[2] sda1[1] sdc1[0]
156246528 blocks 256k chunks
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 15.351 s, 273 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 16.567 s, 253 MB/s
そのときの負荷
CPU | sys 41% | user 0% | irq 1% | idle 142% | wait 216% |
cpu | sys 29% | user 0% | irq 0% | idle 19% | cpu002 w 52% |
cpu | sys 12% | user 0% | irq 0% | idle 4% | cpu001 w 84% |
cpu | sys 1% | user 0% | irq 1% | idle 0% | cpu000 w 97% |
CPL | avg1 0.77 | avg5 0.89 | avg15 0.73 | csw 1684 | intr 3377 |
読み込み
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 15.1826 s, 276 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 16.7144 s, 251 MB/s
負荷
CPU | sys 20% | user 0% | irq 0% | idle 289% | wait 91% |
cpu | sys 14% | user 0% | irq 0% | idle 0% | cpu002 w 86% |
cpu | sys 4% | user 0% | irq 0% | idle 96% | cpu001 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
まずmdadmでRAID0ですが、RAID0はさすがに読み書き速いです。ちょっと古いドライブなので外周で読み書き70MB/sec程度なのですが、ドライブを追加すればそれだけリニアに速くなりました。
が、アレイの中の1ドライブでもFailしたらすべてのデータがさようならは怖すぎるので実用的ではないです
RAID1
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sde1[3] sdb1[2] sda1[1] sdc1[0]
39061376 blocks [4/4] [UUUU]
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 60.178 s, 69.7 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 62.0388 s, 67.6 MB/s
そのときの負荷
CPU | sys 23% | user 0% | irq 2% | idle 179% | wait 195% |
cpu | sys 1% | user 0% | irq 0% | idle 92% | cpu003 w 6% |
cpu | sys 4% | user 0% | irq 2% | idle 0% | cpu000 w 94% |
cpu | sys 12% | user 0% | irq 0% | idle 55% | cpu002 w 33% |
cpu | sys 5% | user 0% | irq 0% | idle 41% | cpu001 w 53% |
読み込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 62.0388 s, 67.6 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 63.6339 s, 65.9 MB/s
そのときの負荷
CPU | sys 7% | user 0% | irq 0% | idle 303% | wait 90% |
cpu | sys 5% | user 0% | irq 0% | idle 0% | cpu001 w 95% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu002 w 0% |
CPL | avg1 1.09 | avg5 1.32 | avg15 1.06 | csw 5471 | intr 3396 |
MEM | tot 3.9G | free 31.2M | cache 3.6G | buff 3.1M | slab 80.0M |
SWP | tot 0.0M | free 0.0M | | vmcom 402.1M | vmlim 1.9G |
PAG | scan 43008 | stall 0 | | swin 0 | swout 0 |
DSK | sdc | busy 88% | read 1289 | write 0 | avio 2 ms |
DSK | sda | busy 7% | read 100 | write 0 | avio 2 ms |
RAID1では1ドライブ分のスループットという予想通りな結果になりました。4ドライブ使っても読みの時は1ドライブしか仕事していないという。まあ冗長性に関しては最強だと思います
RAID5
md2 : active raid5 sde1[3] sdb1[2] sda1[1] sdc1[0]
117183744 blocks level 5, 256k chunk, algorithm 2 [4/4] [UUUU]
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 38.2853 s, 110 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 46.0981 s, 91.0 MB/s
そのときの負荷
CPU | sys 52% | user 0% | irq 3% | idle 257% | wait 88% |
cpu | sys 16% | user 0% | irq 0% | idle 77% | cpu002 w 8% |
cpu | sys 17% | user 0% | irq 0% | idle 81% | cpu001 w 3% |
cpu | sys 9% | user 0% | irq 3% | idle 33% | cpu000 w 55% |
cpu | sys 11% | user 0% | irq 0% | idle 65% | cpu003 w 24% |
読み込み
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 25.6145 s, 164 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 26.0037 s, 161 MB/s
負荷
CPU | sys 20% | user 0% | irq 0% | idle 289% | wait 91% |
cpu | sys 14% | user 0% | irq 0% | idle 0% | cpu002 w 86% |
cpu | sys 4% | user 0% | irq 0% | idle 96% | cpu001 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
RAID5ですが、正直もっと書き込みが遅くなると思っていたのにディスク単体より速くなりました。パリティー計算さえなければストライピングですからね。
というか下手なHWコントローラー使うよりCPUパワーでブン回した方が速いですね…。
リビルドは大体40Gのドライブを-fして-aすると15分くらいでした
RAID6
root@1:# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid6 sde1[3] sdb1[2] sdc1[1] sda1[0]
78122496 blocks level 6, 256k chunk, algorithm 2 [4/4] [UUUU]
書き込み
root@1:# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 55.1364 s, 76.1 MB/s
root@1:/home/owner# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 59.1087 s, 71.0 MB/s
負荷
CPU | sys 44% | user 0% | irq 1% | idle 249% | wait 107% |
cpu | sys 17% | user 0% | irq 0% | idle 80% | cpu002 w 3% |
cpu | sys 9% | user 0% | irq 0% | idle 9% | cpu000 w 81% |
cpu | sys 11% | user 0% | irq 0% | idle 86% | cpu003 w 3% |
cpu | sys 6% | user 0% | irq 0% | idle 72% | cpu001 w 22% |
読み込み
root@1:# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 29.0997 s, 144 MB/s
負荷
CPU | sys 12% | user 0% | irq 0% | idle 291% | wait 96% |
cpu | sys 3% | user 0% | irq 0% | idle 97% | cpu001 w 0% |
cpu | sys 8% | user 0% | irq 0% | idle 0% | cpu002 w 92% |
cpu | sys 0% | user 0% | irq 0% | idle 99% | cpu003 w 0% |
cpu | sys 0% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
冗長性
root@1:# mdadm -f /dev/md2 /dev/sdc1 /dev/sde1
mdadm: set /dev/sdc1 faulty in /dev/md2
mdadm: set /dev/sde1 faulty in /dev/md2
root@1:# mdadm -r /dev/md2 /dev/sdc1 /dev/sde1
mdadm: hot removed /dev/sdc1
mdadm: hot removed /dev/sde1
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid6 sdb1[2] sda1[0]
78122496 blocks level 6, 256k chunk, algorithm 2 [4/2] [U_U_]
適当に転送した50GくらいのファイルはSambaからロストしていませんでした。
違うドライブをFailにしてみる
root@1:# mdadm -a /dev/md2 /dev/sdc1 /dev/sde1
mdadm: re-added /dev/sdc1
mdadm: re-added /dev/sde1
ビルドが完了してから
root@1:/# mdadm -f /dev/md2 /dev/sdc1 /dev/sda1
mdadm: set /dev/sdc1 faulty in /dev/md2
mdadm: set /dev/sda1 faulty in /dev/md2
root@1:/# mdadm -r /dev/md2 /dev/sdc1 /dev/sda1
mdadm: hot removed /dev/sdc1
mdadm: hot removed /dev/sda1
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid6 sde1[3] sdb1[2]
78122496 blocks level 6, 256k chunk, algorithm 2 [4/2] [__UU]
これも残ってました。
しかし、読み込みはいいとして書き込みはやはり速度は落ちますね。単体よりは若干速いですが。
あとアレイの再計算と初期化に時間がかかりすぎます。40G*4ドライブ程度の容量でリビルドに30分。もし2T*4で組んだとしたら…
30 minute * 51.2(2T/40G) = 25.6 hour
( ゚д゚ )
しかもその間ドライブはリビルドで
DSK | sdc | busy 80% | read 538 | write 271 | avio 3 ms |
DSK | sde | busy 80% | read 534 | write 269 | avio 3 ms |
DSK | sdb | busy 37% | read 555 | write 142 | avio 1 ms |
DSK | sda | busy 35% | read 548 | write 130 | avio 1 ms |
というゴリゴリとアクセスしている状態。これが1日続いたらその間にほかのドライブが壊れてもおかしくないような…
RAID10
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 30.0364 s, 140 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 31.9872 s, 131 MB/s
負荷
PRC | sys 0.69s | user 0.02s | #proc 141 | #zombie 0 | #exit 0 |
CPU | sys 24% | user 0% | irq 3% | idle 212% | wait 161% |
cpu | sys 3% | user 0% | irq 0% | idle 97% | cpu003 w 0% |
cpu | sys 11% | user 0% | irq 3% | idle 2% | cpu002 w 84% |
cpu | sys 6% | user 0% | irq 0% | idle 84% | cpu001 w 10% |
cpu | sys 3% | user 0% | irq 0% | idle 40% | cpu000 w 57% |
読み込み
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 31.9915 s, 131 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 32.2236 s, 130 MB/s
負荷
CPU | sys 11% | user 0% | irq 1% | idle 294% | wait 95% |
cpu | sys 8% | user 0% | irq 0% | idle 0% | cpu002 w 92% |
cpu | sys 2% | user 0% | irq 1% | idle 97% | cpu003 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
スループットはほぼRAID1の時の2倍なのでもっともな動きだと思います。
ビルドにも10分程度。2Tで大体5時間程度?
気になったのがRAUD10でのデータの冗長性。理論でいえば2つのRAID1のアレイをストライプするので、データは
| MIRROR1 | MIRROR2 | ||
|---|---|---|---|
| sda | sdb | sdc | sdd |
| data1 | data1 | data2 | data2 |
| data3 | data3 | data4 | data4 |
| data5 | data5 | data6 | data6 |
こうなると思うのですが…。
と思ったら実際その通りだった
http://d.hatena.ne.jp/BlueSkyDetector/2 ... 1212936771
というかRAID10って2台で組むと読みをストライプするRAID1になるのw
http://www.togakushi.zyns.com/modules/w ... x.php?p=54
つまり、違うデータを持ったドライブが2台死ぬ分には大丈夫だけど、同じデータを持ったドライブが同時に2個死んだら終了という。
6台だと違うデータを持ったドライブなら同時に3台まで平気だけど、やっぱり同じデータを持ったドライブが2台死んだら終了ですね
4台以上でやるときに読みは2台でActiveとbackupになり、2台目には負荷が掛からないはずなので読みが多いところでは2台が同時に壊れる可能性は低いと思います。
しかし書き込みが多く入るような場所だと同じ負荷がすべてのドライブに掛かってしまうので同時に壊れる可能性は高いと思います
パフォーマンスは上がりますがRAID6のように「どのドライブでも2個壊れて平気」とはいかないので難しいところです。
mdadmではなくてIntel Rapid Storageではどう動くのか?というのも気になったのでちょっと試してみました。実験の合間合間のリビルドの時間を使って動画を作ってみました。
Get the Flash Player to see this player.
作業BGMに定評のあるKOKIA
結果を見ると
p0 p1 p2 p3
1 1 2 2
3 3 4 4
という感じでデータを持っているようです。Intel Rapid StorageでもRAID 10の動きは同じようです。
色々試したまとめ
ぶっちぎりたいならRAID0だけど物置には怖くて使えない
耐障害性を持たせるならRAID6がいいけどパフォーマンス(特に書きとリビルド)に問題あり
遅いと思ってたRAID5はCPUパワーがあれば速い。容量も一番効率よく使える。けど2台同時に死んだら問答無用で終了
パフォーマンスとある程度の耐障害性を持たせるならRAID10がいいけど、運悪く同じデータを持ったドライブが2個死んだら終了
この中だと個人的にはRAID10がいいんじゃないかなと思うのでこれを使う方向で考えてみます
[ コメントを書く ] ( 1824 回表示 ) | このエントリーのURL |
<<最初へ <戻る | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 進む> 最後へ>>