そのかわり、IntelからPCM Toolsというものがリリースされていて、これを使うとパフォーマンスカウンタでは見えない部分を見ることができます。ただし、プレビルドのものは配布されていないので自分でコンパイルする必要があります。
最初はVS2019でコンパイルしようとしたのですがthr/xthreadが存在しないためincludeできないと言われうまく行かず(たしかに探しても見つからない)、いろいろ試してもVS知識がなくてわからず、結局VS2017でコンパイルしたらうまくいきました。
自分用のメモとしてビルドのものを置いておきます。
PCM_201902 release.zip
ビルドするとpcm_*.exeという実行ファイルがいくつかできるのですが、有用だったのでいくつか紹介してみます。
PCI-Eの使用状況がわかるpcm-pcie
pcm-pcie.exeを実行すると以下のような出力があります。
.\pcm-pcie.exe
DEBUG: Setting Ctrl+C done.
Processor Counter Monitor: PCIe Bandwidth Monitoring Utility
This utility measures PCIe bandwidth in real-time
PCIe event definitions (each event counts as a transfer):
PCIe read events (PCI devices reading from memory - application writes to disk/network/PCIe device):
PCIePRd - PCIe UC read transfer (partial cache line)
PCIeRdCur* - PCIe read current transfer (full cache line)
On Haswell Server PCIeRdCur counts both full/partial cache lines
RFO* - Demand Data RFO
CRd* - Demand Code Read
DRd - Demand Data Read
PCIeNSWr - PCIe Non-snoop write transfer (partial cache line)
PCIe write events (PCI devices writing to memory - application reads from disk/network/PCIe device):
PCIeWiLF - PCIe Write transfer (non-allocating) (full cache line)
PCIeItoM - PCIe Write transfer (allocating) (full cache line)
PCIeNSWr - PCIe Non-snoop write transfer (partial cache line)
PCIeNSWrF - PCIe Non-snoop write transfer (full cache line)
ItoM - PCIe write full cache line
RFO - PCIe partial Write
CPU MMIO events (CPU reading/writing to PCIe devices):
PRd - MMIO Read [Haswell Server only] (Partial Cache Line)
WiL - MMIO Write (Full/Partial)
* - NOTE: Depending on the configuration of your BIOS, this tool may report '0' if the message
has not been selected.
Starting MSR service failed with error 2 Trying to load winring0.dll/winring0.sys driver...
Using winring0.dll/winring0.sys driver.
IBRS and IBPB supported : yes
STIBP supported : yes
Spec arch caps supported : no
Number of physical cores: 16
Number of logical cores: 32
Number of online logical cores: 32
Threads (logical cores) per physical core: 2
Num sockets: 2
Physical cores per socket: 8
Core PMU (perfmon) version: 3
Number of core PMU generic (programmable) counters: 4
Width of generic (programmable) counters: 48 bits
Number of core PMU fixed counters: 3
Width of fixed counters: 48 bits
Nominal core frequency: 3300000000 Hz
IBRS enabled in the kernel : no
STIBP enabled in the kernel : yes
Package thermal spec power: 130 Watt; Package minimum power: 68 Watt; Package maximum power: 200 Watt;
ERROR: QPI LL monitoring device (0:7f:8:2) is missing. The QPI statistics will be incomplete or missing.
ERROR: QPI LL monitoring device (0:7f:9:2) is missing. The QPI statistics will be incomplete or missing.
Socket 0: 1 memory controllers detected with total number of 4 channels. 0 QPI ports detected. 0 M2M (mesh to memory) blocks detected.
ERROR: QPI LL monitoring device (0:ff:8:2) is missing. The QPI statistics will be incomplete or missing.
ERROR: QPI LL monitoring device (0:ff:9:2) is missing. The QPI statistics will be incomplete or missing.
Socket 1: 1 memory controllers detected with total number of 4 channels. 0 QPI ports detected. 0 M2M (mesh to memory) blocks detected.
Detected Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz "Intel(r) microarchitecture codename Ivy Bridge-EP/EN/EX/Ivytown" stepping 4 microcode level 0x42c
Update every 1 seconds
delay_ms: 54
Skt | PCIeRdCur | PCIeNSRd | PCIeWiLF | PCIeItoM | PCIeNSWr | PCIeNSWrF
0 507 K 0 0 0 0 0
1 168 0 0 1080 0 0
-----------------------------------------------------------------------------------
* 507 K 0 0 1080 0 0
Skt | PCIeRdCur | PCIeNSRd | PCIeWiLF | PCIeItoM | PCIeNSWr | PCIeNSWrF
0 501 K 0 0 0 0 0
1 552 0 0 12 0 0
-----------------------------------------------------------------------------------
* 501 K 0 0 12 0 0
....
最初は各値が何を意味しているのかわかりませんでしたが、よく見ると実行すると最初に出力されるところに意味が書いてありました。気にするべきは PCIeRdCurとPCIeItoMで、PCIeRdCurはPCIE→ CPU/メインメモリへの読み取り(ホスト側から見て書き込み)で、 PCIeItoMはPCIE→CPU/メインメモリへの書き込み(ホスト側から見て読み込み)のようです。
例として、ソケット2配下のPCIEに接続されているnvme(U.2フォームファクタ)へのベンチマーク中にとった値は、CDMの読み込みで1719MB/sと出ましたがPCMの方では23Mとなりました。
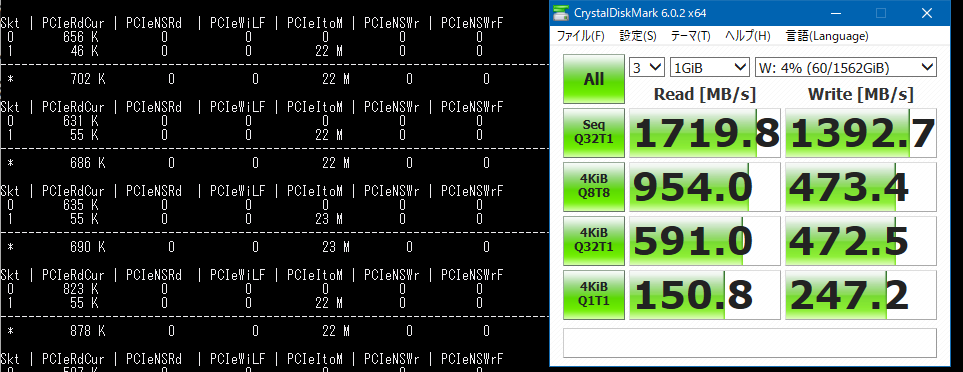
この23Mというのが何を意味しているかというと、1秒間に23M回要求があったということらしいです。これらからI/Oのサイズを求めると (1719.8 MB/s) / 23MHz となり、IOサイズは約74バイトという計算になります(計算はグーグル先生におまかせ)。
いろいろ調べると、PCI-EのパケットサイズはボードのTransaction Layer Packet (TLP)宣言によって16から4094バイト(2^4 -2^12) で送信できるらしいのですが、そうなると微妙に合いません。
逆に1719MB/sを64バイトで達成するには一秒間あたり26MHzの要求が必要になり、これもまた微妙に合いません。謎ですが、多分サンプリング間隔やCDMの帯域集計などのズレが有るのでしょう…。
また、別のケースとして(これも余ったから)使用している10GカードのConnectX2-ENから別の物理マシンへiperfしたところ、 8.25 GBytes (7.08 Gbits/sec)の速度が出たのですが、この際のpcm-pcieの値は以下のようでした。
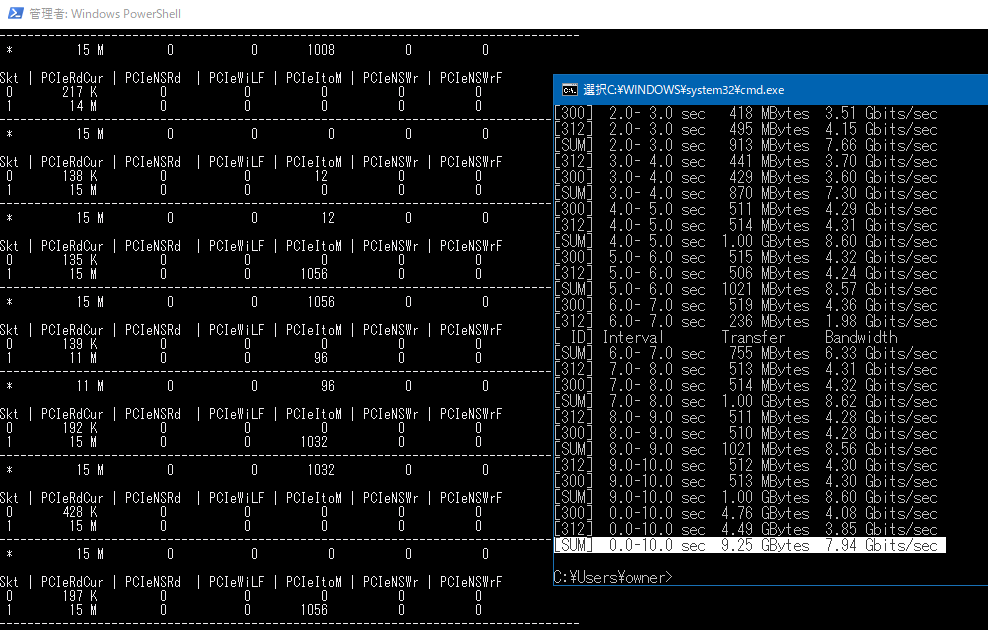
これに64バイトをかけると15MHz*64Byte=7680 Mbpsとなり、やはり近い値が出ているようです。
X9DAiのマニュアルによると、パケットサイズを256byte、ReadReqデータサイズは4kまで拡大できるらしいのですが、これを拡張しても特に要求回数が減ることはなかったので謎です。Linuxではlspciコマンドをvvvなどで実行すると出てくるDevCapがカード自体のケーパビリティ、DevCtlが実際にネゴシエートしている値として取得できるのですが、Windows上ではどのように動いているか不明です。逆にLinux上では64バイトという値はなかったので本当にこの計算があっているのか不安です…。
参考:
https://community.mellanox.com/s/article/understanding-pcie-configuration-for-maximum-performance#jive_content_id_PCIe_Max_Payload_Size
ちなみに、この確認の中で知ったのですが、X9DAiは各スロットでx16をx4x4x4x4などへ分割するPCIE Bifurcationに対応していたので、x16スロットにASUSのULTRA QUAD M.2 CARDのようなPLXのスイッチングチップを持たないnvme4枚刺しのカードを刺しても使えるようです。おそらくもともとはライザーカード対応のための機能だと思いますが…。
使用中のメモリ帯域がわかるpcm-memory.exe
このプログラムはなかなか有用で、チャンネルごとのメモリ帯域がわかります。
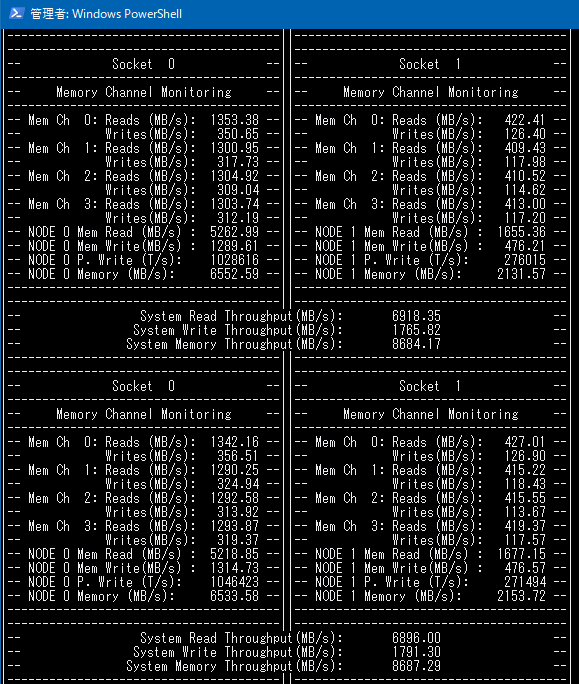
メモリ帯域のベンチマークを回すとシングルスレッドで12GB/s、4チャンネルあるのでマルチスレッドでコアあたり48GB/s、ソケット合計88GB/sという速度が出ましたが、ゲームをやっている限りせいぜい7-9GB/s程度の要求だったのでメモリ帯域についてはまだボトルネックではないということがわかりました。
メモリ帯域などをパフォーマンスモニターで見られるPCM-Service.exe
pcm-memory.exeをパフォーマンスモニターのグラフで見るためのサービスです。管理者権限でPCM-Service.exe -InstallでインストールするとProcessor Counter Monitor Serviceというサービスが追加され、これを開始するとパフォーマンスカウンターにPCM_*が追加されます。
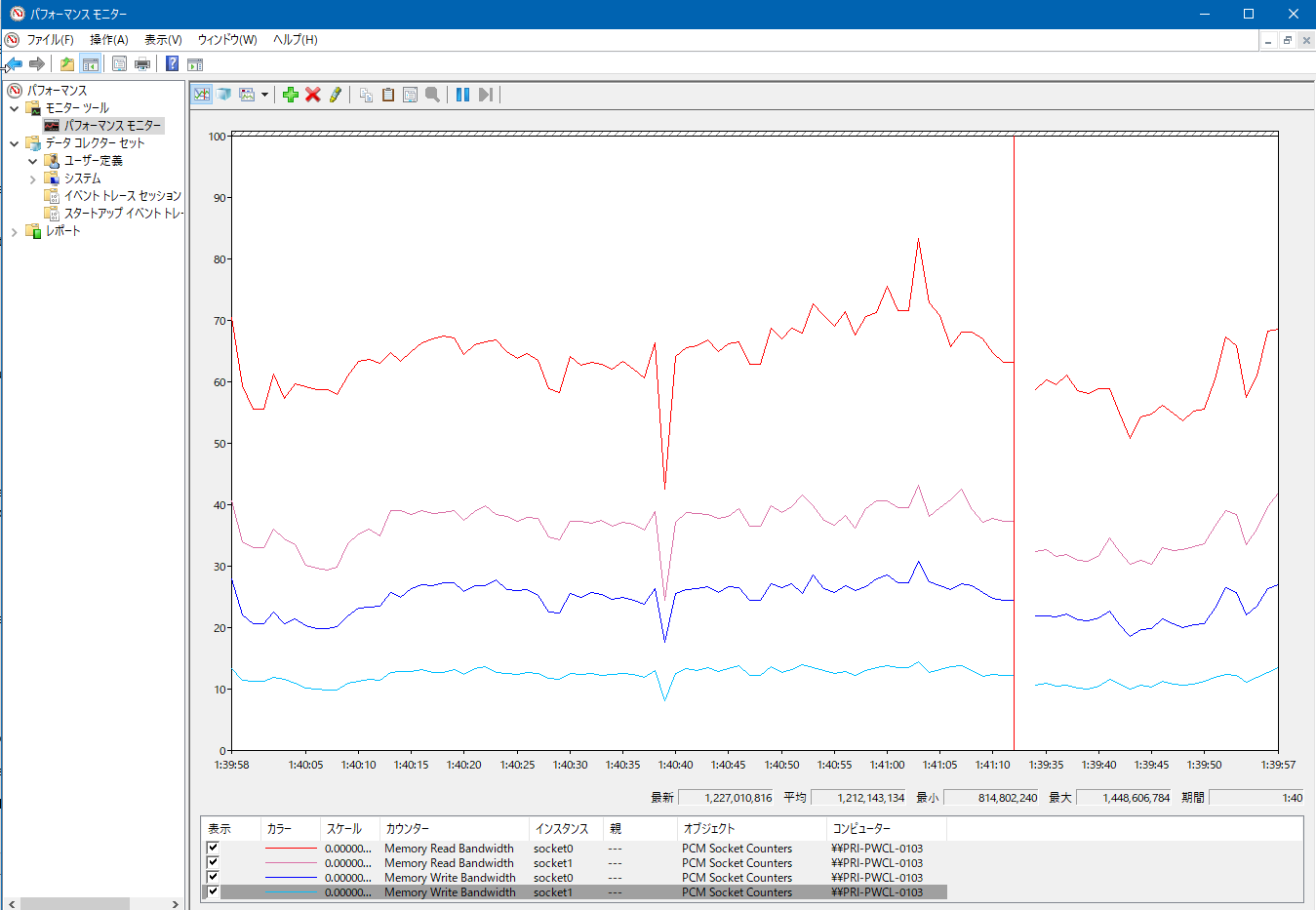
これらのパフォーマンスモニタリングから、最終的な結論としてXeon E5 2667v2は足回りはまだ余裕があるもののコアあたりの性能をあげないとゲームにおいてより良いパフォーマンスを得られないということがわかりました。感覚的にわかっていましたが…。
ただ、Zen2やCore i7系のCPUだと、使っているインターフェースカード的にPCIEのレーン数が足りないので、その点QPI跨いでしまってもレーン数の多いE5系は使いやすいんですよね…。
レガシーハードウェアが多いのでPCIE4.0を3.0にダウングレードしてそのかわりレーン数を倍にするスイッチングチップなどがあると嬉しいのですが、そんなニッチなものが売れるとは思えないですし、コスト的にも割に合わないと思うので厳しいです。Xeon Wシリーズがほしいのですが高い…。
人間は迷うと現状維持を選ぶらしいですが、今回もそうなりそうです。
[ 1 コメント ] ( 408 回表示 ) | このエントリーのURL |

家の環境は所有しているメモリの量の問題で未だにXeon E5 v2環境から移行できないのですが、同じラインのCPUを長く使っているとアップグレードや筐体目当てのパーツ取りなどでサーバを買ったりして余剰パーツが増えた結果、使ってない資材同士が結合して新しいマシンが生えてきたりすることはよくあることだと思います。(そして日常的にハードウェアを入れ替えてると配線の綺麗さとかどうでも良くなってきて写真のような配線になります)
そんなわけで、余ったパーツから生えてきたマシンを現在デスクトップ機として使っているのですが、2ソケットマシンをデスクトップ用途として使うとちょくちょくNUMAについて考えないといけない時があったのでまとめてみます。
環境
余ったパーツから生えてきたマシンは以下です。
マザボ X9DAi
CPU Xeon E5 2667v2 *2
メモリ DDR3 14900R 8*16 =128GB
グラボ GTX 1080
その他NVMeとか10G-NICとか
マザボについてはオークションで安かったので買ったのですが、サーバー用途で使おうとするとIPMIがないのはやっぱり使いにくいので結局本番稼働することなく部屋の隅に積まれていいました。
しかし、Core i5 6600Kでマシンを組んだときに微妙に物足りなかったので、試しにX9DAiと余り物でデスクトップ環境を作ったらいい感じだったのでそのままこれを使っています。
この環境を使っていても9割のことは困らないのですが、ゲーム時にパフォーマンスがばらつく時があったので、その対処法のメモです。
システムブロック図
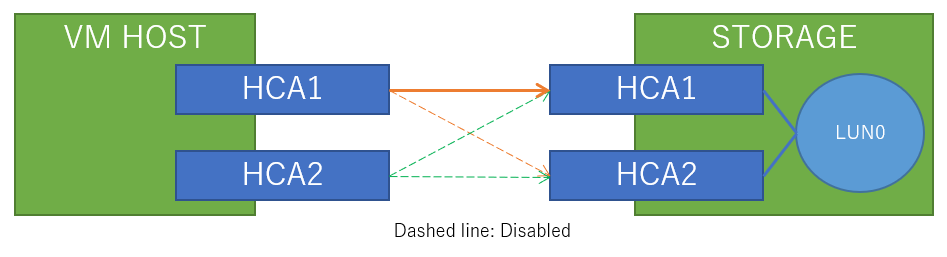
Xeon E5系/Ryzenから先はPCI-EがCPU直結になり、(AMD系ではThreadripper/Epicは)拡張スロットによって接続先のCPUが違う(AMDの場合はMCMのコアが違う)というのはパソコンオタクには常識だと思いますが、X9DAiのシステムブロック図は以下のようになっています。
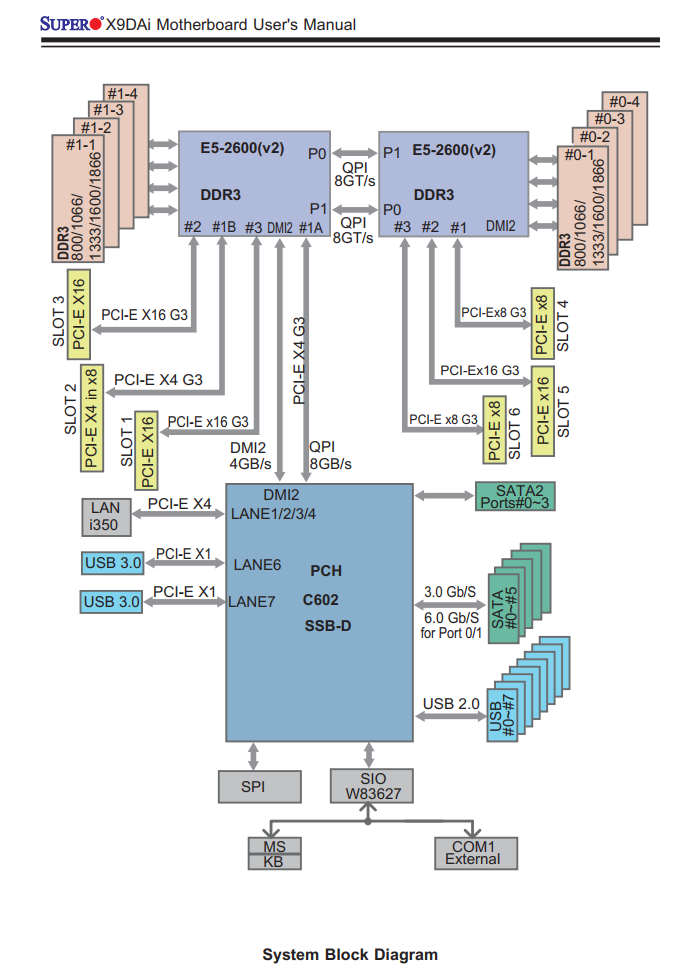
このことを意識してゲーム用GPUをCPU1に直結しているSlot1のPCIEx16に接続していたのですが、Windows/Linuxどちらであっても「実行するプロセスの使用する拡張ボードを考慮して」のNUMAの制御は今の所できません。
そのため、CPUの混み具合によっては「本来ならCPU1で実行してほしいのにCPU2で実行されてしまって拡張ボードにアクセスするにはQPI/Infinifablicを跨いでCPU1経由でアクセスしなければならない」ということが起きます。
Xeon 5600系まではどちらのCPUであってもPCH経由でPCI-EにアクセスしていたのでどちらのCPUもどのボードに同じコストでアクセスできたのですが、QPIの限界が来てしまったのでCPUに直結された結果、このような微妙に不便なことが起きます。
Windows10でのNUMA
Windows10でもNUMAを意識してくれるのですが、だいたい重要なプロセスがCPU1で実行されるため、ゲームなどは空いていることが多いCPU2で実行されてしまいます。しかし、そうなってしまうとGPUからは遠くなってしまうので、できればCPU1側で実行してもらいたいのです。
見ている限りだと、CPU1とCPU2両方をフルに使って実行されるゲームはなく、すべてのコアで実行を許可しても、どちらかのCPUのすべてのコアのみで実行されていました。
CPU affinity
もともとはNUMAの出始めの頃のサーバープロセスやDBプロセスのパフォーマンスチューニング手段でしたが、現在でも40GbE/100GbEなどの広帯域インターフェースを使う際にインターフェースに近いCPUでの実行を強制するために有効です。
ちなみに、現在のOSは賢いので極端なプロセスでなければ設定しなくてもNUMAノードのCPUやメモリの空き状況を見て、余裕がある方によしなにNUMAをまたがないようにプロセスを振り分けてくれます。
ゲームプロセスにCPU affinityをかけたい
プロセスのアフィニティー自体はタスクマネージャーの詳細の中にある「関係の設定」より簡単にかけることができるのですが、ゲームプロセスなどの場合、チート防止などの理由により起動後にアフィニティーを変えることができないことが多々あります。
その場合どうすればいいかと実験したところ、アフィニティーがかかったプロセスから子プロセスを実行するとアフィニティーが伝搬するので、steamなどを
start /affinity ffff steam.exe
で呼び出し、その伝播したSteamから更にゲームを実行すると最初からアフィニティーがかかった状態でゲームを開始できるようです。
しかし、これでうまくいくものもあればメニューの変なところで止まるものもあったため、結局Steamにアフィニティーをかけるのはやめました。
CPU2を混雑させたい
ゲームにアフィニティーをかけるのが問題であれば、自動選出の結果CPU1が優先的に選ばれるようにしたいので、逆にゲームに関係しないどうでもいいプロセスをCPU2側で実行させて意図的にCPU2を混雑させることにしました。
十進数でアフィニティーを確認する
このあとのPowershellでまとめてアフィニティーを設定したいので、まずnotepadなどを起動し、タスクマネージャーからCPU2を使うように手動でチェックを入れ、アフィニティーを設定します。
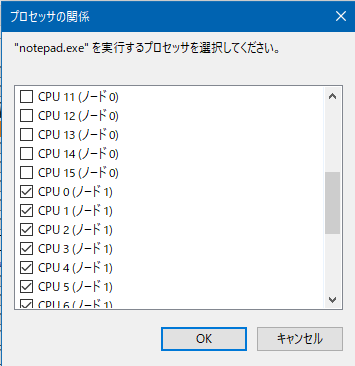
CPU2(ノード1)側をすべて使用するように設定したら、PowerShellでアフィニティーの値を取得します。もちろん関数電卓で直接やってもいいのですが、間違うことがあるのでこの方法が楽です。
PS W:\> Get-Process notepad|Select ProcessorAffinity
ProcessorAffinity
-----------------
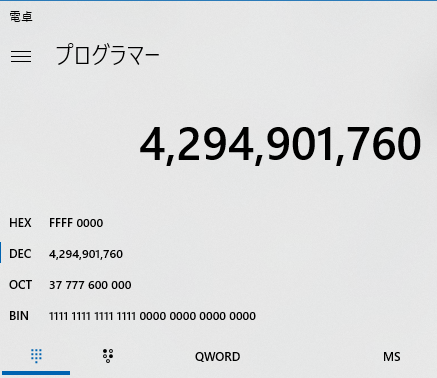
4294901760
4294901760というのは32スレッドのうち、奥の16スレッドを使用するという定義で、関数電卓に入れバイナリ値を見るとわかりやすいです。
ちなみに、PowerShellだとアフィニティーの指定は10進数ですが、start /affinityだと16進数になるので、古くからあるstartコマンドで同じことをしようとすると
start /affinity ffff0000 otepad.exe
になります。
邪魔なものをどかす
これから実行するプロセスをすべて特定のアフィニティーをかけて実行したい場合、まずcmd.exeをアフィニティーかけた状態で立ち上げ、一度explorerを taskkill /im explorer.exe /fなどで殺したあと、explorerと実行するとcmd.exeにかかっていたアフィニティーでデスクトップ環境が立ち上がります。
そのエクスプローラから実行されたプロセスもアフィニティーが伝搬していくので、デスクトップのアイコン等をクリックして実行してもアフィニティーがかかった状態で実行されていきます。
停止できないプロセスについては、管理者権限で実行したpowershellで
foreach($p in "SearchIndexer","OfficeClickToRun","sqlservr","sqlwriter"){ ForEach($PROCESS in GET-PROCESS $p) { $PROCESS.ProcessorAffinity=4294901760} }
などと実行するとアフィニティーをまとめて変更できます。ただ、svchostやdwmなどはアフィニティーをかけるとOSが不安定になることがあるので、変更しないほうが良いようです。また、CrystalDiskMarkなどもアフィニティーがかかっている状態だと正しく実行できませんでした。
また、どのコアでどのプロセスが暴れているかを見つけるには Process Explorer を使うといい感じに見つけられます。
大体の場合、ブラウザ(ChromeやFirefoxなど)をCPU2側で実行しておけば(特にマシンをシャットダウンせずに放置するような環境の場合)メモリ使用量などの関係で「CPU2は混んでいる」となるようです。
ゲームを実行してみる
アフィニティーのかかっていない状態のSteamなどからゲームを起動します。その後、CPU1側が優先的に使われるようになったら成功です。
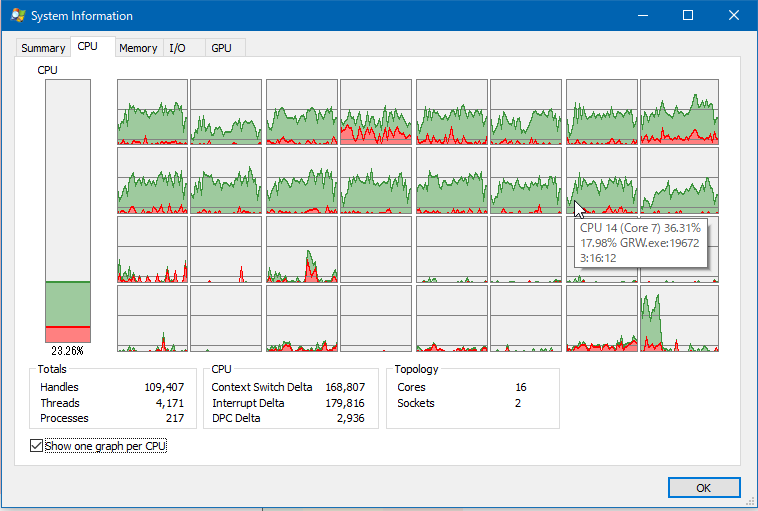
それでもまだCPU2が使われる場合はCPU2のしばきが足りないのでいろいろ実行してください。
CPU2側でゲームを実行されると、特にオープンフィールドなゲームでマップが広くメモリ使用量が多いゲーム(GRWとかArkとか)を実行すると、CPU2側からQPI越しにGPUになんか転送してるんだろうなというような一瞬のフリーズが起こることがちょくちょくありました。しかし、CPU1側で実行を強制するとそれがだいぶ軽減されました。
また、ブラウザをCPU2側で実行するとどれだけブラウザが重くなってもゲームに影響しないので、それはそれで2ソケットの使い分けとして便利な気がします。
そもそもXeonはゲームするようなプロセッサではないというのは尤もですが…。
マシンを新しくしようかどうか悩むところです。
[ 2 コメント ] ( 1742 回表示 ) | このエントリーのURL |
前回のエントリでHCAより先にPCI-Eの帯域が限界に来ていたことに気がついたので、HCAを2枚使ったらどうなるかをテストしてみました。今までDualportでもまあこんな速度かと思っていたのですが、よくよく考えたらPCI-Eがネックになっていたという…。SRP自体使い始めてからかれこれ5年ほど経過しますが、ほぼ情報がない(≒誰ももう使ってない)ので悲しみと今後iSERを使ったときの比較用のメモとして残します。
セットアップ
テスト環境はこんな感じです。

ストレージサーバ RX300S7
CPU Xeon E5 2643*1
Mem 8GB*8 at DDR3 1600MHz
Drive SanDisk Optimus Ascend 800GB *10 /RAID5 for Data (PN:LN0800FEHDC)
RAID HBA D3116C (MegaRAID SAS 2208@PCI-E 3.0)
IB HCA MT26428 (Connect-X2 VPI Single Port QDR) *2@PCI-E 2.0
Target SCST Version 3.4.0 from git repo
LIOでもSRPターゲットを作れますが、負荷が1つのコアに集中する、たまに刺さる、認証なしのターゲットが作れないといったことを経験したのでSCSTを使っています。SCSTは非常に安定していて、3-4年位使っていますが問題ありません。ストレージ側の設定はこんな感じです。
# cat /etc/scst.conf
HANDLER vdisk_fileio {
DEVICE dev-srp0 {
filename /vdisk/srp0.img
}
}
TARGET_DRIVER copy_manager {
TARGET copy_manager_tgt {
LUN 0 dev-srp0
}
}
TARGET_DRIVER ib_srpt {
enabled 1
TARGET fe80:0000:0000:0000:0002:c903:000f:41a7 {
enabled 1
rel_tgt_id 1
LUN 0 dev-srp0
}
TARGET fe80:0000:0000:0000:0002:c903:000f:8395 {
enabled 1
rel_tgt_id 2
LUN 0 dev-srp0
}
}
仮想ホストの環境は以下です。SRPを使う手順はこちらを参考にしてください。
DL380p gen8 ESXi 6.5

CPU Xeon E5 2667v2 *2
Mem 16GB*16 at 1333MHz
IB HCA MT26428*2 (Connect-X2 VPI Single Port QDR)
仮想マシン
Windows 10 x64 Pro 1809
vCPU 4
Mem 6GB
ベンチマーク用のディスクには準仮想化SCSIコントローラーを使
この状態で、ディスクへのパスを切り替えてテストします。 テストには最初 IO Meterを使おうと思ったのですが、パラメーターによって大きく値が変わってしまうので再現性のあるCrystalDiskMark6.0を使用しました。
ストレージ接続*1本
まずは、1ポート接続でテストします。
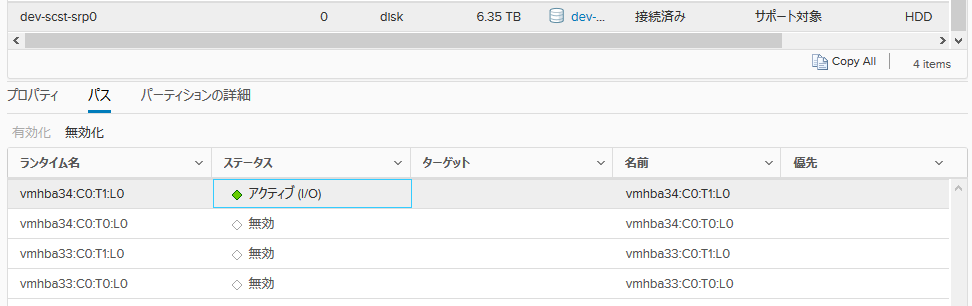
接続図はこんな感じです(途中のIBスイッチは省略)
その結果が以下です。
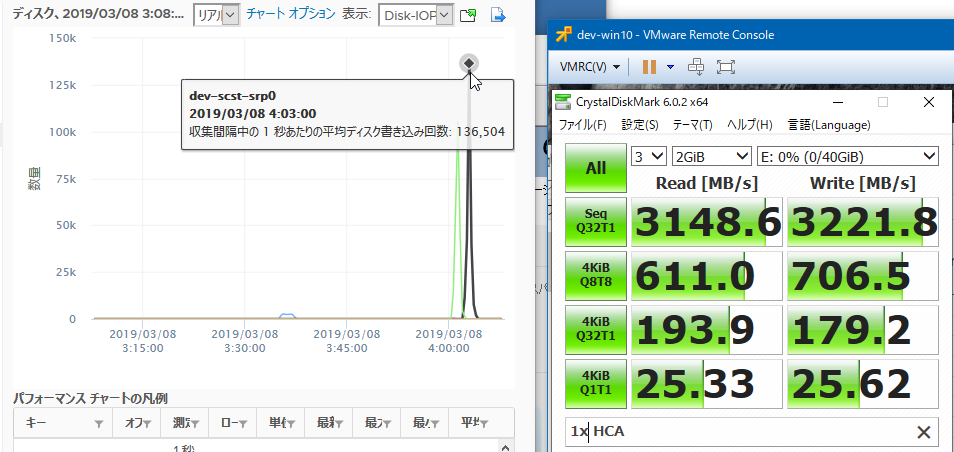
読み、書きともに120-130kIOPSで、帯域は3148MB/sでした。
ストレージ接続*2本
次に、接続を増やしてテストします。ラウンドロビンの切り替えは1IOごとに行う設定にします。
esxcli storage nmp satp rule add -R gsan -s VMW_SATP_DEFAULT_AA -P VMW_PSP_RR -O iops=1
設定ははこうなります。
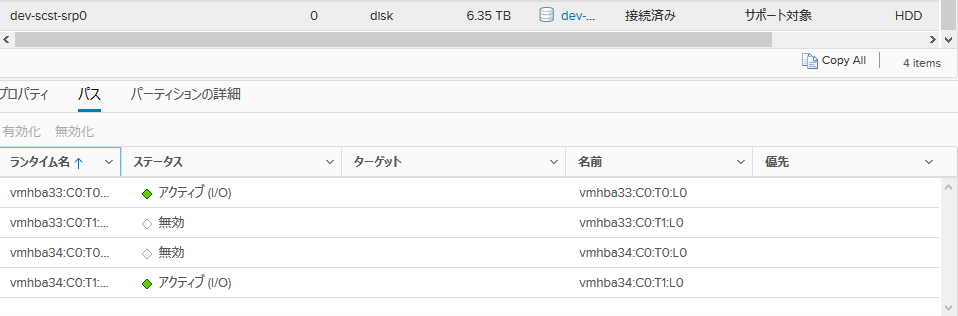
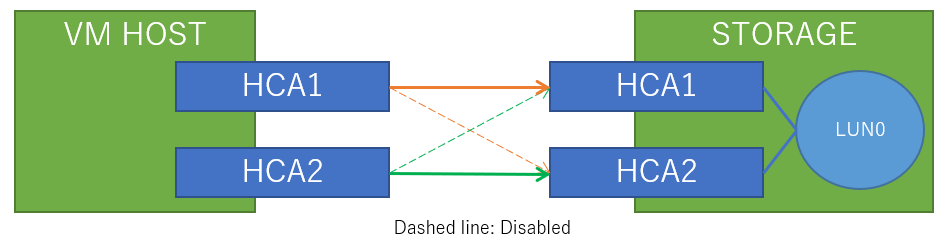
接続図はこんな感じです(途中のIBスイッチは省略)
その結果です。
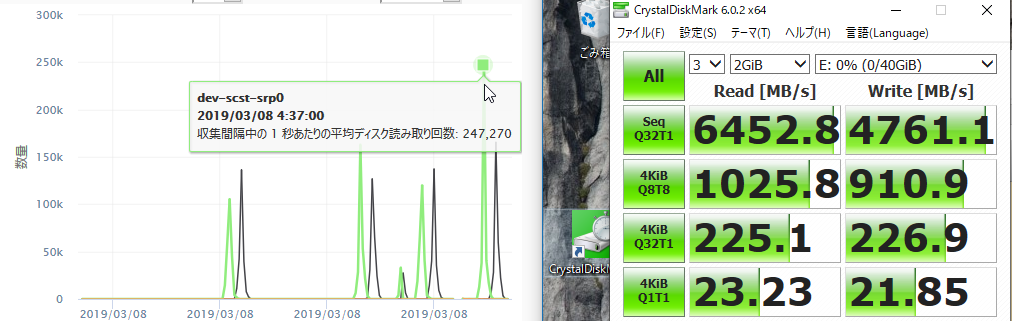
読み込み250kIOPS、書き込み150kIOPS出ました。また、帯域は読み込みに関してはきれいに2倍にスケールしました。いくらほぼストレージサーバのRAMへの読み書きとはいえ、びっくりするほど速いです。こんな速かったのか…。
また、読み込み250kIOPS時のストレージサーバの負荷はこんな感じでした。
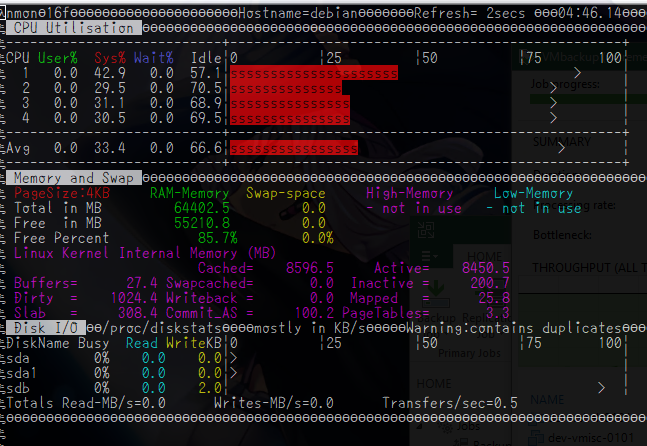
何かのエージェントで監視しているわけではなくnmonで見ていましたが、これより大きく外れることはありませんでした。
まとめ
SRPはもはや旧世代なハードウェア、かつ4コアという、今となっては非力な環境でもかなりの性能を発揮できました。もちろん、搭載しているRAMがちょっと多いのでDirtyやキャッシュの助けもありますが、nvmeのような高速なストレージを使ってもSRPはネックにならないというのはかなり強いです。
とはいえ、これを目当てに今からInfinibandを入れるのは、サポートの切れたConnect-X2からCX3世代をサポートの切れたドライバで動かすという、あまりにも将来性がない構成になるのでおすすめしません。
iSERは試したことがありませんが、原理としては同じなので今からやるならせめて40GbEのiSERでしょうか。100GのiSER環境も試してみたいのでどこかにスイッチとNICが転がってないかなと思う日々です。
早くこれよりも超高速なストレージを見つけて将来性のあるモダンな構成に移行したい…
[ コメントを書く ] ( 775 回表示 ) | このエントリーのURL |
家で仮想化基盤を扱っていると、どうしてもネックになりがちなのがストレージです。特にWindows環境での検証やVDIのテストをしていると、どうしてもIOが多いのでストレージがネックになり、あまりに遅いと作業のやる気が失せてしまいます。
このIOが遅いというのが嫌で仕方がないので、家で使えるレベルでの最速のストレージを求めて今までいろいろなことを試してきましたが、そのあれこれを雑然と書きたくなったので書いてみます。あくまでも家で使うレベルの話であり、業務でやるなら各ベンダから出ているオールフラッシュストレージをサポート付きで購入してください。
階層化ストレージ
今でこそSSDは容量も増え価格も下がりましたが、2017年位までは500GB以上のSSDとなるとなかなかの価格でした。そのため、それまではHDDのみの構成でしたが、128GB-256GBが手頃になり始めた2016年位に階層化ストレージとしEnhance-IOを入れてみました。ただ、メインストレージには日々(使用領域をほぼ舐める)バックアップが入ってしまうため、サイズの小さいキャッシュだとHOTなデータが流れてしまう事が多く、ヒットレシオは30%くらいでした。

その後、ES3000v2というエンタープライズなPCI-E SSDが数枚手に入ったのでこれを VMware上の仮想マシンクローニングを高速化するためにライトバックキャッシュにしたかったのですが、ライトバックキャッシュとして使おうとするとhioドライバ (Fusion IOのドライバ名を真似している)の上がってくるタイミングとudevがenhance-ioのキャッシュセットを組み立てるタイミング、fstabをもとにOSがディスクをマウントするタイミングなどが合わず、ライトバックキャッシュとして使うとファイルシステムが壊れるという事態が起きました。

また、常にFPGAを全力で動かすことによりレイテンシを削減しているため、省電力機能といったものがなくカード自体が非常に発熱します。拡張カード周辺はかなり強い風量で空気を循環させないと、複数枚刺したときにOver Temperatureのログ出力とサーマルスロットリングを受ける状態でした。室温が常に18度というような環境であればいいのかもしれませんが、人が生きる環境だと春以降温度が上がるため厳しいです。
確かに性能はnvmeがなかった当時としてはかなり高かったかもしれませんが、発熱量とドライバと消費電力量的にちょっと使いにくいのでどうにかしたい思いが強くなりました…。ドライバについては、Debianでも問題なくソースからドライバをコンパイルすることによって動きましたが…。

そしてちょっと前に、3.2TBのSSDが数本手に入ったので50TBのディスクの前段キャッシュにしようとしたのですが、ここであることにハマりました。キャッシュのメタデータ保持に4Kページ使用時でSSDの容量の0.1%程度のサイズのメモリを消費するのですが、RAID5などでまとめた実効9TBのSSDとなると、メタデータのために9GBのRAMが必要になります。RAM自体の空きはあったはずなのですが、メタデータが巨大になると、それをメモリ上に展開するのに非常に時間がかかるようになり、起動時のキャッシュの組み上げ時にランダムにカーネルが刺さってpoweroffもできなくなることがありました(つまり電ぷち)。
検証の結果、WBで使う場合にはキャッシュサイズが大体2TBを超えてくるとfstabではなく自分のスクリプトでマウント(及び付随するサービスの起動)をどうにかする必要が出てきて、またSRPのようなブロックデバイスアクセスだとそもそも思ったようなキャッシュの動きをしてくれなかったので、最終的に諦めました。NFSだったらまたキャッシュのヒットも違ったのかもしれませんが、あまり大きすぎるサイズのキャッシュが来ることを想定していないようでした。もっと前に検証で気がつけた部分もあるのですが、いざそのときにならないとわからない部分もあるのです…。
bcacheも試したのですが、こちらは思ったほどいい動きをしませんでした。
結局
SSDだけでも結構な容量なので、検証に使うSSDなLUNと、データ保存に使うHDDのLUNを分けることにしました。HDDのLUNでもストレージサーバ側のメモリキャッシュが効くので、データがホットな分にはHDDでも十分なのですが、VMのクローニング時には読みと書き込みが1つのLUNに同時に走るので、接続が全二重なSAS-HDD(NL-SASですが)といえどバックの性能差が顕著に出ます。
SSDはベンチマーク的に良かったSmartArray P420にキャッシュとキャパシタをつみHW-RAIDにしました。P420もHPE以外のマシンで使おうとするといろいろ苦労がありましたが…。経験的にエンタープライズクラスのSSD(IntelのDC3610とかMicronのM5000DCとか)は壊れたことがないので、おそらくフラッシュメモリ部分の劣化が来ることはないと思うのですが、過去にコンシューマSSDでコントローラー側の故障と思われる原因でSSDが見えなくなったことが何度かあるのでRAID5を選択しました。ただ、パリティでSSDの3TBが持っていかれるというのがなかなか気分としてつらいです。RAID0でも良かったのではと思わなくもないですが…。
ストレージマシンにメモリマシマシ
これは手っ取り早く効果が出ます。特にメモリがある程度大きいマシンで、ストレージ以外に仕事をさせない前提なら/etc/sysctl.confで
vm.dirty_background_ratio = 35
vm.dirty_ratio = 90
とメモリの90%位を書き込みバッファにしてしまうとわかりやすく速くなります。ストレージサーバだけで128GB位メモリを持っているとほぼオンメモリで動く上に、VM上でごちゃごちゃ書き込んだとしても最終的にXFSの遅延書き込みによりシーケンシャルになるので、SSDにも優しいです。多分。当然、突然のシャットダウン時にデータを損失する可能性はありますが、全損してもデータ自体は違う筐体から最短1日前に戻せるのでそれは許容しようかと思いました。崩れても誰にも怒られないので、それよりは性能を重視したいです。(ただし何かあったときに誰の助けも受けられないので血を吐きながら泣いて復旧作業をしなければならない)
ストレージ接続
現状Infiniband+SRPを超えるものが見つかりません。非公式ながらESXi6.5でもSRPは動きますが、Mellanoxのディスコン扱いがひどいのでなにか別の手段を探そうとしているのですが、結局これを超えられません。助けて…
8GFCのIOPS性能に夢を見た時期もありましたが、FCターゲットをLinux上に作ろうとするとHBAをイニシエーターからターゲットモードに変更するという手間や、苦労して作った割に10G iSCSI/NFSのほうが総合的に性能が良かったりFCターゲットは負荷をかけると刺さったりしたので、FCターゲットはベンダから買うものであって作るものではないと実感しました。SCSTのFCターゲットは試していないのですが、もしかしたらこっちはLIO/targetcliの環境で起きたようなことはなかったかもしれません…が、もうスイッチ含めて手放してしまったので検証できません。
いくら10G-iSCSIでも、レイテンシやIOPS的にSRPのそれには追いつきません。SRPの代替としてはほぼ同じ原理のiSERがありますが、40G Etherを入れて初めてIBのSRPと渡り合えるレベルなので、それ以下の25GbEなどではせっかく環境を揃えても純粋なストレージインターコネクトとしてはデグレになってしまいます。
100G EtherのスイッチとNICが手に入ればいいのですが、HCAが3000円で買える上にRDMAできっちり40Gbpsが出るIBに比べると、いま時点のパフォーマンス観点からの選択肢としてはIBに歩があります。ただ、IB自体が特に仮想化ではディスコンの流れをたどっている部分があるので、あまりこれにベッタリするのもやめたいのですが…移住先がない…。
どの程度の性能かというと、1ホスト1LUNで160kIOPSの性能が出せ、帯域面では3.3GB/s程度出ます。ほぼストレージサーバーのメモリへの読み書き速度ですが、VMホストから見てもIOPSのカウンタは回っているためVM内のメモリ書き込みではなく、しっかりとHCA経由でIOがやり取りされています。
デュアルポート接続なのでもう少し帯域を出せないかと思いましたが、そもそもPCI-Eの2.0のx8が500MB*8レーン=4GB/sであり、IBの8b/10bエンコードを考えると4GBの80%なので3.3GB/sというのはほぼ理論値でした。1HCA/DP構成ではなく1ポートHCA*2の接続にするか、PCI-E 3.0対応のCX-3以降に置き換えればPCI-Eの帯域が倍になるのでもう少し出ると思うのですが、未検証です。複数HCAのIO分散は気になるのでいつか試してみたいです。
まとめ
・ストレージを強くしたいならbcacheやeioなどの階層化ストレージに夢を見ずにフルSSDやnvme構成にするのが一番シンプルで速い
・それ以上を求めるなら多少の耐障害性を落としてもメモリを許されるだけ乗せるしかない
・IB+SRPは間違いなく速いが、いろいろノウハウがいるうえに仮想化周りではIB自体が鎮火しているので今からIBに投資するのはやめたほうがいい
・NFS over RDMAとか今からIBで再流行しないかな…だめかな…
・vSANは…うん、それもまた人生だね!
今の流れとしては分散型のスケールアウトストレージ+賢いローカルキャッシュというものがイケてる構成ですが、主に電力事情で動かせるマシンが限られてくると1つのマシンをいかに強くできるかというスケールアップ型になってしまいます。
この構成だとストレージの冗長構成が取れず/取ろうとすると非常に厳しく、何かしらでストレージが不意にクラッシュすると即死ですが、これはこれで普段切り分けしやすいという点で使いやすい面もあります。
スケールアウト型を車で例えるとトルクベクタリングなど次世代の仕組みを組み込んだ車ですが、SRPなどはシンプルに基礎を抑えていて低回転域から高回転域まできっちりトルクの出る大排気量車のようなものです。それぞれにいい悪いはあるのですが、後者は時代の流れによりディスコンなのが悲しいです。
無限に電気を使えれば無限にマシンを増やしてスケールアウト型のストレージなどにも手を出したいのですが現実は厳しいです。
完全に趣味の話でした。おしまい。
[ コメントを書く ] ( 499 回表示 ) | このエントリーのURL |
かなり更新をサボっていたので久々の更新です。Confluenceもメモ書きとして契約してしまっているのでこのブログをどうしようか悩んでいるのでいるのですが、しばらくは生かしておこうかと思います。さて、ちょっと前に秋葉原で捨て値で売っていたFortigate 40Cをいくつか買ってみたのですが、ACが付いてこなかったためつくってみました。

まず、このコネクタの名称の知識がなく調べる手がかりがなかったので、Googleの画像検索やら各レセプタの形状や名称一覧などを大量に調べました。その結果、どうやらMolex 5557の4.2ミリピッチというコネクタがそれっぽいようでした。
コネクタやコンタクトピンについては、千石通商などに売っているようなのですが、SonicwallのAP(TZ-100)にも同型のコネクタが使われていて、そのACで基本的な動作確認が出来てしまったので「急ぎでもないし、より安価なモノタロウで何か買うついでにいつか買おう」と放置していました。(ちなみに買った時点ではぎりぎりライセンスが生きていたのでOSのアップグレードが出来ました。) そして先日、諸々を買う機会があったのでついでに興味本位で買ってみました。

今回買ったコネクタとコンタクトピンは以下の二つです。
Molex 5557コネクタ 5557-02R-210
https://www.monotaro.com/p/0856/1585/
コンタクトピン 5556T3L
https://www.monotaro.com/p/7593/9272/
コネクタについてはより安いこっちでもよかった気がします。
https://www.monotaro.com/p/0856/1472/
とりあえずコネクタだけ形状が合うか確認しましたが、これであっているようでした。

次に、起動できるACの極性を確認しましたが、爪がある方が+でその下がーになっているようです。

極性が分かったのでピンをかしめていこうとしたのですが、専用の圧着機がないとつらいです。最終的にニッパーでかしめる技術を習得しましたが、何回かピンからケーブルがすっぽ抜けてブチ切れそうになったので、今回はやりませんでしたがハンダで軽くとめておくのが確実な気がします。(圧着とは…)
絶縁のために(ビニールテープが見つからなかったので)養生テープで根本を軽く巻いたのですが、これが失敗でした。ただでさえコネクタの奥までピンを押し込むのが大変なのですが、このテープのせいで余計やりづらくなりました。電子工作になれている人やもっと几帳面な人であればこんなことをしないと思いますが、動けばいいだろ位な雑な気持ちでやった結果、無駄な苦労をしました。

なんとかピンを奥まで押し込んでピンがロックされたことを確認したので、ちゃんとコネクタ内部のピン同士が接触していること、逆接になって爆発しないことを祈りながらACに繋いでみました。

すると、電源の容量不足やピンの接触が甘いといったこともなく、爆発せずに無事起動してきました。コネクタからピンのすっぽ抜け防止に紫外線硬化樹脂などで後ろを固めるのがよりよいと思いましたが、必要な物を買うと割と高くなるうえに買っても使うことは多くなさそうなので今回は見送りました。
作った感想ですが、コンタクトピンの圧着器を持っていないのであればおすすめしません。その辺の工具で済ませようとすると器用さというかコツが必要です。ラジオペンチやニッパーで代用は可能ですが、慣れるまでピンを4本無駄にしました。また、AC自体はオークションなどで1000円前後で売っているので、必要であればこっちを買うべきです。
ただ、自分のようにジャンクでAC無しのFGをいくつか拾って、しかもACをいくつか欲しいけどACが本体より高いし12VのACは大量に余っているので自作したい、という貧乏な考えがあるのであれば作るというのも一つの手ではあります。
しかし、カシメが不十分でケーブルがすっぽ抜けたりピンがしっかり奥まで入っていないためケーブルを動かすと接触不良で電源が落ちる、という事が起こるので(実際に起きて作り直した)、作ったとしても精々検証用にとどめておくのをおすすめします。
ちなみに、このFGはFlets網内のv6折返しのテストに使おうと思っていたのですが、FortiOS 5.2だとIPv6の自動設定にDHCP6-PDやSLAACが使えず、かつNP6を搭載していないためv6の通信がCPU処理になってしまい残念なことになった(LAN内のv6NAT通信で200MbpsくらいでCPUが張り付く)ので、v6関係は諦めVDOMが使えた頃の軽量な4.0MR3に戻しました。v6のSNATができたのは良かったのですが…残念。
[ コメントを書く ] ( 707 回表示 ) | このエントリーのURL |
<<最初へ <戻る | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 進む> 最後へ>>