
ネットワークカード的な意味で
PCI-Ex4なIntel Pro1000PT Dualportが5000円でオクに出ていたので落札してみました
PCI-Ex1の1000PT/Serveradapterは思ったほど速くありませんでしたがこっちはかなり良好です。軽くテストした感じ、ずいぶん前のエントリの1000PLとほとんど同じ性質でした。
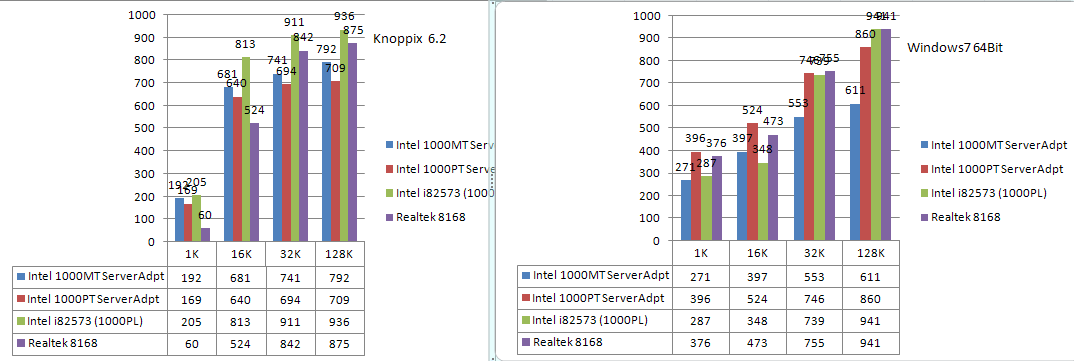
Trunkしておけば多数のクライアントがぶら下がっても2Gのトラフィックを余裕で捌けました。
まあぶっちゃけ最近のオンボのNICはどれもそこそこ速いので、サーバー用途などの特殊な理由がない限りこれを無理に使う意味はないですけどね。PCI-Xのような特殊形状ではないので最近のものであればどのマザーでもIntelNICが使えるという安心はありますが。
さてサブマシンに組み込みますかね…。
[ コメントを書く ] ( 1351 回表示 ) | このエントリーのURL |
以前試したときは重くてあまり使い物にならなかったような記憶があったSkypeだったのですが、今日試したら普通に会話できました。WLANは使わずにISnetを使用して移動せずに室内からの通話してみましたが前ほどレイテンシがなくなって実用レベルです。筐体が新しくなったついでになにか変わったのかWANが強化されたのか…。
通話中は大体30%位のCPU使用量でした。
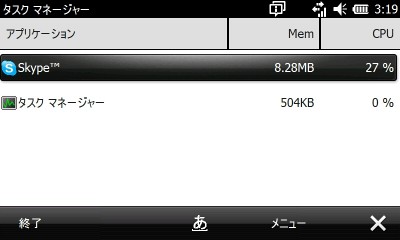
Skypeを使う際には音がスピーカー再生になりだだ漏れになるのでBluetoothヘッドセット推奨ですw
まあ本来はWindowsMobile向けには提供中止されてるんですけどねSkype
【追記】
とりあえず3時間くらいWANネットをつかってしゃべってみましたが特に問題はありませんでした。バッテリがちょうどそれくらいで切れたのでエネループ食わせながら連続実用通話は3時間くらいです。
通話音質は「TS(TeamSpeak)みたい」←すごく言い得てる
[ コメントを書く ] ( 1310 回表示 ) | このエントリーのURL |
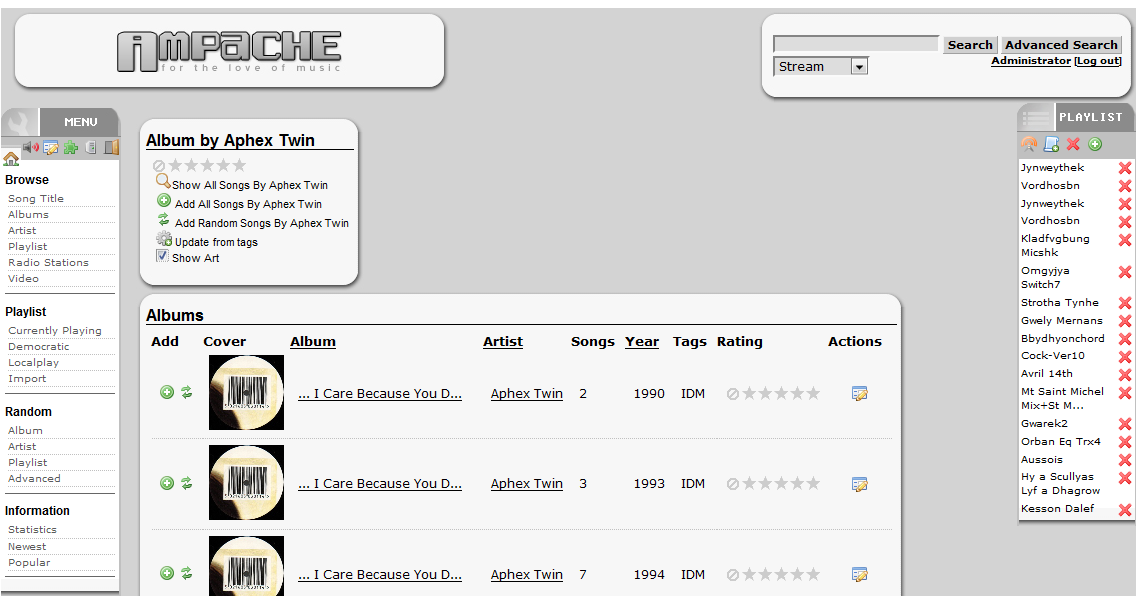
某所で話に上がったので実験鯖で試してみました
まあapt-get install ampacheしただけですけど
後はバーチャルホストの設定くらいですね
使ってみた感じ、アーティスト検索などができるのでなかなか便利です。
動きとしては、リストから+を押していってプレイリスト作成→m3uファイルへ書き出し、VLCやWinampなどのネットワークストリーミングに対応したプレイヤーで再生 or Flashプレイヤーによる再生 という感じです。Flashの場合は特別なソフトなしで聴ける代わりにmp3以外のFlacなどの再生に対応できません。おい…
アルバムアートがない場合はLast.fmから拾ってくるようで補完できるものはどんどん画像が追加されていきました。
次期物置き鯖にはこれを導入しようかと思っていますw
[ コメントを書く ] ( 1341 回表示 ) | このエントリーのURL |
不良だったメモリが帰ってきたので板に取り付けMemtest+を回している間にマザーの取説を読んでいたら気になる記述がありました
http://dlcdnet.asus.com/pub/ASUS/mb/soc ... ws_pro.zip

>DDR3-1600は各チャンネルにメモリ1枚としてサポートされます
今DDR3の1600を6枚使っているのですが、それはつまり…どういう事だってばよ!?
色々調べているうちにそれっぽいフォーラムを見つけました。
http://forums.extremeoverclocking.com/t308357.html
http://en.wikipedia.org/wiki/Bloomfield ... ocessor%29
The Core i7 has three memory channels, and the channel bandwidth can be selected by setting the memory multiplier. However, in early benchmarks, when the clock rate is set higher than a threshold (1333 for the 965XE) the processor will only access two memory channels simultaneously. A 965XE has higher memory throughput with 3xDDR3-1333 than with 3xDDR3-1600, and 2xDDR3-1600 has almost identical throughput to 3xDDR3-1333.[13
要するに規定以上の速度のメモリを取り付けると同時に2chしかアクセスしないって事ですかね?
探してもどうもそれっぽい解が見当たらないので色々試してみました
構成
M/B ASUS P6TWS-PRO
Mem GeIL GVP34GB1600C9DC@1656MHz
CPU Corei7 950@166*23MHz
手っ取り早くできるベンチとしてClystalMark2004 R3のMemoryの項を実行して結果を見てみました
まず1600-2Gを1枚で起動してみる

2Gだと正確な時間はとっていませんが起動にも若干の時間がかかりました。
4G
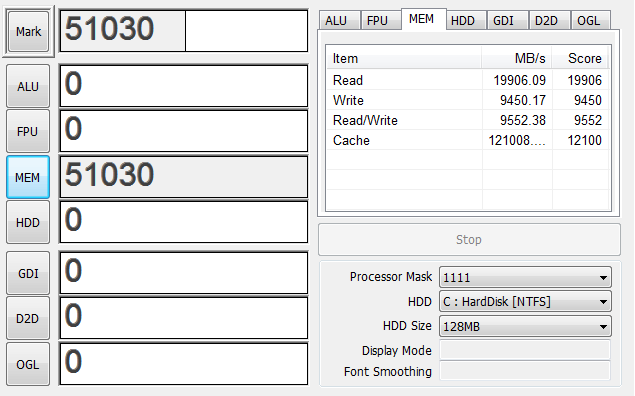
デュアルチャンネルが有効になったので速度が2倍近くになりました。
6G
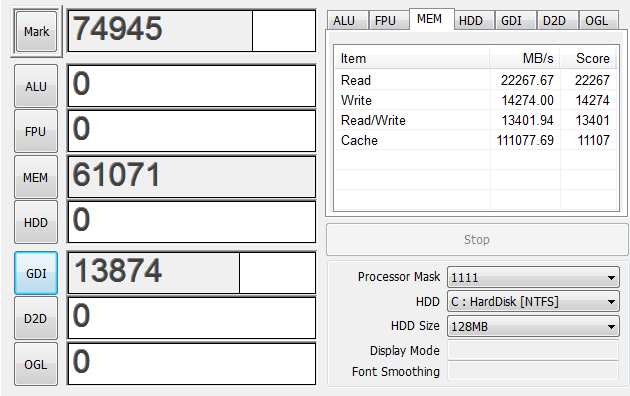
WriteとRead/Writeはシングルチャンネルの4555から14274まで増えたのでトリプルチャンネルは有効になっているようです
ここでもし中途半端な本数のメモリを刺したらどう動くのか気になったのでやってみました。
8G
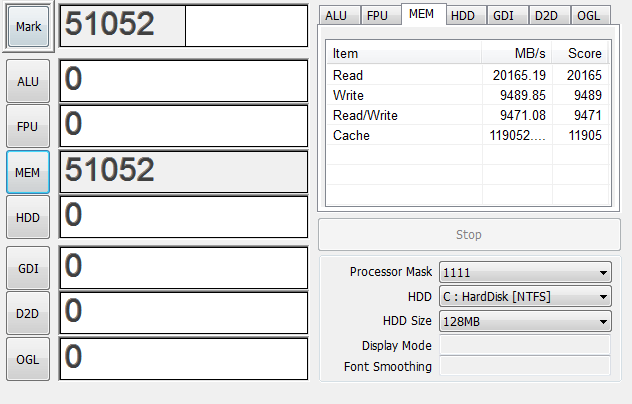
スコアとしてはデュアルチャンネルと同じ値になりました。これまでの板は4本でデュアルx2だったので納得できます。
しかし何故か表示上ではTripleChannelと表示されています。
ここでわかったのは
A B C ←バンク
010101 ←チャンネル
||||||←メモリスロット
111x1x
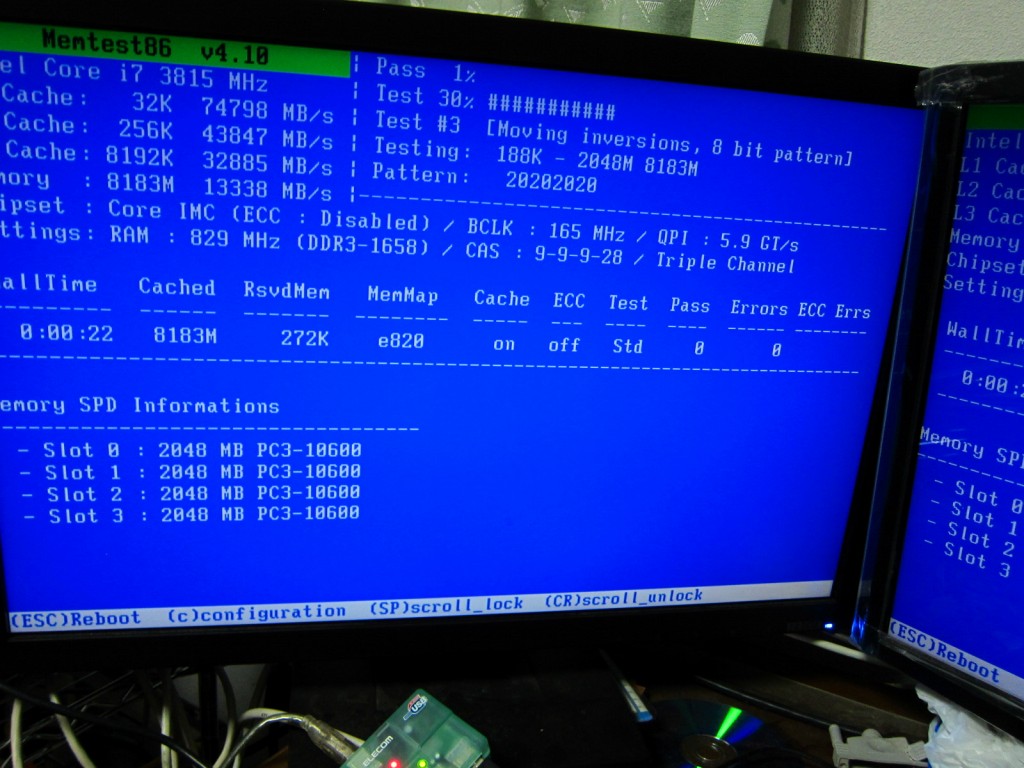
こう刺すとTripleChannelと表示され
||||||
1111xx
こうするとDualChannelと表示されますが、速度に差はないようです。
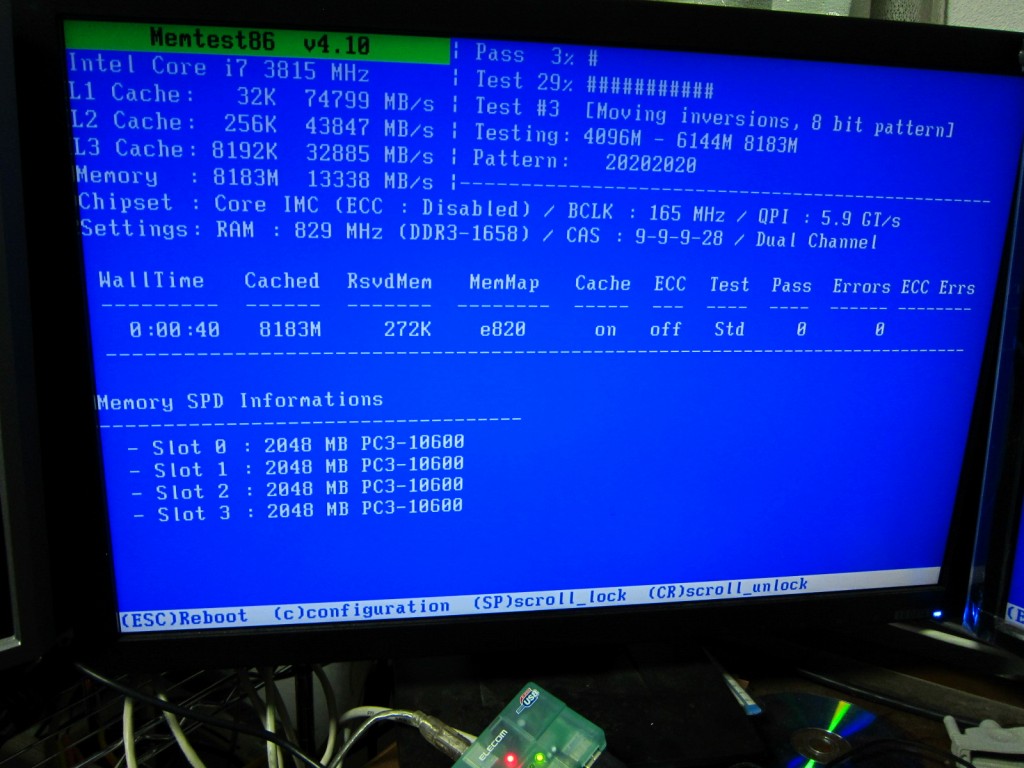
ちなみに
1x1xxx
こうだとデュアルですが
11xxxx
こうだとシングルチャンネルになります。原理を考えるともっともな動きですね。
あと、少なくともどこかのバンクのチャンネル0に1本はメモリが刺さっていないといけないようで
x1xxxx
x1x1xx
x1x1x1
これらではPOSTしませんでした。この辺の動きはメーカー依存な可能性が高いですが。
話を戻してデュアルともトリプルチャンネルとも言えない10Gで起動してみる。
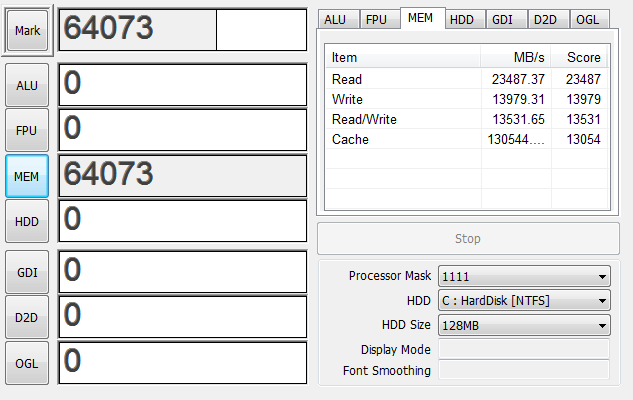
あれ…?速くなってる…?
もしかして先頭6Gがトリプルチャンネルで動いてケツ4Gがデュアルチャンネルで動いてる…?いやそんなキモイ動き許されるはずが…
仮想マシンを量産して9Gほど使った上でベンチを再度とってみる
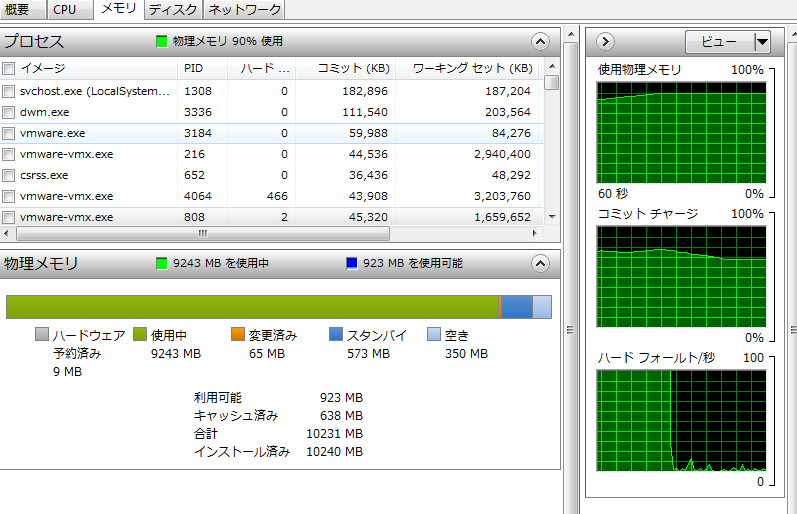
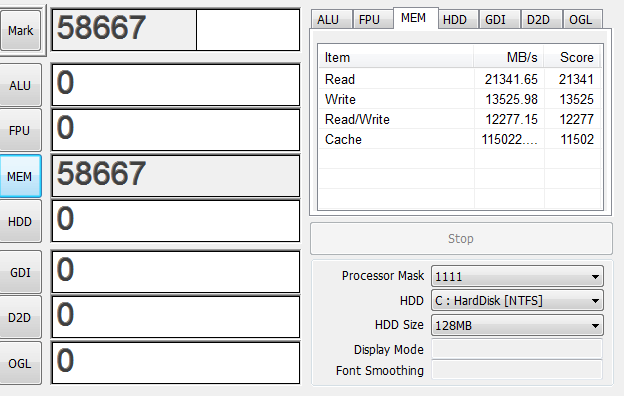
仮想マシンが動いてることを考えるとそこまで落ち込んでないですね
解せぬ
よくわからないので考察は後にして12Gで起動してみる
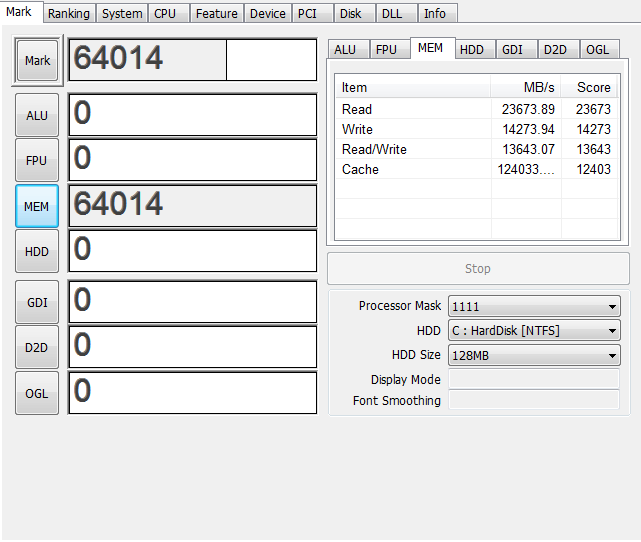
6Gの時とほぼ変わらないのでこれはトリプルチャンネルが働いてるって事でいいんですかね…?
まあ、動いてるしいいんじゃないかな
そして考えるのをやめた。
結論:メモリスロットが空いてるなら空いてるだけぶち込め
「そんな結論で大丈夫か?」
「大丈夫だ。問題ない」
[ コメントを書く ] ( 1506 回表示 ) | このエントリーのURL |
前回から「いかに速いファイル置き場を作るか」という目的を達成すべく色々実験してみました。そのせいで数字多いよ!
まずはUbuntu10で実験。
root@1:/# uname -a
Linux 1 2.6.32-24-server #39-Ubuntu SMP Wed Jul 28 06:21:40 UTC 2010 x86_64 GNU/Linux
マシンはいつものです。
product: TYAN-Toledo-i3210W-i3200R-S5220
product: Intel(R) Core(TM)2 Quad CPU @ 2.40GHz
MemTotal: 4048444 kB
特に断りがない限りファイルシステムはmkfs.ext4で作成。ベンチ方法は/dev/zeroからddで書き込み。今思ったらシーケンシャルW/Rしかみてないですね。
Bonnie++使うべきだったんじゃねと思うけど参考値程度に
RAID0
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid0 sde1[3] sdb1[2] sda1[1] sdc1[0]
156246528 blocks 256k chunks
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 15.351 s, 273 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 16.567 s, 253 MB/s
そのときの負荷
CPU | sys 41% | user 0% | irq 1% | idle 142% | wait 216% |
cpu | sys 29% | user 0% | irq 0% | idle 19% | cpu002 w 52% |
cpu | sys 12% | user 0% | irq 0% | idle 4% | cpu001 w 84% |
cpu | sys 1% | user 0% | irq 1% | idle 0% | cpu000 w 97% |
CPL | avg1 0.77 | avg5 0.89 | avg15 0.73 | csw 1684 | intr 3377 |
読み込み
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 15.1826 s, 276 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 16.7144 s, 251 MB/s
負荷
CPU | sys 20% | user 0% | irq 0% | idle 289% | wait 91% |
cpu | sys 14% | user 0% | irq 0% | idle 0% | cpu002 w 86% |
cpu | sys 4% | user 0% | irq 0% | idle 96% | cpu001 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
まずmdadmでRAID0ですが、RAID0はさすがに読み書き速いです。ちょっと古いドライブなので外周で読み書き70MB/sec程度なのですが、ドライブを追加すればそれだけリニアに速くなりました。
が、アレイの中の1ドライブでもFailしたらすべてのデータがさようならは怖すぎるので実用的ではないです
RAID1
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sde1[3] sdb1[2] sda1[1] sdc1[0]
39061376 blocks [4/4] [UUUU]
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 60.178 s, 69.7 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 62.0388 s, 67.6 MB/s
そのときの負荷
CPU | sys 23% | user 0% | irq 2% | idle 179% | wait 195% |
cpu | sys 1% | user 0% | irq 0% | idle 92% | cpu003 w 6% |
cpu | sys 4% | user 0% | irq 2% | idle 0% | cpu000 w 94% |
cpu | sys 12% | user 0% | irq 0% | idle 55% | cpu002 w 33% |
cpu | sys 5% | user 0% | irq 0% | idle 41% | cpu001 w 53% |
読み込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 62.0388 s, 67.6 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 63.6339 s, 65.9 MB/s
そのときの負荷
CPU | sys 7% | user 0% | irq 0% | idle 303% | wait 90% |
cpu | sys 5% | user 0% | irq 0% | idle 0% | cpu001 w 95% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu002 w 0% |
CPL | avg1 1.09 | avg5 1.32 | avg15 1.06 | csw 5471 | intr 3396 |
MEM | tot 3.9G | free 31.2M | cache 3.6G | buff 3.1M | slab 80.0M |
SWP | tot 0.0M | free 0.0M | | vmcom 402.1M | vmlim 1.9G |
PAG | scan 43008 | stall 0 | | swin 0 | swout 0 |
DSK | sdc | busy 88% | read 1289 | write 0 | avio 2 ms |
DSK | sda | busy 7% | read 100 | write 0 | avio 2 ms |
RAID1では1ドライブ分のスループットという予想通りな結果になりました。4ドライブ使っても読みの時は1ドライブしか仕事していないという。まあ冗長性に関しては最強だと思います
RAID5
md2 : active raid5 sde1[3] sdb1[2] sda1[1] sdc1[0]
117183744 blocks level 5, 256k chunk, algorithm 2 [4/4] [UUUU]
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 38.2853 s, 110 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 46.0981 s, 91.0 MB/s
そのときの負荷
CPU | sys 52% | user 0% | irq 3% | idle 257% | wait 88% |
cpu | sys 16% | user 0% | irq 0% | idle 77% | cpu002 w 8% |
cpu | sys 17% | user 0% | irq 0% | idle 81% | cpu001 w 3% |
cpu | sys 9% | user 0% | irq 3% | idle 33% | cpu000 w 55% |
cpu | sys 11% | user 0% | irq 0% | idle 65% | cpu003 w 24% |
読み込み
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 25.6145 s, 164 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 26.0037 s, 161 MB/s
負荷
CPU | sys 20% | user 0% | irq 0% | idle 289% | wait 91% |
cpu | sys 14% | user 0% | irq 0% | idle 0% | cpu002 w 86% |
cpu | sys 4% | user 0% | irq 0% | idle 96% | cpu001 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
RAID5ですが、正直もっと書き込みが遅くなると思っていたのにディスク単体より速くなりました。パリティー計算さえなければストライピングですからね。
というか下手なHWコントローラー使うよりCPUパワーでブン回した方が速いですね…。
リビルドは大体40Gのドライブを-fして-aすると15分くらいでした
RAID6
root@1:# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid6 sde1[3] sdb1[2] sdc1[1] sda1[0]
78122496 blocks level 6, 256k chunk, algorithm 2 [4/4] [UUUU]
書き込み
root@1:# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 55.1364 s, 76.1 MB/s
root@1:/home/owner# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 59.1087 s, 71.0 MB/s
負荷
CPU | sys 44% | user 0% | irq 1% | idle 249% | wait 107% |
cpu | sys 17% | user 0% | irq 0% | idle 80% | cpu002 w 3% |
cpu | sys 9% | user 0% | irq 0% | idle 9% | cpu000 w 81% |
cpu | sys 11% | user 0% | irq 0% | idle 86% | cpu003 w 3% |
cpu | sys 6% | user 0% | irq 0% | idle 72% | cpu001 w 22% |
読み込み
root@1:# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 29.0997 s, 144 MB/s
負荷
CPU | sys 12% | user 0% | irq 0% | idle 291% | wait 96% |
cpu | sys 3% | user 0% | irq 0% | idle 97% | cpu001 w 0% |
cpu | sys 8% | user 0% | irq 0% | idle 0% | cpu002 w 92% |
cpu | sys 0% | user 0% | irq 0% | idle 99% | cpu003 w 0% |
cpu | sys 0% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
冗長性
root@1:# mdadm -f /dev/md2 /dev/sdc1 /dev/sde1
mdadm: set /dev/sdc1 faulty in /dev/md2
mdadm: set /dev/sde1 faulty in /dev/md2
root@1:# mdadm -r /dev/md2 /dev/sdc1 /dev/sde1
mdadm: hot removed /dev/sdc1
mdadm: hot removed /dev/sde1
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid6 sdb1[2] sda1[0]
78122496 blocks level 6, 256k chunk, algorithm 2 [4/2] [U_U_]
適当に転送した50GくらいのファイルはSambaからロストしていませんでした。
違うドライブをFailにしてみる
root@1:# mdadm -a /dev/md2 /dev/sdc1 /dev/sde1
mdadm: re-added /dev/sdc1
mdadm: re-added /dev/sde1
ビルドが完了してから
root@1:/# mdadm -f /dev/md2 /dev/sdc1 /dev/sda1
mdadm: set /dev/sdc1 faulty in /dev/md2
mdadm: set /dev/sda1 faulty in /dev/md2
root@1:/# mdadm -r /dev/md2 /dev/sdc1 /dev/sda1
mdadm: hot removed /dev/sdc1
mdadm: hot removed /dev/sda1
root@1:/# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid6 sde1[3] sdb1[2]
78122496 blocks level 6, 256k chunk, algorithm 2 [4/2] [__UU]
これも残ってました。
しかし、読み込みはいいとして書き込みはやはり速度は落ちますね。単体よりは若干速いですが。
あとアレイの再計算と初期化に時間がかかりすぎます。40G*4ドライブ程度の容量でリビルドに30分。もし2T*4で組んだとしたら…
30 minute * 51.2(2T/40G) = 25.6 hour
( ゚д゚ )
しかもその間ドライブはリビルドで
DSK | sdc | busy 80% | read 538 | write 271 | avio 3 ms |
DSK | sde | busy 80% | read 534 | write 269 | avio 3 ms |
DSK | sdb | busy 37% | read 555 | write 142 | avio 1 ms |
DSK | sda | busy 35% | read 548 | write 130 | avio 1 ms |
というゴリゴリとアクセスしている状態。これが1日続いたらその間にほかのドライブが壊れてもおかしくないような…
RAID10
書き込み
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 30.0364 s, 140 MB/s
root@1:/# dd if=/dev/zero of=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 31.9872 s, 131 MB/s
負荷
PRC | sys 0.69s | user 0.02s | #proc 141 | #zombie 0 | #exit 0 |
CPU | sys 24% | user 0% | irq 3% | idle 212% | wait 161% |
cpu | sys 3% | user 0% | irq 0% | idle 97% | cpu003 w 0% |
cpu | sys 11% | user 0% | irq 3% | idle 2% | cpu002 w 84% |
cpu | sys 6% | user 0% | irq 0% | idle 84% | cpu001 w 10% |
cpu | sys 3% | user 0% | irq 0% | idle 40% | cpu000 w 57% |
読み込み
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 31.9915 s, 131 MB/s
root@1:/# dd of=/dev/null if=/smb/4G.img bs=1M count=4000
4000+0 records in
4000+0 records out
4194304000 bytes (4.2 GB) copied, 32.2236 s, 130 MB/s
負荷
CPU | sys 11% | user 0% | irq 1% | idle 294% | wait 95% |
cpu | sys 8% | user 0% | irq 0% | idle 0% | cpu002 w 92% |
cpu | sys 2% | user 0% | irq 1% | idle 97% | cpu003 w 0% |
cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
スループットはほぼRAID1の時の2倍なのでもっともな動きだと思います。
ビルドにも10分程度。2Tで大体5時間程度?
気になったのがRAUD10でのデータの冗長性。理論でいえば2つのRAID1のアレイをストライプするので、データは
| MIRROR1 | MIRROR2 | ||
|---|---|---|---|
| sda | sdb | sdc | sdd |
| data1 | data1 | data2 | data2 |
| data3 | data3 | data4 | data4 |
| data5 | data5 | data6 | data6 |
こうなると思うのですが…。
と思ったら実際その通りだった
http://d.hatena.ne.jp/BlueSkyDetector/2 ... 1212936771
というかRAID10って2台で組むと読みをストライプするRAID1になるのw
http://www.togakushi.zyns.com/modules/w ... x.php?p=54
つまり、違うデータを持ったドライブが2台死ぬ分には大丈夫だけど、同じデータを持ったドライブが同時に2個死んだら終了という。
6台だと違うデータを持ったドライブなら同時に3台まで平気だけど、やっぱり同じデータを持ったドライブが2台死んだら終了ですね
4台以上でやるときに読みは2台でActiveとbackupになり、2台目には負荷が掛からないはずなので読みが多いところでは2台が同時に壊れる可能性は低いと思います。
しかし書き込みが多く入るような場所だと同じ負荷がすべてのドライブに掛かってしまうので同時に壊れる可能性は高いと思います
パフォーマンスは上がりますがRAID6のように「どのドライブでも2個壊れて平気」とはいかないので難しいところです。
mdadmではなくてIntel Rapid Storageではどう動くのか?というのも気になったのでちょっと試してみました。実験の合間合間のリビルドの時間を使って動画を作ってみました。
Get the Flash Player to see this player.
作業BGMに定評のあるKOKIA
結果を見ると
p0 p1 p2 p3
1 1 2 2
3 3 4 4
という感じでデータを持っているようです。Intel Rapid StorageでもRAID 10の動きは同じようです。
色々試したまとめ
ぶっちぎりたいならRAID0だけど物置には怖くて使えない
耐障害性を持たせるならRAID6がいいけどパフォーマンス(特に書きとリビルド)に問題あり
遅いと思ってたRAID5はCPUパワーがあれば速い。容量も一番効率よく使える。けど2台同時に死んだら問答無用で終了
パフォーマンスとある程度の耐障害性を持たせるならRAID10がいいけど、運悪く同じデータを持ったドライブが2個死んだら終了
この中だと個人的にはRAID10がいいんじゃないかなと思うのでこれを使う方向で考えてみます
[ コメントを書く ] ( 1824 回表示 ) | このエントリーのURL |
<<最初へ <戻る | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 進む> 最後へ>>