
メインマシンの調子が悪くなってきたので使っているM/Bを新しくしました。そのことについてあれこれ書いてみます
そもそもの経緯
長いこと使っていたX9DAiですが、使っていて一つ問題がありました。それは再起動/コールドブートが一発で上がらないという点です。書くと長くなってしまうのでかいつまんで書きますが、どうやらオンボードに持っているRenesas uPD720200AがWindows10と相性が悪いようで、起動時にこれのドライバの読み込みでコケます。Windbgのシリアルケーブルデバッグで起動シーケンスを他のマシンから見たときに、止まるときはだいたいこのへん(USB絡みのドライバのロード)で死にます。
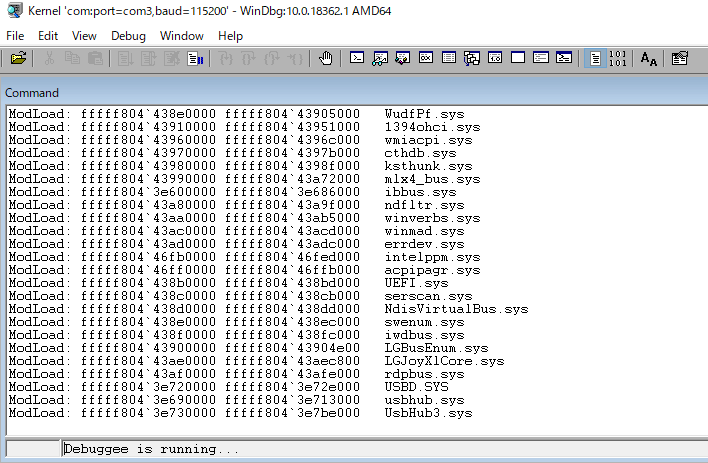
一発で起動できないせいで、電源強制OFF→再度起動とやる必要があり、これを繰り返した結果OSが破損しました。

OSが壊れた結果、VMRCが何もしていないのにクラッシュしていつの間にかすっと消えている、WindowsUpdateが確実に失敗する、その他不思議な不具合現象が起きるようになりました。ファイルシステム破損→ファイルシステムを直してもOSの不整合が発生してしまったときにどうすれば直せるのか、自分にはわかりませんでした…。
この起動できない問題はすべてのUSB機器を外した上で様々なドライバを試しても解消せず、まっさらなWin10を入れようとしてもインストーラーが(おそらく上記問題で)コケて上がってこない、他のマシンでOSをセットアップしてディスクを差し替えて使っても解決しないという結果が出たので、uPD720200AがWindows10に対応しきれていない、もしくはチップがハードウェア的に壊れていると判断してマシンの置き換えを検討し始めました。起動してしまえば安定するんですがね…。
ハードウェア選定
新しくしたいと思っても色々要件があり、以下の要件を満たすM/Bの選定に苦労しました。要件としては
・グラボをゲーム用+サブディスプレイ用の2本刺したいので、x16を1つ、x4程度のリンクを1つもっている
→メインのグラボをx8のリンクに落としたくない、どうでもいい画面の表示はサブグラボに任せてメイングラボのVRAMを使いたくない
・10GのNICを刺したいのでx8がほしい
・U.2のドライブを使いたいので、変換するためのM.2スロットをもっている/もしくはx4スロットを持っている
という要件があり、理想としてはフルx16を1本、x8を2-3本持っている、というのが理想だったのですが、今のAMD/Intelのコンシューマ向けCPUではそもそも生えているリンク数が足りないので、第一候補はXeon W-3235とSupermicroのX11SPA-Tが候補でした。
第一候補だったX11SPA
X11SPAのシステムブロック図を見てみましたが、なかなかに気持ち悪い構成でした。
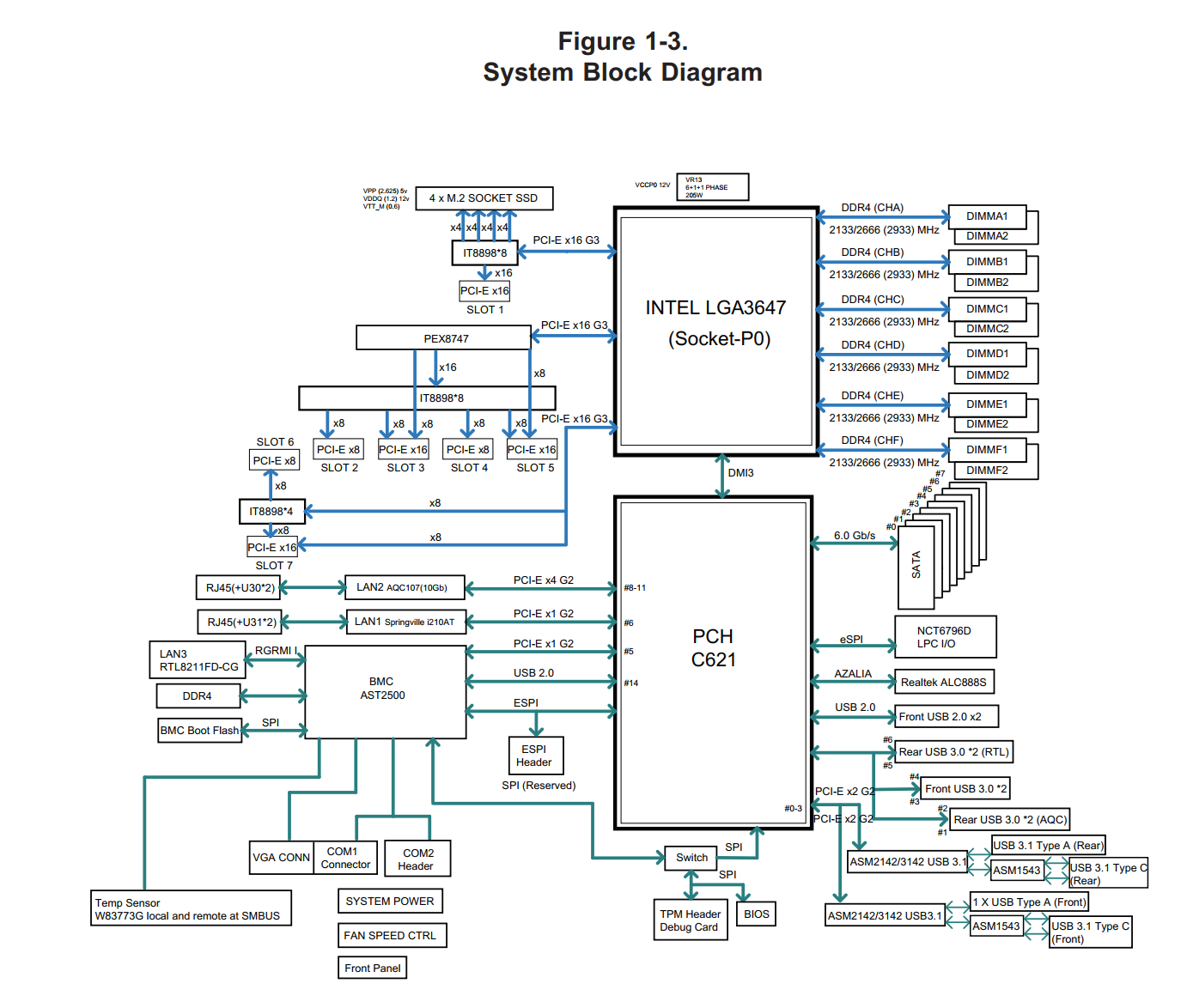
左側のPEX8747の部分がキモですが、PEX8747にはまずx16でリンクし、そこからIT8898にリンクしています。これがどういう動きをするのかと見てみると、Slot2が使われている場合はSlot2と3がx8リンクになり、Slot2が使われていないときはSlot3がx16接続になるようです。スロット4,5も同じ動きになるようで、最大リンク時にはSlot3とSlot5がx16接続、もしくはSlot2-5がx8接続、合計レーン数は32となりますが、アップリンクがx16なのですべてのスロットで同時に最大帯域を出すとサチュレーションが起きる、という構成のようです。
その下にあるSlot6と7については、IT8898にリンクしているx8がSlot6が使われていない場合はスロット7に接続されるので、スロット7はx8+x8の合計16レーンで接続される、という動きのようです。
この構成が気持ち悪すぎて惚れたのでM/Bだけでも先に買ってしまおうかと思ったのですが、残念ながらXeon W-3235が全く出回っておらず、そもそもトレイ品でしかまだ出ていないので海外でも国内でも発注していつ来るかわからないという状態でした。
そんな状態だったので、W-3200シリーズが出回るまで耐え凌ごうかなと思っていたのですが、なんとなく秋葉原を歩いていたら変なマザボを見つけてしまいました。
変態構成なC9Z390-PGW
これもなかなかの変態で、以下のような構成です。
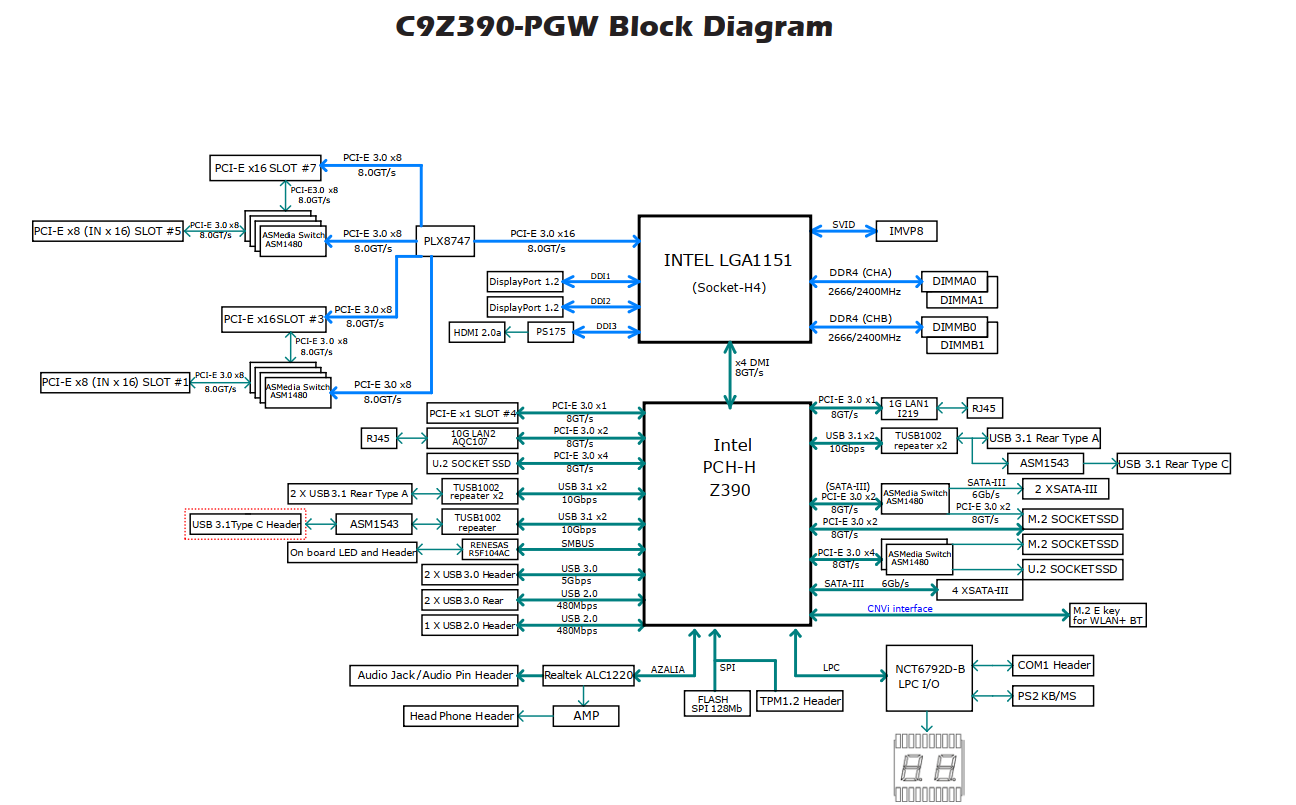
パッと見意味がわかりませんが、やはりPLX8747が肝で、X11SPAと同じようにまずスイッチにx16でリンクし、そこからSlot7にx8でリンクし、Slot5が使われていなければASM1480に使われているx8がSlot7に追加で接続されてx16でのリンクになり、Slot1,3も同じ動きになるので、16/0/16/0、16/0/8/8、8/8/16/0、8/8/8/8のいずれかの構成が可能になるようです。ただしアップリンクがx16に対しての32レーン分配なので最大帯域を使うとサチる、またスイッチングコストが発生するのでx16を1つしか使わなくても直結より1%程度パフォーマンスが落ちるようです。
前回PCMでパフォーマンス監視をしたときに、ゲーム時にグラボが接続されているx16レーンは7-8GB/s程度の帯域を使用していたので、x8でリンクすると微妙に足りない(大体7.7GB/s)のですがx16もいらない(大体15.5GB/s)という感じだったので、グラボ+x8の何かを接続するには丁度いいような気がします。
PCH側も変態構成で、そもそもなぜかオンボードでU2を持っていて、U2.2はx4でリンク、U2.1はM.2.2が使われていなければx4リンク、M.2.2も使う場合はx2とx2接続になり、M.2.1はSATA4/5を使わなければx4でリンク、SATA4/5も使う場合はx2リンク、となるようです。つまり、リンクが落ちるのを許容すればM.2もU.2も2本ずつ積めます。ただしアップリンクがDMIでのリンクなのでPCH全体で大体4GB/sの帯域を共有することになるので、すべてのインターフェースを同時に使うと足りなくなりますが…。
このボードでマシンを構成すると
・Fモデルを買わなければCPUからDPを2ポート+HDMIを1つ独立で出せるので、追加のグラボが不要
→今の構成はHP ZR2740w*3枚+Lenovo T2424Pという4枚構成なのですが、そのうちのZR2740wを2枚とT2424pの出力を賄おうとすると、大体のM/BはHDMI+DP構成になってしまうので、HP ZR2740wが持っているDP/もしくはDVI-Dリンクで接続しようとするとオンボードだけでは足りません。
M/BによってはDVI端子を持っているんですがDVI-Iなので1920*1200が最大解像度になってしまって2560*1440(WQHD)を出せません
・U.2ドライブをそのまま接続できる ←つよい
・オンボードで10Gを持っているのでうまくすれば追加の10Gを削れる
・帯域を共有するものの16/0/8/8という構成が取れる
・OCできる
というメリットがあったため、まさに自分のためのボードでは????と運命を感じ購入しました。
ちなみに、前の世代ではASRockのZ270 SuperCarrierがPCI構成で似たような構成をとっていたようですが、現行世代のチップセットではコスト面からか作っていないようです。どうでもいいですが他社だとコンシューマ向けM/Bではシステムブロックダイアグラムを載せていないので直感的に理解できなくて困りました。そのへん●はよくわかってんなと感心しました。一般消費者はそんなもの気にしないというのもありますが。
開封の儀
全体画像は冒頭に貼ってしまったので省略しますが、特殊な構成をピックアップしてみます
スイッチングチップ
この気持ち悪い構成を可能にしているPLXのPCI-Eスイッチングチップです。ヒートシンクが乗っているためチップ自体は直接見えません。

U.2コネクタ
既存でいくつかU.2ドライブを持っているので、これを使うためにU.2コネクタが必要でした。

U.2のnvme自体はPCI-E変換カードやM.2から変換できるのですが、その手間が省けるので直接持っているのはありがたいです。

ただ、U.2ドライブを接続するとPOST時間が伸びます。接続しているドライブが古いせいかもしれませんが…
オンボードLED
ゲーミングなんちゃらの例にもれずこのMBも光るのですが、はっきり言ってクソダサいです。

なんというか光り方にセンスが無いと言うか、陰キャが無理してパリピを装おうとしたものの溢れ出すオタク臭がつらいというか…。即無効化しました。ユーティリティからパターンを変更できるようですが、そもそも光る意味がありません。このLEDを意味もなく光らせる文化死滅してくれ。(LEDが意味を持っている場合は別)
いつもの起動Beep音
Supermicro特有の「pi,pipi……pi!」という起動Beepがあります。これはX8(X9?)シリーズくらいからの伝統で、サーバーボードで散々聞いてきた音です。2ソケットマザーでメモリスロットを24本も持っているような板だと、メモリそれぞれは問題なくてもスロットの場所によって何故か起動できなかったりします。そして総当たりでメモリを認識できるスロットを探すわけですが、起動する組み合わせをようやく見つけたときにこの起動音がするので、個人的にこの音を聞くととても安心と気分の高揚を覚える程度には毒されています。ジャンパーピンで無効化できますが、有効のままにしています。
何故か持っているシリアルポートとSATA-DOM用電源コネクタ
何故かシリアルのピンヘッダーをもっているので、汎用のCOMブラケットを接続するとRS232-Cが使えます。ゲーミングなんちゃらを求める人のうちどれだけの人がCOMを求めるのでしょうか。ちなみにCOMを持っているとWindbgなどの診断時にとても役に立つのでありがたいです。SATA-DOM用電源コネクタについては、「これいる??」という感想です。NASやPCルーターを作るときには欲しくなりますが、普段はまずいらないと思います。ゲーミングなんちゃらと謳ってる割には特定方向の需要を満たし過ぎではないですかね…。方向性が迷子になっている感じがあります。(が一部の人(主に自分)にはありがたい構成です。)
何故か持っているPS/2コネクタとWindows7対応
BIOS上になぜかWindows7のインストールに対応するための項目があります。内容としてはUSB3.0を2.0のまま使う(EHCIからxHCIのハンドオフを行わない)という内容です。PS/2コネクタもその絡みで持っているのだと思いますが、そもそもサポートマトリックスにはWin7はないので自己責任で試す際のアシスタントとして使う程度のものみたいです。今からWin7を最新ハードにクリーンインストールする人がゲーミングなんちゃらを求める層にどれだけいるのか不明ですが…。
セットアップ
今回の構成は以下のようになりました
CPU
今回はCPUに9600Kを使用しました。それ以上になると、デスクトップ用途ではそこまでコア数がいらないという経験則と、OCしたときにコア数が少ないほうが高クロックにしても発熱が少ない、及び価格的に一番お買い得という理由でこれにしました。だったら3235いらないんじゃ?と言われたらPCIレーン数とメモリ帯域以外はそうなんですが、同世代の3223と3225と3235と並べると3235がお買い得感あるので…。W-3235を考えていたのでCPUもM/Bもかなり安く感じてしまいました。
メモリ
メモリは手元に16GBが2本あったので、それと今回32GBのRAMを2本購入したので合計96GBになりました。32GBを4本買っても良かったのですが余らせるのももったいないので既存のものも使うことにしました。

グラボ
今使っている1080をそのまま使います。2080TIほしい
ファームウェア更新
UEFI上にファームウェア更新という項目はあるのですが、まずそこからやろうとすると以下のように怒られます
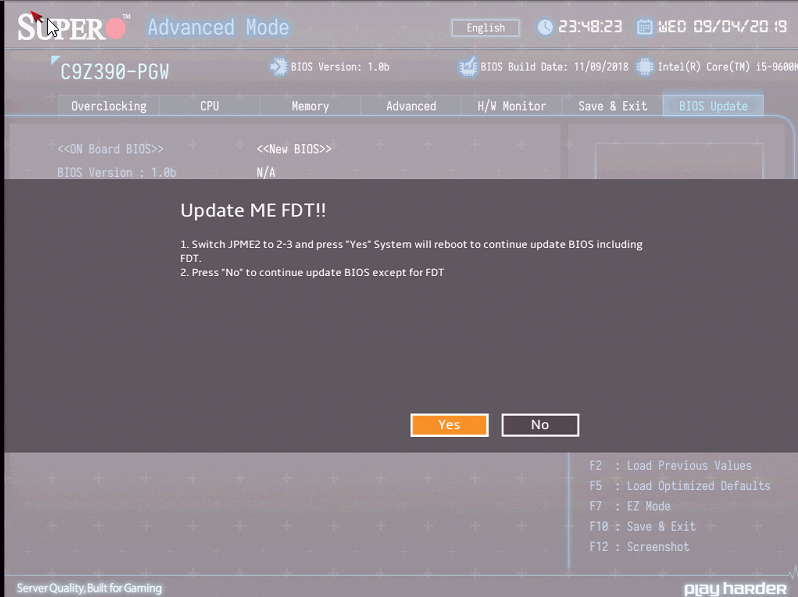
JPMEと言われ、なんとなくMEファームウェアのジャンパピンかなと予測がついたのでそこまでハマりませんでしたが、そんな経験のない人にはいきなり難問です。そしてJPME2のジャンパを切り替えて再度実行したのですが、バージョン1.0bから1.0cにアップデートしようとしても何故か反応しませんでした(MEファームウェアが同時に更新されるFWはだめっぽい?)。マニュアルの手順を見るとUEFIのシェルから実行しろと書かれていたので言われたとおりUEFIのシェルから実行したところ、成功しました。
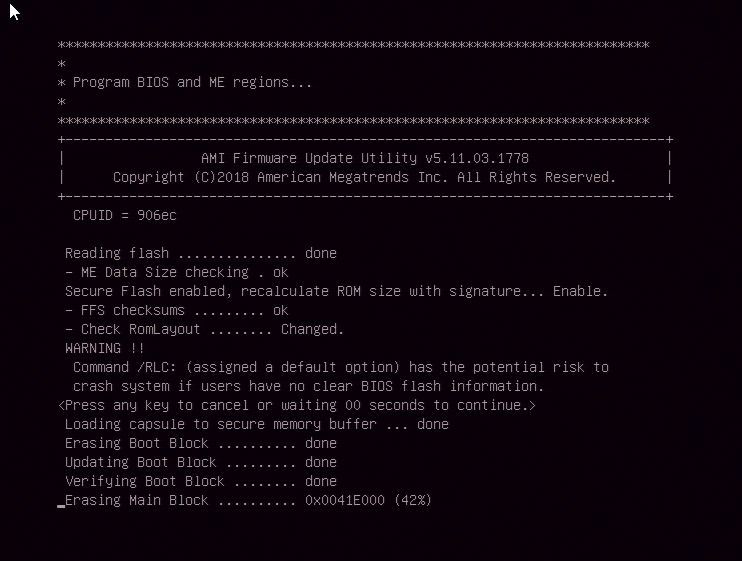
「いやーうちの製品買うような層はオタクしかいないからGUIが動かなくてもいいっしょwwwwwwww」という判断があったかどうかは知りませんが、これも初心者の心を折るには十分な儀式だと思います。特に今のUEFIなんかはネットワークを有効にしているとOS不要でネットワークから新しいFWを取得し、そこからアップグレードできるためほぼ何も考えずに済むので、そこから始めた人にとってはいきなりコマンドラインというのは十分に初見殺しですね。
個人的にはDOSの起動ディスクを作らなくてもオンボードでUEFIのシェルが上がるので楽だと思いました。鍛えられすぎているせいもありますが。というか動かないなら項目作らないでくれ…。ちなみに昔からの伝統のSUPER.ROMによるエマージェンシーリカバリーにも対応しているようです。過去に何回かお世話になった実績があるので、万が一でも安心です。
ハマリポイント
今回、起動ドライブにU.2のMicron 9100MAXを使おうとしたのですが、インストールはできるものの起動ドライブとしては使えませんでした。SandiskのSkyHawkでは起動できたので、古いU.2ドライブについては起動を考慮されていないのでしょう。
環境移行
OSをまっさらな状態にしてそこから必要なものだけ入れていこうかと思いましたが、それが思っていた以上にめんどくさかったので、普段取得しているVeeam backupのイメージ(X9DAiの壊れかけのOSイメージ)を一旦SATA-SSDにコピーし、そこからWindowsのISOをマウントして1903までアップグレードしました。そのタイミングで古いWindowsはWindows.oldになり、システムに必要なドライバやコンポーネントそのものは新しくなるので、システムの整合性は直ります。
ただ、SATAのSSDにクローンしてから1903に上げるとバージョンが上がったときに接続されているドライバのみが起動時に読み込まれるようになる(ドライバ周りがリセットされる)ようで、SATAのSSDだけつないだ状態のデータをnvmeにクローンしたところ失敗しました。
そのため、一旦データドライブとしてnvmeをシステムに接続してOSの起動時にnvmeドライバを読み込むように教え、その後OSイメージをnvmeにクローンするとうまくいきました。SATA→M.2への移行のときも同じテクニックが使えるかもしれません。
OverClocking
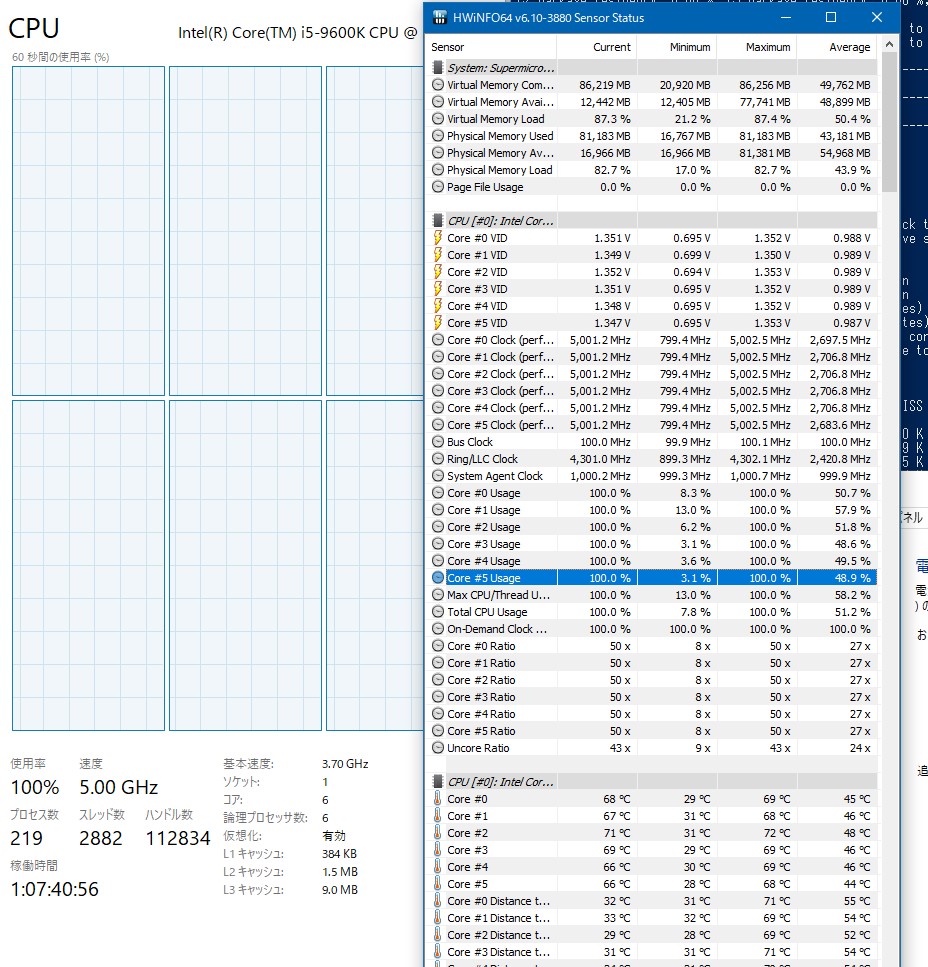
せっかくOCに対応しているのでOCしてみました。最初はM/Bのプリセットで持っている5.2GHzというのを選択してみましたが、コア電圧1.45Vやその他電圧もりもりで、起動できるものの空冷ヒートシンクだと負荷をかけた瞬間に100℃を軽く超えOHでシャットダウンされました。その後簡易液冷キットを購入して試したところ、熱問題はギリギリクリアできましたが、やはり5GHzより上になにかの壁があるようでした。
5GHzは1.32V+LLC Lv1で安定するのに対して5.2GHzでは1.45Vも必要になるので、発熱と消費電力的に5GHzで運用することにしました。もう少し詰めれば5.1や5.2のいいところが見つかるのかもしれませんが、いかんせん安定性のテストに時間がかかるので妥協しました。
このときにWindowsを入れてOCCTやPrime95などを起動していたのですが、それだとクラッシュしたときにファイルシステムが壊れることがあるので、まずはドライブをすべて外し、USBからMemTest86を起動し、テストの選択でTest3とTest6-7が通ってからWindowsに切り替えることをおすすめします。設定が甘いとMemTestのテスト6などでフリーズ・再起動が起きます。その後のOCが安定したかどうかの判断として、Prime95をいきなりFFTサイズ8192位から始めるとすぐに結果がわかります。逆にこれを30分くらいパスしたらもう大丈夫なのでは、と思います。
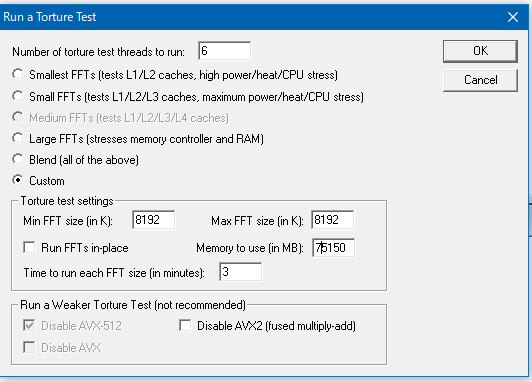
ヒートシンクにはCoolerMasterのMasterLiquid Lite 120を使いましたが、ラジエーターのファンを前後2枚取り付けているのが功をなしているのか5GHzでPrime95をかけ続けても熱暴走は起きませんでした。なのでこれで常用しようと思います。殻割りしてヒートスプレッダ交換などをすればもっと冷えると思いますが、そこまでする気力は起きませんでした。
ネットワーク周り
ネットワークにはAQtion AQN-107とIntel 219-Vの2系統を備えています。以前の構成でもMellanoxのConnectX2-ENをLAN、I210を内部マネジメント系として使っていたので、ほぼそのままその構成で行けそうです。ただ、10G-Tネイティブのスイッチはないので、mikrotikのS+RJ10でSFP+変換をかませることにしました。これ結構発熱するのでちょっと不安なんですけどね…。スイッチからは10G固定で見えるのに10G-T側は5Gや2.5Gや1Gでもリンクするという謎技術です。溢れた分はどう制御してるんですかね?まあ安いので1つ2つ持っておくのはおすすめです。

また、AQN-107の内部接続がPCIE 3.0のx2接続(計算上は16Gbpsですが)、及び10G-Tを使うというのがどうなのか、というのが不安でしたが、とりあえずは問題ないようです。距離も3Mくらいしかないのでその距離ならそのへんのケーブルでも大丈夫そうです。
一つハマったのが、IntelのPROset/Advanced Networking Servicesを入れれば、昔はNICの「構成」タブからVLAN/Teamingの項目に飛べたのですが、1903だとその項目がなく、PowershellのAdd-IntelNetVLAN コマンドレットから設定する必要がありました。どうも1809あたりからそうなったようですが、謎です。ただ、こちらのほうがまとめて作れるので楽でした。
PS C:\WINDOWS\system32> Get-IntelNetAdapter
Location Name ConnectionName LinkStatus
-------- ---- -------------- ----------
0:31:6:0 Intel(R) Ethernet Connection (7) I219-V 1.00 Gbps ...
8:0:0:0 Aquantia AQtion 10Gbit Network Adapter LAN 10.00 Gbps...
PS C:\WINDOWS\system32> Add-IntelNetVLAN -ParentName "Intel(R) Ethernet Connection (7) I219-V" -VLANID "0,2,3,6"
安定性
台風の後のゲリラ雷雨でUSP保護してなかったためシャットダウンされましたが、それ以外は5GHz運用で問題ないです。ゲームも連続で6時間ほどやりましたが大丈夫でした。
総評
総じてオタク向けです。POSTは一般的なuEFIマザーに比べ長い、OC項目は複雑、ファームのアップデートは(なれてない人にとっては)複雑、etc…。ただ、ブロックダイアグラムを見てそのキモさにシビレたり、フルサイズDPポートが2ポート必要だったり、x8接続の拡張ボードを数本接続する必要があったり、U.2ドライブを使いたいという需要がある人にはおすすめです。オンボードでU.2ドライブや10G問題やサブディスプレイ問題を解決してしまったので、結局接続されているボードはグラボだけになりました。とてもスッキリしました。

U.2の起き方が雑とか管理面で上下逆にしてるとか色々突っ込みどころはありますが動いて冷えればいいのです。しかし、この構成をしたがる層ってどう見てもゲーミングなんちゃらを欲しがる層じゃないよな…と強く思います。HW的に詳しくない、自作歴がそこまで長くない、という人にはおすすめしません。ですが、安定性も悪くなく、一部の層にとってはどストライクな構成なので、そういった方には他に選択肢がないのでおすすめです。
以上
[ コメントを書く ] ( 1392 回表示 ) | このエントリーのURL |
なんだかんだ長くこのブログも動いているのですが、中のOSが古くなってきたので新しくしました。もともとは物理マシンでDebian 6(の超初期版)が動いていたのですが、VM環境ができあがりつつあったのでイメージをddでVMに持ってきて、その後式年遷宮(新規VM作成後にコンテンツコピー)でDebian7に移行しました。その後dist-upgradeでDebian8までは持ってきたのですが、OSデフォルトのPHPのバージョンアップ等の絡みでそのまま塩漬けになっていました。
しかし、7から移行した関係でApacheのバージョンが2.2のままだったので(果たして8になったと言えるのか…)いい加減新しくしたいと思っていたのですが、家で動いているZabbixも7から9に移行しようとして失敗したのでdist-upgradeはやめ、環境が古すぎてなんで入っているのかわからないパッケージやもはや使ってないDBなどもあり、この辺をきれいにする意味も兼ね、今年7月に出たDebian10の評価を兼ねてまた式年遷宮しました。
ちなみにZabbixマシンもMySQLのダンプを吐いてまっさらなDebian9のVMにインポートし、Zabbix-server周りの設定だけよしなに変えて式年遷宮しました。MySQLからMariaDBに変わったり、昔から残ってるinitスクリプトとsystemdの関係がうまく行かなかったりしてdist-upgradeで色々つらい感じになりました。
ただ、Debian10のマシンにそのままコピーだと(シンプルな作りのこのブログシステムであっても)いくつかPHP7で廃止された関数を使われていた関係で500が帰ってきてしまい、それを直したりデザインを少し変えたりしたらなんだかんだで丸2日くらいかかってしまいました。
とりあえず表面上は動いているのですが、何が問題が出そうで怖いです…
[ コメントを書く ] ( 883 回表示 ) | このエントリーのURL |
Zen2なプロセッサやXeon Wなど、いろいろ新しいプロセッサが出ていますが、前回の構成からそれらに乗り換えてどこまで変わるか(今の構成でどこが不足しているか)という現状把握を確認しようとメモリの帯域やQPIの使用状況を見ようと思ったのですが、Windows標準にはそのような仕組みはありませんでした。
そのかわり、IntelからPCM Toolsというものがリリースされていて、これを使うとパフォーマンスカウンタでは見えない部分を見ることができます。ただし、プレビルドのものは配布されていないので自分でコンパイルする必要があります。
最初はVS2019でコンパイルしようとしたのですがthr/xthreadが存在しないためincludeできないと言われうまく行かず(たしかに探しても見つからない)、いろいろ試してもVS知識がなくてわからず、結局VS2017でコンパイルしたらうまくいきました。
自分用のメモとしてビルドのものを置いておきます。
PCM_201902 release.zip
ビルドするとpcm_*.exeという実行ファイルがいくつかできるのですが、有用だったのでいくつか紹介してみます。
PCI-Eの使用状況がわかるpcm-pcie
pcm-pcie.exeを実行すると以下のような出力があります。
.\pcm-pcie.exe
DEBUG: Setting Ctrl+C done.
Processor Counter Monitor: PCIe Bandwidth Monitoring Utility
This utility measures PCIe bandwidth in real-time
PCIe event definitions (each event counts as a transfer):
PCIe read events (PCI devices reading from memory - application writes to disk/network/PCIe device):
PCIePRd - PCIe UC read transfer (partial cache line)
PCIeRdCur* - PCIe read current transfer (full cache line)
On Haswell Server PCIeRdCur counts both full/partial cache lines
RFO* - Demand Data RFO
CRd* - Demand Code Read
DRd - Demand Data Read
PCIeNSWr - PCIe Non-snoop write transfer (partial cache line)
PCIe write events (PCI devices writing to memory - application reads from disk/network/PCIe device):
PCIeWiLF - PCIe Write transfer (non-allocating) (full cache line)
PCIeItoM - PCIe Write transfer (allocating) (full cache line)
PCIeNSWr - PCIe Non-snoop write transfer (partial cache line)
PCIeNSWrF - PCIe Non-snoop write transfer (full cache line)
ItoM - PCIe write full cache line
RFO - PCIe partial Write
CPU MMIO events (CPU reading/writing to PCIe devices):
PRd - MMIO Read [Haswell Server only] (Partial Cache Line)
WiL - MMIO Write (Full/Partial)
* - NOTE: Depending on the configuration of your BIOS, this tool may report '0' if the message
has not been selected.
Starting MSR service failed with error 2 Trying to load winring0.dll/winring0.sys driver...
Using winring0.dll/winring0.sys driver.
IBRS and IBPB supported : yes
STIBP supported : yes
Spec arch caps supported : no
Number of physical cores: 16
Number of logical cores: 32
Number of online logical cores: 32
Threads (logical cores) per physical core: 2
Num sockets: 2
Physical cores per socket: 8
Core PMU (perfmon) version: 3
Number of core PMU generic (programmable) counters: 4
Width of generic (programmable) counters: 48 bits
Number of core PMU fixed counters: 3
Width of fixed counters: 48 bits
Nominal core frequency: 3300000000 Hz
IBRS enabled in the kernel : no
STIBP enabled in the kernel : yes
Package thermal spec power: 130 Watt; Package minimum power: 68 Watt; Package maximum power: 200 Watt;
ERROR: QPI LL monitoring device (0:7f:8:2) is missing. The QPI statistics will be incomplete or missing.
ERROR: QPI LL monitoring device (0:7f:9:2) is missing. The QPI statistics will be incomplete or missing.
Socket 0: 1 memory controllers detected with total number of 4 channels. 0 QPI ports detected. 0 M2M (mesh to memory) blocks detected.
ERROR: QPI LL monitoring device (0:ff:8:2) is missing. The QPI statistics will be incomplete or missing.
ERROR: QPI LL monitoring device (0:ff:9:2) is missing. The QPI statistics will be incomplete or missing.
Socket 1: 1 memory controllers detected with total number of 4 channels. 0 QPI ports detected. 0 M2M (mesh to memory) blocks detected.
Detected Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz "Intel(r) microarchitecture codename Ivy Bridge-EP/EN/EX/Ivytown" stepping 4 microcode level 0x42c
Update every 1 seconds
delay_ms: 54
Skt | PCIeRdCur | PCIeNSRd | PCIeWiLF | PCIeItoM | PCIeNSWr | PCIeNSWrF
0 507 K 0 0 0 0 0
1 168 0 0 1080 0 0
-----------------------------------------------------------------------------------
* 507 K 0 0 1080 0 0
Skt | PCIeRdCur | PCIeNSRd | PCIeWiLF | PCIeItoM | PCIeNSWr | PCIeNSWrF
0 501 K 0 0 0 0 0
1 552 0 0 12 0 0
-----------------------------------------------------------------------------------
* 501 K 0 0 12 0 0
....
最初は各値が何を意味しているのかわかりませんでしたが、よく見ると実行すると最初に出力されるところに意味が書いてありました。気にするべきは PCIeRdCurとPCIeItoMで、PCIeRdCurはPCIE→ CPU/メインメモリへの読み取り(ホスト側から見て書き込み)で、 PCIeItoMはPCIE→CPU/メインメモリへの書き込み(ホスト側から見て読み込み)のようです。
例として、ソケット2配下のPCIEに接続されているnvme(U.2フォームファクタ)へのベンチマーク中にとった値は、CDMの読み込みで1719MB/sと出ましたがPCMの方では23Mとなりました。
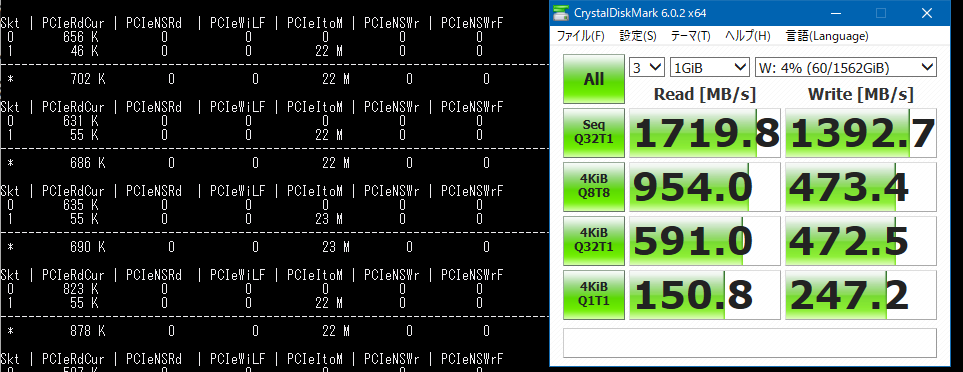
この23Mというのが何を意味しているかというと、1秒間に23M回要求があったということらしいです。これらからI/Oのサイズを求めると (1719.8 MB/s) / 23MHz となり、IOサイズは約74バイトという計算になります(計算はグーグル先生におまかせ)。
いろいろ調べると、PCI-EのパケットサイズはボードのTransaction Layer Packet (TLP)宣言によって16から4094バイト(2^4 -2^12) で送信できるらしいのですが、そうなると微妙に合いません。
逆に1719MB/sを64バイトで達成するには一秒間あたり26MHzの要求が必要になり、これもまた微妙に合いません。謎ですが、多分サンプリング間隔やCDMの帯域集計などのズレが有るのでしょう…。
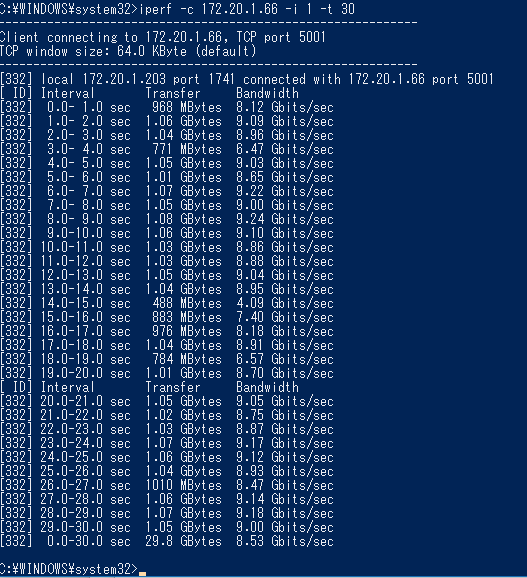
また、別のケースとして(これも余ったから)使用している10GカードのConnectX2-ENから別の物理マシンへiperfしたところ、 8.25 GBytes (7.08 Gbits/sec)の速度が出たのですが、この際のpcm-pcieの値は以下のようでした。
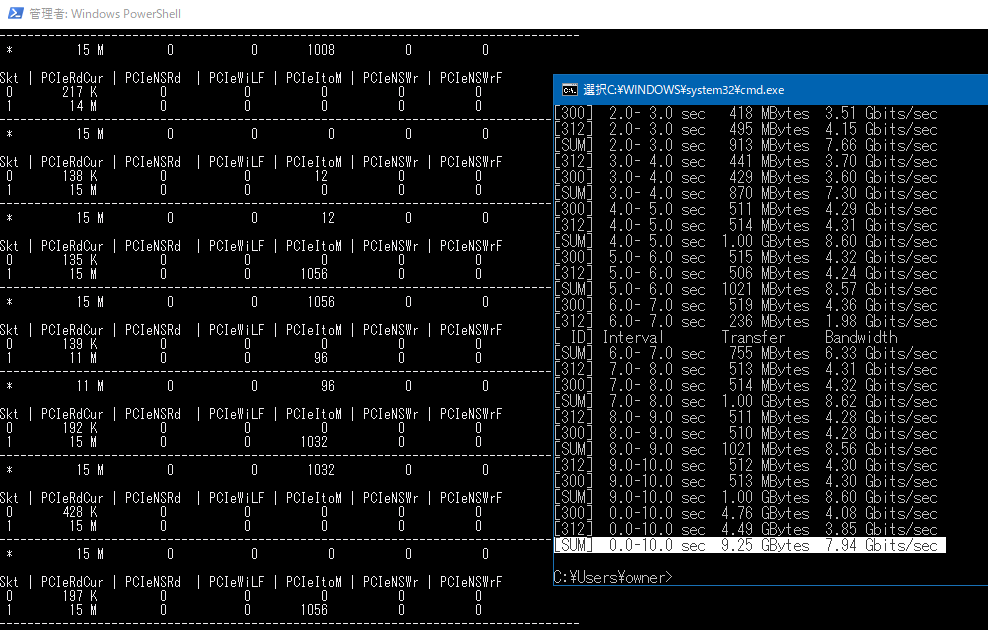
これに64バイトをかけると15MHz*64Byte=7680 Mbpsとなり、やはり近い値が出ているようです。
X9DAiのマニュアルによると、パケットサイズを256byte、ReadReqデータサイズは4kまで拡大できるらしいのですが、これを拡張しても特に要求回数が減ることはなかったので謎です。Linuxではlspciコマンドをvvvなどで実行すると出てくるDevCapがカード自体のケーパビリティ、DevCtlが実際にネゴシエートしている値として取得できるのですが、Windows上ではどのように動いているか不明です。逆にLinux上では64バイトという値はなかったので本当にこの計算があっているのか不安です…。
参考:
https://community.mellanox.com/s/article/understanding-pcie-configuration-for-maximum-performance#jive_content_id_PCIe_Max_Payload_Size
ちなみに、この確認の中で知ったのですが、X9DAiは各スロットでx16をx4x4x4x4などへ分割するPCIE Bifurcationに対応していたので、x16スロットにASUSのULTRA QUAD M.2 CARDのようなPLXのスイッチングチップを持たないnvme4枚刺しのカードを刺しても使えるようです。おそらくもともとはライザーカード対応のための機能だと思いますが…。
使用中のメモリ帯域がわかるpcm-memory.exe
このプログラムはなかなか有用で、チャンネルごとのメモリ帯域がわかります。
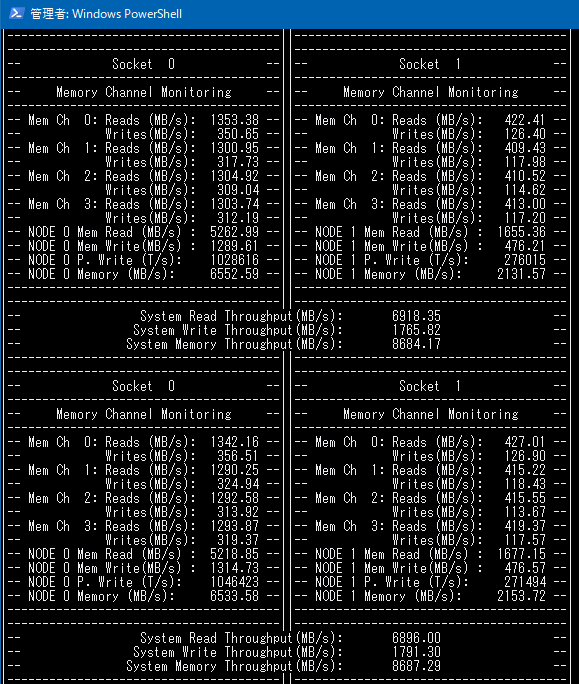
メモリ帯域のベンチマークを回すとシングルスレッドで12GB/s、4チャンネルあるのでマルチスレッドでコアあたり48GB/s、ソケット合計88GB/sという速度が出ましたが、ゲームをやっている限りせいぜい7-9GB/s程度の要求だったのでメモリ帯域についてはまだボトルネックではないということがわかりました。
メモリ帯域などをパフォーマンスモニターで見られるPCM-Service.exe
pcm-memory.exeをパフォーマンスモニターのグラフで見るためのサービスです。管理者権限でPCM-Service.exe -InstallでインストールするとProcessor Counter Monitor Serviceというサービスが追加され、これを開始するとパフォーマンスカウンターにPCM_*が追加されます。
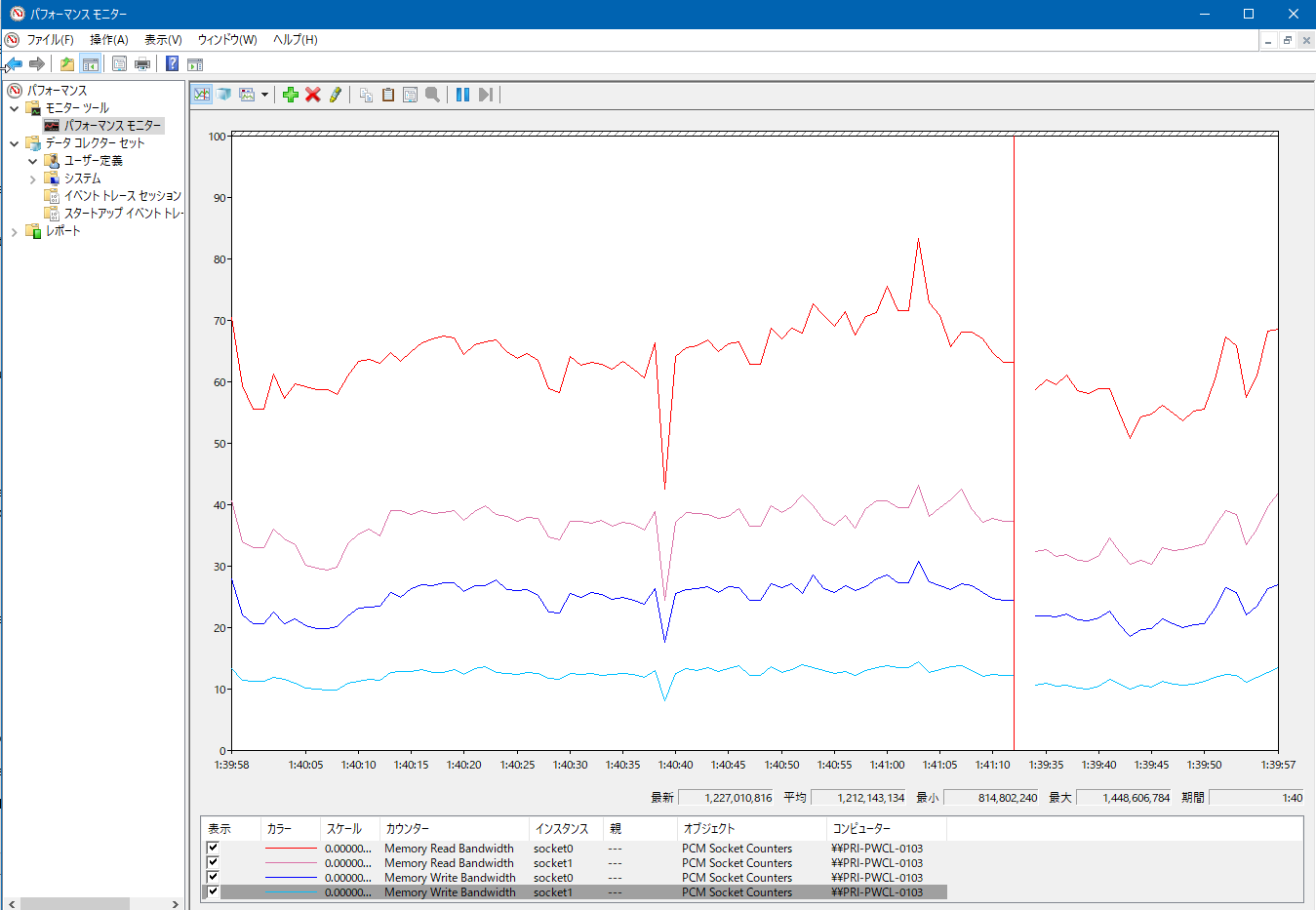
これらのパフォーマンスモニタリングから、最終的な結論としてXeon E5 2667v2は足回りはまだ余裕があるもののコアあたりの性能をあげないとゲームにおいてより良いパフォーマンスを得られないということがわかりました。感覚的にわかっていましたが…。
ただ、Zen2やCore i7系のCPUだと、使っているインターフェースカード的にPCIEのレーン数が足りないので、その点QPI跨いでしまってもレーン数の多いE5系は使いやすいんですよね…。
レガシーハードウェアが多いのでPCIE4.0を3.0にダウングレードしてそのかわりレーン数を倍にするスイッチングチップなどがあると嬉しいのですが、そんなニッチなものが売れるとは思えないですし、コスト的にも割に合わないと思うので厳しいです。Xeon Wシリーズがほしいのですが高い…。
人間は迷うと現状維持を選ぶらしいですが、今回もそうなりそうです。
[ コメントを書く ] ( 735 回表示 ) | このエントリーのURL |

家の環境は所有しているメモリの量の問題で未だにXeon E5 v2環境から移行できないのですが、同じラインのCPUを長く使っているとアップグレードや筐体目当てのパーツ取りなどでサーバを買ったりして余剰パーツが増えた結果、使ってない資材同士が結合して新しいマシンが生えてきたりすることはよくあることだと思います。(そして日常的にハードウェアを入れ替えてると配線の綺麗さとかどうでも良くなってきて写真のような配線になります)
そんなわけで、余ったパーツから生えてきたマシンを現在デスクトップ機として使っているのですが、2ソケットマシンをデスクトップ用途として使うとちょくちょくNUMAについて考えないといけない時があったのでまとめてみます。
環境
余ったパーツから生えてきたマシンは以下です。
マザボ X9DAi
CPU Xeon E5 2667v2 *2
メモリ DDR3 14900R 8*16 =128GB
グラボ GTX 1080
その他NVMeとか10G-NICとか
マザボについてはオークションで安かったので買ったのですが、サーバー用途で使おうとするとIPMIがないのはやっぱり使いにくいので結局本番稼働することなく部屋の隅に積まれていいました。
しかし、Core i5 6600Kでマシンを組んだときに微妙に物足りなかったので、試しにX9DAiと余り物でデスクトップ環境を作ったらいい感じだったのでそのままこれを使っています。
この環境を使っていても9割のことは困らないのですが、ゲーム時にパフォーマンスがばらつく時があったので、その対処法のメモです。
システムブロック図
Xeon E5系/Ryzenから先はPCI-EがCPU直結になり、(AMD系ではThreadripper/Epicは)拡張スロットによって接続先のCPUが違う(AMDの場合はMCMのコアが違う)というのはパソコンオタクには常識だと思いますが、X9DAiのシステムブロック図は以下のようになっています。
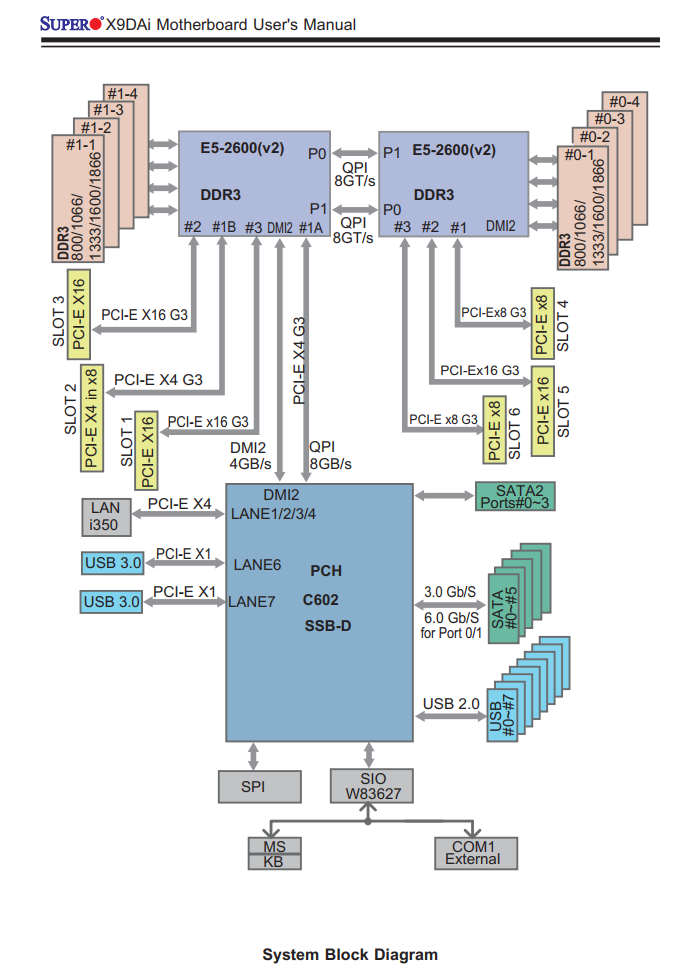
このことを意識してゲーム用GPUをCPU1に直結しているSlot1のPCIEx16に接続していたのですが、Windows/Linuxどちらであっても「実行するプロセスの使用する拡張ボードを考慮して」のNUMAの制御は今の所できません。
そのため、CPUの混み具合によっては「本来ならCPU1で実行してほしいのにCPU2で実行されてしまって拡張ボードにアクセスするにはQPI/Infinifablicを跨いでCPU1経由でアクセスしなければならない」ということが起きます。
Xeon 5600系まではどちらのCPUであってもPCH経由でPCI-EにアクセスしていたのでどちらのCPUもどのボードに同じコストでアクセスできたのですが、QPIの限界が来てしまったのでCPUに直結された結果、このような微妙に不便なことが起きます。
Windows10でのNUMA
Windows10でもNUMAを意識してくれるのですが、だいたい重要なプロセスがCPU1で実行されるため、ゲームなどは空いていることが多いCPU2で実行されてしまいます。しかし、そうなってしまうとGPUからは遠くなってしまうので、できればCPU1側で実行してもらいたいのです。
見ている限りだと、CPU1とCPU2両方をフルに使って実行されるゲームはなく、すべてのコアで実行を許可しても、どちらかのCPUのすべてのコアのみで実行されていました。
CPU affinity
もともとはNUMAの出始めの頃のサーバープロセスやDBプロセスのパフォーマンスチューニング手段でしたが、現在でも40GbE/100GbEなどの広帯域インターフェースを使う際にインターフェースに近いCPUでの実行を強制するために有効です。
ちなみに、現在のOSは賢いので極端なプロセスでなければ設定しなくてもNUMAノードのCPUやメモリの空き状況を見て、余裕がある方によしなにNUMAをまたがないようにプロセスを振り分けてくれます。
ゲームプロセスにCPU affinityをかけたい
プロセスのアフィニティー自体はタスクマネージャーの詳細の中にある「関係の設定」より簡単にかけることができるのですが、ゲームプロセスなどの場合、チート防止などの理由により起動後にアフィニティーを変えることができないことが多々あります。
その場合どうすればいいかと実験したところ、アフィニティーがかかったプロセスから子プロセスを実行するとアフィニティーが伝搬するので、steamなどを
start /affinity ffff steam.exe
で呼び出し、その伝播したSteamから更にゲームを実行すると最初からアフィニティーがかかった状態でゲームを開始できるようです。
しかし、これでうまくいくものもあればメニューの変なところで止まるものもあったため、結局Steamにアフィニティーをかけるのはやめました。
CPU2を混雑させたい
ゲームにアフィニティーをかけるのが問題であれば、自動選出の結果CPU1が優先的に選ばれるようにしたいので、逆にゲームに関係しないどうでもいいプロセスをCPU2側で実行させて意図的にCPU2を混雑させることにしました。
十進数でアフィニティーを確認する
このあとのPowershellでまとめてアフィニティーを設定したいので、まずnotepadなどを起動し、タスクマネージャーからCPU2を使うように手動でチェックを入れ、アフィニティーを設定します。
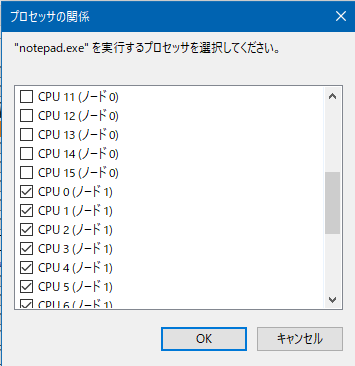
CPU2(ノード1)側をすべて使用するように設定したら、PowerShellでアフィニティーの値を取得します。もちろん関数電卓で直接やってもいいのですが、間違うことがあるのでこの方法が楽です。
PS W:\> Get-Process notepad|Select ProcessorAffinity
ProcessorAffinity
-----------------
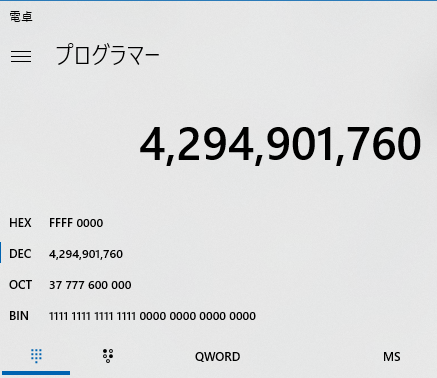
4294901760
4294901760というのは32スレッドのうち、奥の16スレッドを使用するという定義で、関数電卓に入れバイナリ値を見るとわかりやすいです。
ちなみに、PowerShellだとアフィニティーの指定は10進数ですが、start /affinityだと16進数になるので、古くからあるstartコマンドで同じことをしようとすると
start /affinity ffff0000 otepad.exe
になります。
邪魔なものをどかす
これから実行するプロセスをすべて特定のアフィニティーをかけて実行したい場合、まずcmd.exeをアフィニティーかけた状態で立ち上げ、一度explorerを taskkill /im explorer.exe /fなどで殺したあと、explorerと実行するとcmd.exeにかかっていたアフィニティーでデスクトップ環境が立ち上がります。
そのエクスプローラから実行されたプロセスもアフィニティーが伝搬していくので、デスクトップのアイコン等をクリックして実行してもアフィニティーがかかった状態で実行されていきます。
停止できないプロセスについては、管理者権限で実行したpowershellで
foreach($p in "SearchIndexer","OfficeClickToRun","sqlservr","sqlwriter"){ ForEach($PROCESS in GET-PROCESS $p) { $PROCESS.ProcessorAffinity=4294901760} }
などと実行するとアフィニティーをまとめて変更できます。ただ、svchostやdwmなどはアフィニティーをかけるとOSが不安定になることがあるので、変更しないほうが良いようです。また、CrystalDiskMarkなどもアフィニティーがかかっている状態だと正しく実行できませんでした。
また、どのコアでどのプロセスが暴れているかを見つけるには Process Explorer を使うといい感じに見つけられます。
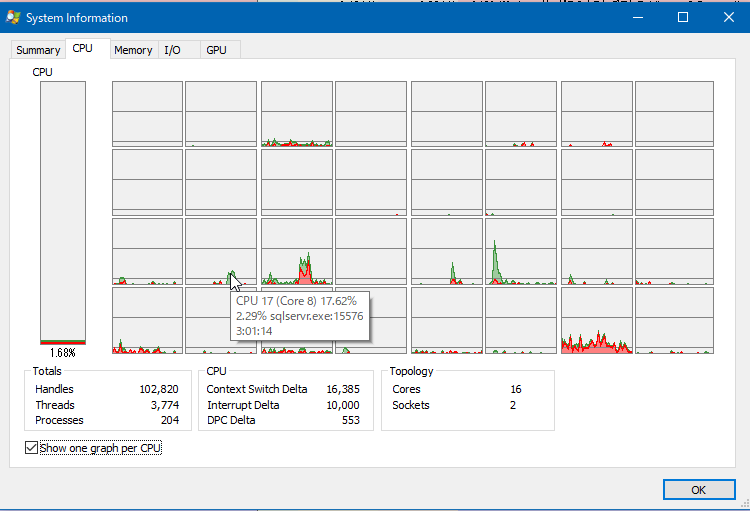
大体の場合、ブラウザ(ChromeやFirefoxなど)をCPU2側で実行しておけば(特にマシンをシャットダウンせずに放置するような環境の場合)メモリ使用量などの関係で「CPU2は混んでいる」となるようです。
ゲームを実行してみる
アフィニティーのかかっていない状態のSteamなどからゲームを起動します。その後、CPU1側が優先的に使われるようになったら成功です。
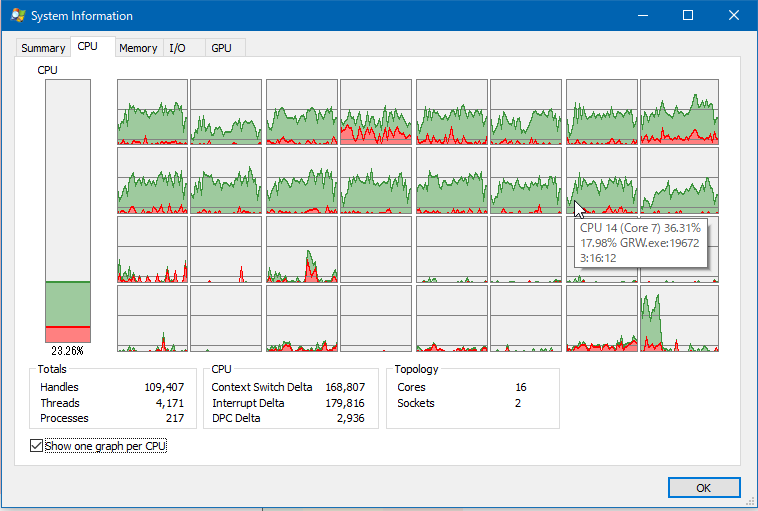
それでもまだCPU2が使われる場合はCPU2のしばきが足りないのでいろいろ実行してください。
CPU2側でゲームを実行されると、特にオープンフィールドなゲームでマップが広くメモリ使用量が多いゲーム(GRWとかArkとか)を実行すると、CPU2側からQPI越しにGPUになんか転送してるんだろうなというような一瞬のフリーズが起こることがちょくちょくありました。しかし、CPU1側で実行を強制するとそれがだいぶ軽減されました。
また、ブラウザをCPU2側で実行するとどれだけブラウザが重くなってもゲームに影響しないので、それはそれで2ソケットの使い分けとして便利な気がします。
そもそもXeonはゲームするようなプロセッサではないというのは尤もですが…。
マシンを新しくしようかどうか悩むところです。
[ 2 コメント ] ( 3024 回表示 ) | このエントリーのURL |
前回のエントリでHCAより先にPCI-Eの帯域が限界に来ていたことに気がついたので、HCAを2枚使ったらどうなるかをテストしてみました。今までDualportでもまあこんな速度かと思っていたのですが、よくよく考えたらPCI-Eがネックになっていたという…。SRP自体使い始めてからかれこれ5年ほど経過しますが、ほぼ情報がない(≒誰ももう使ってない)ので悲しみと今後iSERを使ったときの比較用のメモとして残します。
セットアップ
テスト環境はこんな感じです。

ストレージサーバ RX300S7
CPU Xeon E5 2643*1
Mem 8GB*8 at DDR3 1600MHz
Drive SanDisk Optimus Ascend 800GB *10 /RAID5 for Data (PN:LN0800FEHDC)
RAID HBA D3116C (MegaRAID SAS 2208@PCI-E 3.0)
IB HCA MT26428 (Connect-X2 VPI Single Port QDR) *2@PCI-E 2.0
Target SCST Version 3.4.0 from git repo
LIOでもSRPターゲットを作れますが、負荷が1つのコアに集中する、たまに刺さる、認証なしのターゲットが作れないといったことを経験したのでSCSTを使っています。SCSTは非常に安定していて、3-4年位使っていますが問題ありません。ストレージ側の設定はこんな感じです。
# cat /etc/scst.conf
HANDLER vdisk_fileio {
DEVICE dev-srp0 {
filename /vdisk/srp0.img
}
}
TARGET_DRIVER copy_manager {
TARGET copy_manager_tgt {
LUN 0 dev-srp0
}
}
TARGET_DRIVER ib_srpt {
enabled 1
TARGET fe80:0000:0000:0000:0002:c903:000f:41a7 {
enabled 1
rel_tgt_id 1
LUN 0 dev-srp0
}
TARGET fe80:0000:0000:0000:0002:c903:000f:8395 {
enabled 1
rel_tgt_id 2
LUN 0 dev-srp0
}
}
仮想ホストの環境は以下です。SRPを使う手順はこちらを参考にしてください。
DL380p gen8 ESXi 6.5

CPU Xeon E5 2667v2 *2
Mem 16GB*16 at 1333MHz
IB HCA MT26428*2 (Connect-X2 VPI Single Port QDR)
仮想マシン
Windows 10 x64 Pro 1809
vCPU 4
Mem 6GB
ベンチマーク用のディスクには準仮想化SCSIコントローラーを使
この状態で、ディスクへのパスを切り替えてテストします。 テストには最初 IO Meterを使おうと思ったのですが、パラメーターによって大きく値が変わってしまうので再現性のあるCrystalDiskMark6.0を使用しました。
ストレージ接続*1本
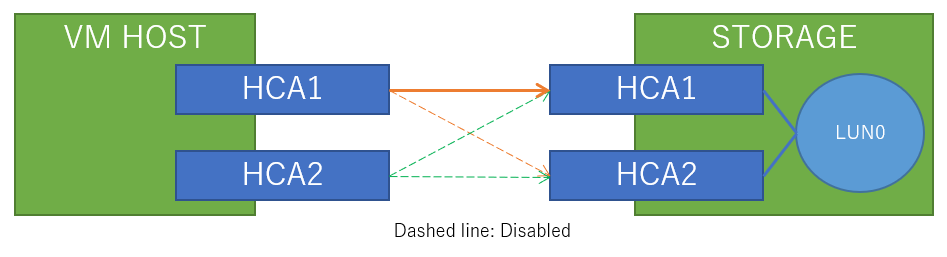
まずは、1ポート接続でテストします。
接続図はこんな感じです(途中のIBスイッチは省略)
その結果が以下です。
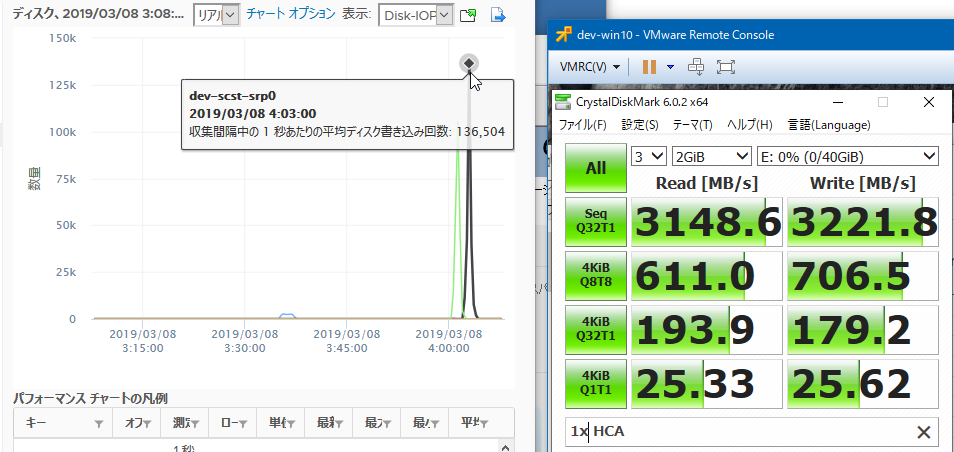
読み、書きともに120-130kIOPSで、帯域は3148MB/sでした。
ストレージ接続*2本
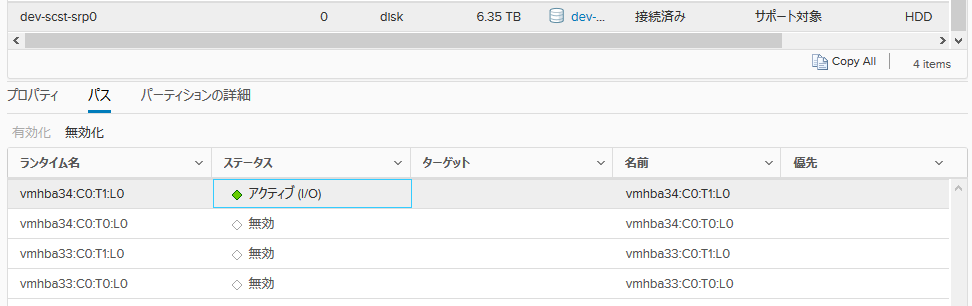
次に、接続を増やしてテストします。ラウンドロビンの切り替えは1IOごとに行う設定にします。
esxcli storage nmp satp rule add -R gsan -s VMW_SATP_DEFAULT_AA -P VMW_PSP_RR -O iops=1
設定ははこうなります。
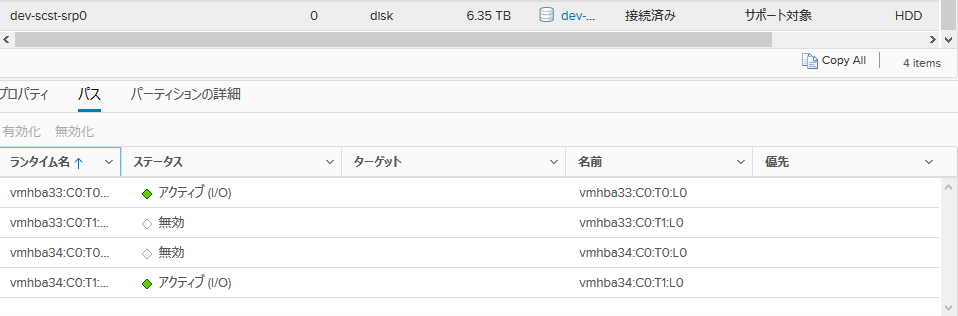
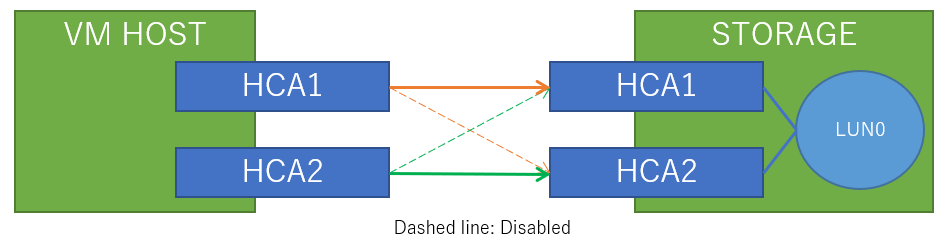
接続図はこんな感じです(途中のIBスイッチは省略)
その結果です。
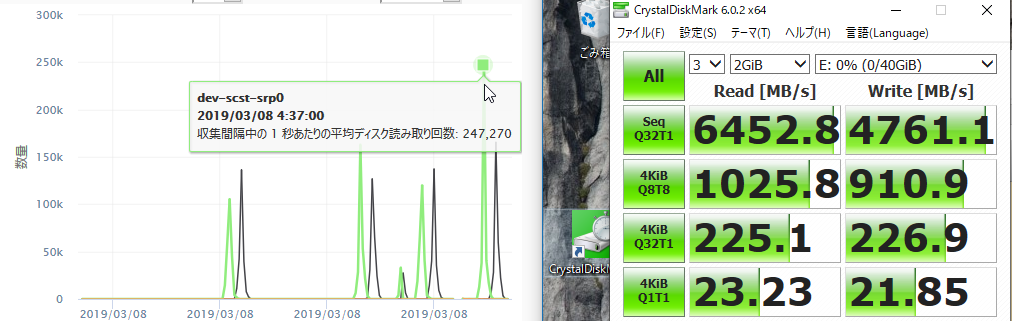
読み込み250kIOPS、書き込み150kIOPS出ました。また、帯域は読み込みに関してはきれいに2倍にスケールしました。いくらほぼストレージサーバのRAMへの読み書きとはいえ、びっくりするほど速いです。こんな速かったのか…。
また、読み込み250kIOPS時のストレージサーバの負荷はこんな感じでした。
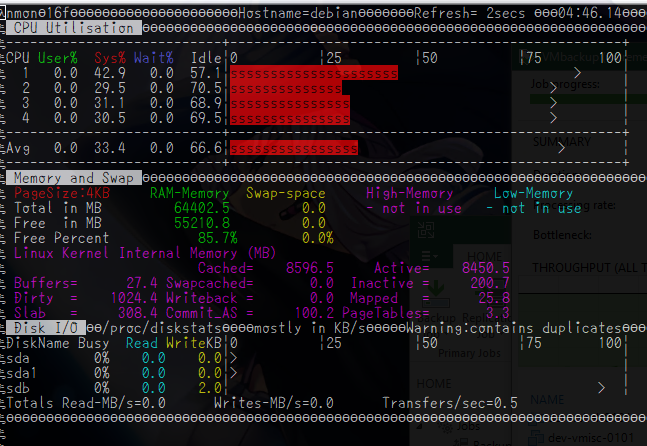
何かのエージェントで監視しているわけではなくnmonで見ていましたが、これより大きく外れることはありませんでした。
まとめ
SRPはもはや旧世代なハードウェア、かつ4コアという、今となっては非力な環境でもかなりの性能を発揮できました。もちろん、搭載しているRAMがちょっと多いのでDirtyやキャッシュの助けもありますが、nvmeのような高速なストレージを使ってもSRPはネックにならないというのはかなり強いです。
とはいえ、これを目当てに今からInfinibandを入れるのは、サポートの切れたConnect-X2からCX3世代をサポートの切れたドライバで動かすという、あまりにも将来性がない構成になるのでおすすめしません。
iSERは試したことがありませんが、原理としては同じなので今からやるならせめて40GbEのiSERでしょうか。100GのiSER環境も試してみたいのでどこかにスイッチとNICが転がってないかなと思う日々です。
早くこれよりも超高速なストレージを見つけて将来性のあるモダンな構成に移行したい…
[ コメントを書く ] ( 1131 回表示 ) | このエントリーのURL |
<<最初へ <戻る | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 進む> 最後へ>>