一応、1Gの線は引いているのですが、19時前後では
http://beta.speedtest.net/
のSoftEther社を選んでも大体3-50Mbps程度で、午前3時4時に同じく実行すると上下500Mbps程度出たりします。1G線を引いた直後はそれなりに速かったのですが、最近になって速度低下が目立つようになってきました。PPPoEの収容が限界に近いという話もあり、そろそろつらい感じです。
生活LANの午前3時頃の速度です。
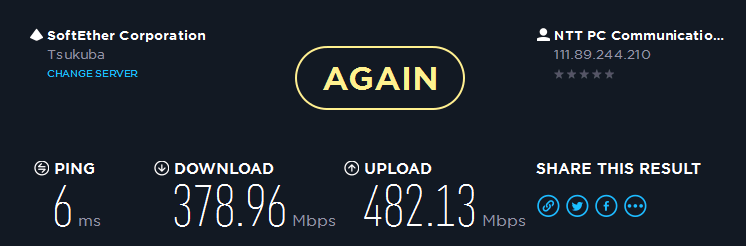
同日の午後19時頃の速度です
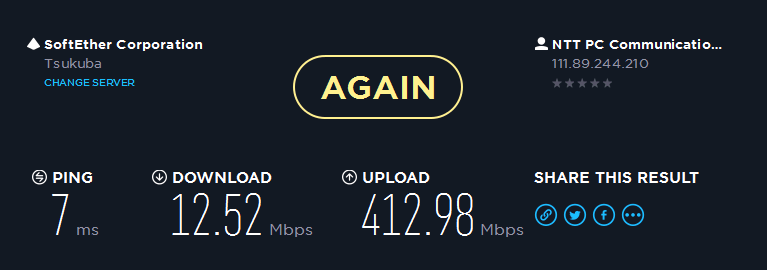
中々にひどい
某所でv6のIPIPトンネル張ってあれこれしようという話もあったのですが、残念ながらひかり電話が必要なため、NGN網内IPv6が受けられず、この方法は断念しました。
そんなところにNuroを500円で体験できるワンコイン体験キャンペーン(すでに終了してます)があったので申し込んでみました。が、開通まで1ヶ月以上要しました…。
開通までの苦痛
新規で申し込むにあたり、ページにあるように
1 宅外FCキャビネットから宅内へのファイバ引き込み (So-net施工)
2 電線からFCキャビネットへのファイバ引き込み (NTT施工)
という2ステップの工事があり、2回の日程調整および立ち会いが必要になります。
1回目のSo-net側の工事は問題なく終わったのですが、2回目のNTT側の工事で問題が起きました。宅内工事の際に、次回訪問日程の確認を行い、同意を得たはずだったのですが、当日19時になってもNTTが現れませんでした。
19時はさすがに遅すぎると思いSo-netのサポートセンターに連絡したところ、申し込みの際に自宅の住所を「東京都千代田区千代田1-1-1」といった住所をハイフン抜きで入力してしまい、「東京都千代田区千代田111」と入力してしまったため、NTT側から「そんな住所ねえよ」と差し戻しを食らっていたとのことでした。
1回目の訪問が(おそらく施工者がよしなに解釈してしまったが故に)問題なく行われていたため、まさか入力ミスがあるとは気がつきませんでした。
確かに自分の非ではあるのですが、そもそも何故リジェクトされた時点でこちらに連絡をしないのか、NTTも郵便番号が入ってるのだからそれくらい分かるだろこのクソ役所ども…という黒い気持ちを抑え、とりあえず内容を修正してもらい、いつ頃なら予定が取れるかという折り返しの連絡をしてもらうことにしました。ここで1週間のロス。
そして連絡を待つこと4日…未だに連絡が来なかったので、さすがに遅すぎると再度サポートセンターに電話をしたところ、「大変申し訳ありません。こちら予約の取得が可能となっておりました。最短1週間後から取得可能となっておりますが、いかがなさいますか?」との返答。
わーーー!!御社には引き継ぎと社内コミュニケーションが苦手なフレンズ し か いないんだね!!!!くそーーーーーい!!! ほんまつっかえ…
こちらから連絡しなかったら永遠に来なかったのではないでしょうか…まあSo-netに多くのことを期待することがそもそもの間違えであり、経験上過去にも実績(悪い意味で)があるので、納得は出来ます。
また、サポートセンターに繋ぐ際には非常に長くの時間「ただ今混み合っているので少々お待ちください」の自動音声を聞く必要がある為、スピーカーホンにしてしばらく電話を放置する必要があります。SIPサーバやVoIP機の音声の途切れや揺れなどを確認するためのベンチマークの電話先としてはいいかもしれません。
まあ、そのレベルで人的資源が足りていないと言う事なのでしょう。
結局、宅外工事は申し込んでから1ヶ月以上経ってようやく完了しました。
開通後の苦痛
NuroではGPONがグローバルIPをもつ仕様となり、配布するのは基本的にローカルIPのみと言うことは把握していたので、前もって今のネットワークを大きく変更しないでGWを追加するためのセグメントを作成していました。しかし箱を開けてみてびっくり、渡されたHG8045Dが思っていた以上にクズでした。
VLANが切れないとかIPインターフェースを複数持てないとかは許せないながらも仕方ないとして、スタティックルーティングすらも切れないのです。2000円で買えるばっふぁろーのルーターやNTTから渡されるONUについているおまけルーターですらもその程度は出来るので、まさかこれができないとは思っていませんでした。
はっきり言って、HGWとして渡される何かは「でんきにつなげるとあったかくなるみどりいろにひかるゴミ」です。 既存の物があり、要件にも合わず、極力無駄なことをさせたくなかったので、無線も含めDHCPやDNSプロクシなど不要な機能は全て無効にしました。
せめてもの救いとしてはDMZ機能を持っているので、この「みどりいろにひかるゴミ」をどうにかするために既存のVMにNATをさせ、普段はそちらのVMをDMZとし、ポートフォワードなどの必要な機能はNAT-VMでどうにかすることにしました。pfsenseちゃんマジ天使
もっとも、固定IPオプション付きの法人向けのGPONはその下にDHCPでグローバルIPを払い出してくれるので、ある程度複雑なネットワークであればそちらにするべきだとは思います。費用的に個人で出すには少しつらいですが。
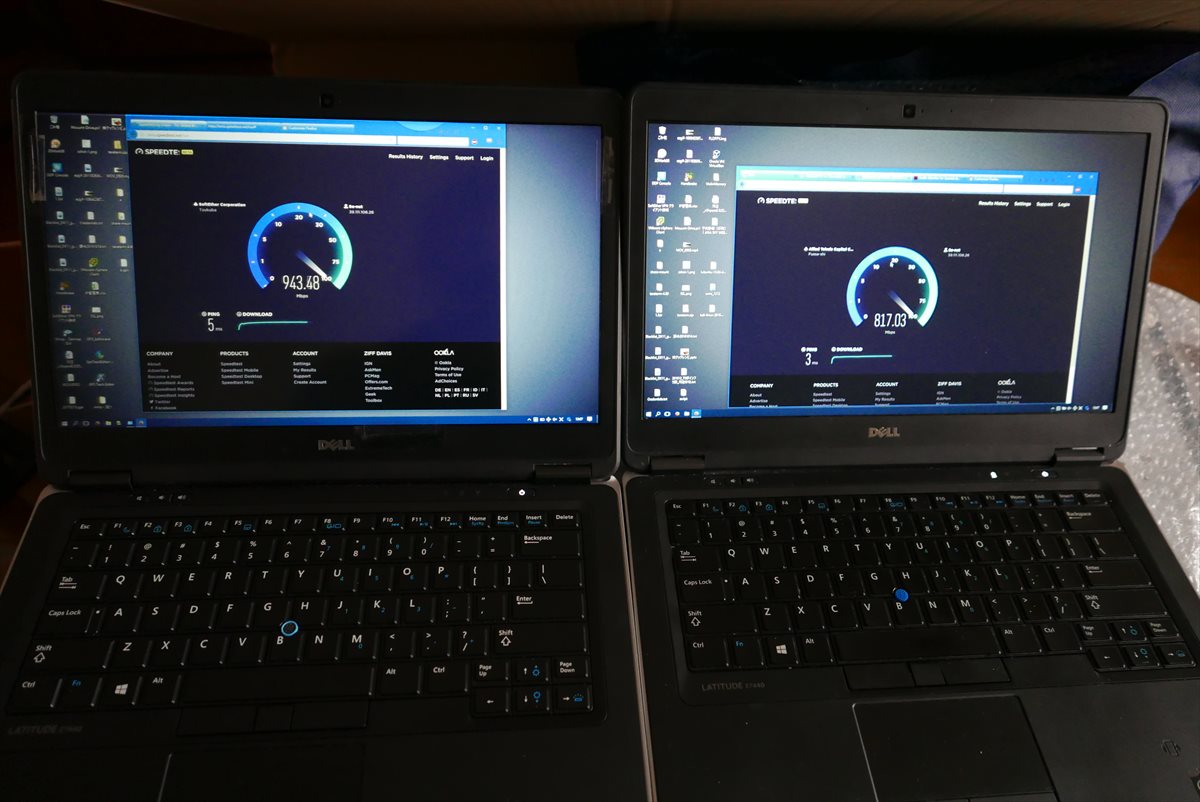
ひとつNuroの肩を持つとすれば、下り2Gbpsというのは確かにでます。2台のDell Latitude E7440(片方はCore i5 4510u/RAM16G、もう片方は4500u/8G)を「みどりいろにひかるゴミ」のLANポートにそれぞれ直接接続しスピードを測ったところ、タスクマネージャからみてもそれぞれで違うサーバから900Mbpsに近い速度はでていたので、たとえそれが速度測定サイトのみ加速する、いわゆる「チートブースト」であったとしても一応スペック通りと言えるとは思います。
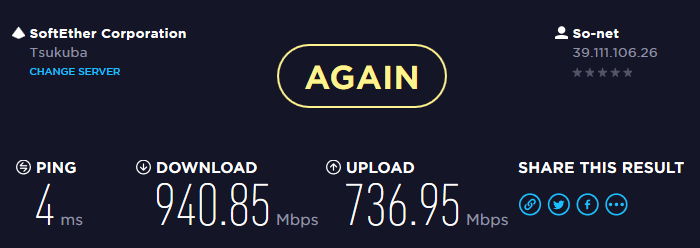
また、VMにNAT(宅内二重NAT)させたあとのスコアも、上りが若干落ちるものの十分な速度はでています。ショートパケットはどうだか分かりませんが。
では実際のところはどうか、となると、JAISTや理研などからDebianのISOを落とすときには大体3-400Mbps位になるので、まあそんなところです。
ただ、Flets側が腐る時間帯でもNuroでは大きな速度低下はないので、メリットはありました。
まとめ
・So-netに何か確認するときには自分から積極的に進捗に関して突っつこう
・ある程度複雑なネットワークがあると、渡されるHGWは「でんきにつなげるとあったかくなるみどりいろにひかるゴミ」
・ネットワークに関しては、「今のところは」悪くない
以上、愚痴でした。
[ コメントを書く ] ( 1705 回表示 ) | このエントリーのURL |

3年くらい前にRackSwitch G8124-EをeBayで仕入れ、しばらく使用していたのですが、あるときにファンの一つが故障し、それまで30%くらいで回転していたファンが全て減退運転に入り、全て80%くらいで回転するようになりました。それまでは結構静かだったのですが、さすがに小型ファンの高速回転はうるさく、部屋のノイズ主成分(音的な意味で)になっていました。
うるさい事と定期的にファン故障のトラップが飛ぶ以外は特に問題がないので(問題ですが)、故障後も放置してしばらく使っていましたが、運良く非常に安くApresia 130000が手に入ったので交換してしまいました。

燦然と輝く真っ青なスイッチに、VLANを使った程度のL2ネットワークをさせるだけではオーバースペック感ありますが、まあそれなりに静かでいい感じです。
その後、G8124は放置になっていたのですが、ふと直せるかどうか気になったのでふたを開けてみました。
壊れたファンはSUNONのGM1204PQV1-8Aと言うファンで、他のファンはUltraFlo W40S12BUA5-52なのですが、何故かこれだけSUNON製のものになっていました。元のオーナーが同じように手で直したのでしょうか…。

とりあえず、ファンの形状やコネクタは一般的なもののように見えたので、手元のゴミを漁ったら秋葉原でいつか役に立ちそうな気がして買った40ミリファンの連結した何かが出てきたので、それを分解して交換することにしました。

多分Supermicroの保守パーツ的な何かだと思いますが、もはやこれが何であってもどうでもいいです。

その中のファンにはSanAceの109P0412J3063が使われていました。むしろ他のも全てこれに交換してしまいたいレベルですが、とりあえず壊れた部分だけ交換します。
交換して、ひとまず動くか電源ON。起動しましたが、その直後異臭が立ちこめたので真顔で即座にACを引っこ抜きました。幸い、発煙や炎上はありませんでしたが、部屋がICを過電流で焼いたときの臭いで包まれました。この臭いほんとに嫌いです…(嗅ぐ羽目になったシチュエーションでは大体ああああああなことになってるので)
原因を確認してみると、コネクタは普通の3ピンなのですがアサインが違いました。これは死ぬ。何故確認しなかったし…。

解決策として、SUNON製のファンのコネクタを切り取り、綺麗な芋ハンダ(汚い)で直そうかと思いましたが、半田ごてをしばらく使っていなかったので引っ張り出すのがめんどくさくなり、その代わり手元にあったブレッドボード用のジャンプワイヤを使う事にしました。

その後おそるおそる起動してみると、とりあえずファンは順調に回っていたので、再び電源を落とし、ふたを戻しました。
ふたを戻したあと、起動してみると、普段はファン故障でファンの回転数は落ちないのですが、今回は無事に回転数が落ちました。ファンの全回転時と比べ、20Wくらいの差がありました。
コンソールに入ってみると、無事に回転数も取れていました。
RS G8124-E#show sys-info
System Information at 15:44:38 Mon Sep 5, 2016
Time zone: No timezone configured
Daylight Savings Time Status: Disabled
IBM Networking Operating System RackSwitch G8124-E
Switch has been up for 0 days, 0 hours, 12 minutes and 9 seconds.
Last boot: 15:32:42 Mon Sep 5, 2016 (power cycle)
MAC address: xx:xx:xx:xx:xx:xx IP (If 1) address: 0.0.0.0
MGMT-A Port MAC Address: xx:xx:xx:xx:xx:xx
MGMT-A Port IP Address (if 127): 172.20.1.6
MGMT-B Port MAC Address: xx:xx:xx:xx:xx:xx
MGMT-B Port IP Address (if 128): 192.168.51.50
Hardware Revision: 8
Board Revision: 2
Switch Serial No: xx:xx:xx:xx:xx:xx
Hardware Part No: xx:xx:xx:xx:xx:xx Spare Part No: xx:xx:xx:xx:xx:xx
Manufacturing date: 10/46
Software Version 7.9.11 (FLASH image2), active configuration.
Boot kernel version 7.9.11
Temperature Sensor 1: 21.5 C
Temperature Sensor 2: 27.0 C
Temperature Sensor 3: 26.00 C
Temperature Sensor 4: 43.75 C
Temperature Sensor 5: 35.50 C
Warning at 85C and Failure at 100C
Speed of Fan 1: 7964 RPM (75 PWM)
Speed of Fan 2: 8169 RPM (75 PWM)
Speed of Fan 3: 8023 RPM (75 PWM) <---故障したファン
Speed of Fan 4: 8503 RPM (75 PWM)
Speed of Fan 5: 8256 RPM (75 PWM)
Speed of Fan 6: 8120 RPM (75 PWM)
System Fan Airflow: Front to Rear
State of Power Supply 1: On
State of Power Supply 2: On
自分の不確認により一つSanAceの109P0412J3063が犠牲になりましたが、最終的には無事に直すことが出来ました。直しても今後使う予定はないので微妙ですが、某所のラボネットワークの変更時に持ち込もうかなあ…。
ピンアサインにさえ気をつければ一般品でも交換できるので、保守のないスイッチで、もし同じようにファン故障で困っている人がいたら試す価値はあると思います。
[ コメントを書く ] ( 1739 回表示 ) | このエントリーのURL |
SRCHACKさんがVR500で面白そうな遊びをしていたので、VR500はHW面で興味があったのですが、自分も筐体をゲットできたので遊んでみました。文章が長いのと長い文章に疲れて所々雑になっているのは許してヒヤシンス

もっと読む...
[ コメントを書く ] ( 5948 回表示 ) | このエントリーのURL |
前編でまず2つの惨劇を体験しましたが、トラブルはまだ終わりません。
プライマリストレージサーバの置き換え
前編でプライマリを復旧したあと、しばらくそのままの環境で使っていましたが、その後バックアップサーバのST2000DL003が死にました。半年以内に3台のDM001と1台のDL003が連鎖的に死亡していくのをみて、さすがに怖くなってプライマリストレージサーバのHDDを全て交換することにしました。(ちなみに死亡したHDDに限って購入時のレシートが見つからないという)
グロ画像ことプライマリとバックアップサーバから引き抜いたDL003君とDM001君です

ストレージサーバの置き換えには、遊んでいたX8DTLにXeon L5630とメモリを適当に積み、ディスクには東芝製MD04ACA200を使う事とにしました。
惨事その3 RAIDアレイが突然死
X8DTLにはオンボードで LSI 1068Eから生える8ポートのJBODで見えるSATA/SASポートがあり、このポートを利用してmdraidでraid5のSRPデータストアを作成し、AHCIの方から生えているSATAポートを/などのOS用に割り当てることにしました。
当初はこれで問題なく動いていたのですが、構築から2週間後にZabbixから
kernel: mptbase: ioc0: WARNING - IOC is in FAULT state!!!
という見たくない感じのエラーが飛び、その後mdからディスクが1本もげました。
何故構築してから全く時間が経っていないのにディスクが故障?と思いましたが、とりあえず予備のMD04ACA200と交換することにしました。が、再構築中にmdがUU__U___になり死にました。その死に方も、一旦その状態になるとsmartctrl -x /dev/sdaなど、1068Eに繋がっている他のディスクに対して行うとエラーを返す、fdiskでも見えなくなるという状態でした。
この文章を書き起こしていても思い出したくないくらいのトラウマなのですが、全てのディスクをsmartやWindowsからHDTuneで読み書きテストをしてみても、特に問題は見つかりませんでした。仕方がないので、再度RAIDの初期化を行い、再度バックアップからの戻しを行いました。
しかし、また1ヶ月後に例のエラーが出て、ディスクアレイが死にました。
惨事その4 RAID HBAが突然死
おそらく、この状態になっていると言う事は、オンボードのLSIのチップが死んでいる?という可能性があったので、オンボードの1068Eを利用しないでLSI 2008チップを載せたD2607を追加し、JBODで見る設定にしました。何故このHBAかというと、手元にありかつ速度がそれなりに速くて接続されたディスクをJBODで見せられるというのが魅力だと感じたからでした。
が、こいつも1ヶ月後にmdが全崩壊を起こしました。
惨事その5 解決したと思わせてからのHBAの突然死
この辺でトラブルについてはほんともうお腹いっぱいだったのですが、この不定期に起きる悪夢の根本原因を探すことにしました。
しかし、何から調べたものか…と、困っていると、ディスクのsmartを取ろうとすると、smartを取得してからその情報を返すまで、非常にディスクのIOが遅くなっていることに気がつきました。
これを手がかりに、検証機でテストしてみると、何もないときはddで内容を読んでいても全く問題がないのですが、smartctrlを動かしながらddをすると、あるタイミングでsmartが刺さり、smartの内容を全く返さなくなり^Cでも中断できなくなり、かつIOがゼロになると言う問題が起きました。
何もせずにdd if=/dev/sda (D2607に繋がってるMD04ACA200) of=/dev/nullを行っているときの状態です。Readが193MB/s出ているので普通です。
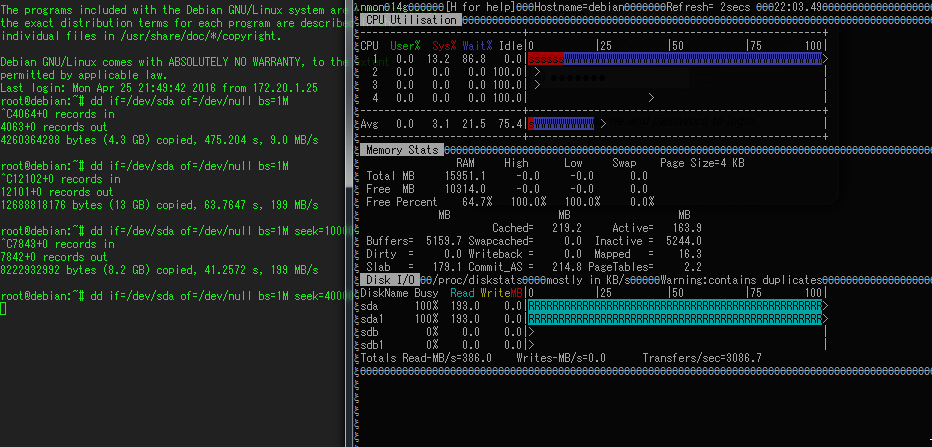
その状態で、新しくSSHのセッションを張り、
while :; do smartctrl -x /dev/sda >/dev/null ;date; sleep 1 ; done
をした結果です。
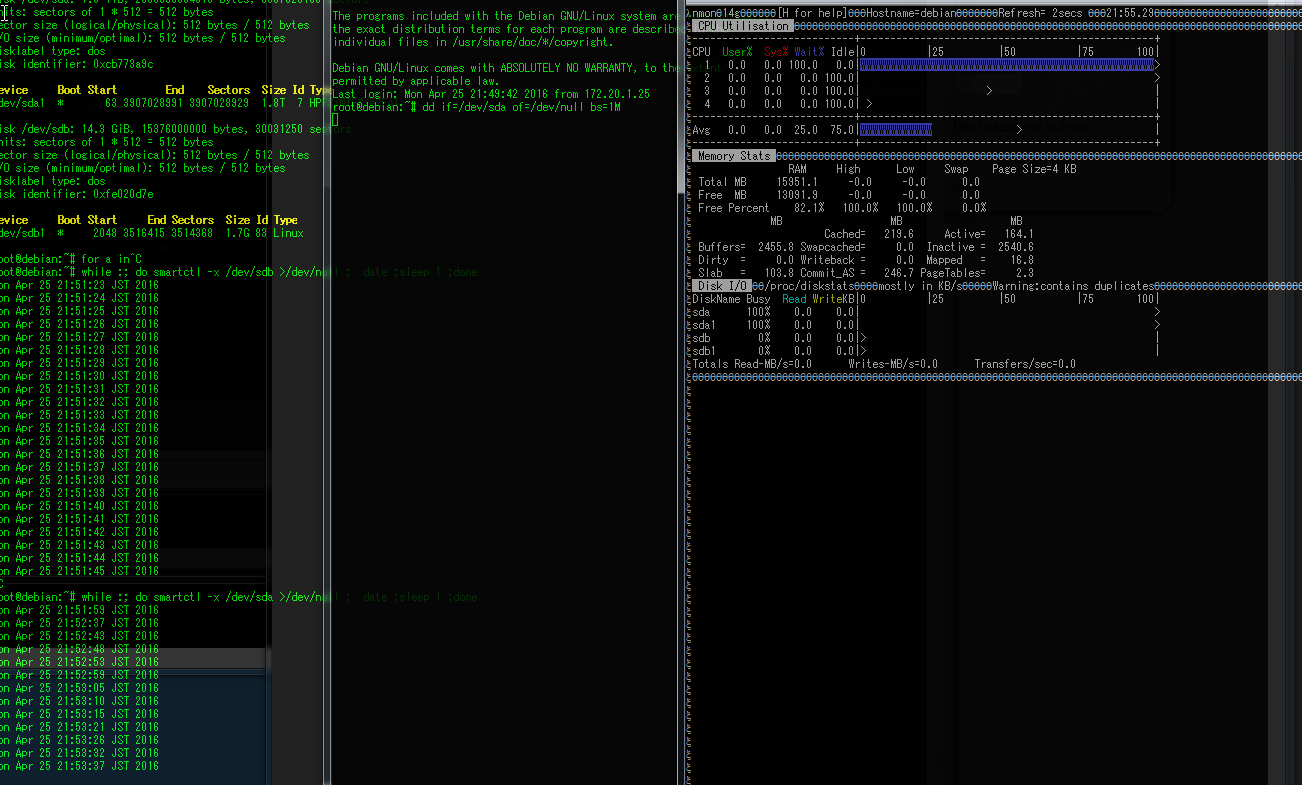
ddは続いているのですが、IOが0になり、かつDisk busyが100になり、CPUを1つI/O WAITで潰しています。
この内容で調べてみると、ぴったりではないのですが、D2607のファームウェア情報に、SMARTの情報異常を感知してコピーバックをする(予備ディスクに内容をコピーして異常時に備える)時にHBAが死ぬという情報があったので、とりあえずファームを新しくしてみました。
その結果、smartctrlをかけながらddをしても、smartを返す時にはIOは遅くなるものの、完全に刺さることはなくなりました。
また、Debianでsmartmontoolsを入れるとデフォルトで定期的にsmartdが各ディスクにSMARTクエリを飛ばすので、systemctl disable smartdを行い、ドライバもLSIから落としたものをビルドし、smart関連で刺さらないことを祈りました。ディスクへの情報取得で何かが起きていることはおそらく間違いないので、さすがにこれで解決したと思いました。いや、思いたかったのですが…
再びHBAが死にました。
再現性の調査
もしかしたらこの悪夢はLSI 2008チップと東芝のディスクの相性が原因で、他のLSI 2008チップを使っているHBAでも同じように起きるのでは?と思いいくつか試してみました。

検証環境で試した結果、以下の結果が分かりました。
・D2607だけではなく、HP OEMの LSI SAS 9212-4i(同じLSI2008チップを使うデフォルトでITモードで動くHBA)でもOSから複数のディスクでRAIDを組むと、バースト的な高負荷書き込みが連続すると不定期に死ぬ
・D2607はJBODを有効にせず、それぞれのディスクで1本のRAID0を作る(過去に8708EM2等で使われていた方法)を使うと検証期間中には問題が起きなかった(SMARTの取得は出来なくなりますが)
・MD04だけではなく、MD03、DT01、日立のHUA723でもSMARTの問題は起きる(これらのディスクは返す内容が大体同じ)
・SeagateのDM001、DL003、WDのCaviarGreen等ではSMARTの問題は起きない(日立系ディスクに比べて非常に簡素な内容しか返さない)
・LSI 2108を載せたボードでは、JBODは出来ないがHBA上でRAIDを組む分には問題なさそう(短期間しか試してないので怪しい)
以上のことから、LSI のチップでEnable JBODを有効にしてJBODでディスクをみていたり、ITモードで動くHBAと日立系のディスクは問題があるのかもしれないという結論に達しました。
ディスク全交換 そしてトラブルは静まる
上述のテストをしてる間に、秋葉原のBUYMOREでMG03ACAがバルクで入荷し、非常に安かったので一つ買ってみたところ問題が起きなさそうだったので、結局ディスクを全てMG03ACA300に交換してしまいました。MG03はSMARTでSAS系の情報を返すNL-SAS製品で、MD/DTシリーズとは動きが違うようでした(噂ではMGシリーズは富士通の流れをくむディスクで、それ以外は日立の流れをくむらしい。富士通のSASディスクでSMARTを見たことないので確証はありませんが、近いとは思います)。もうこのトラブルとおさらばできるのなら多少の出費は厭わない、という感じです。
このディスクに交換したところ、D2607でJBODで見ていても過去のトラブルが嘘のような平凡な日々が訪れました。少なくとも、今のところは…。
まとめ
今回の問題を回避するには、少なくともLinux上では
・LSIのチップに日立系のディスクを混ぜないこと
・LSIのチップで日立系のディスクを使うのなら、HBA自体のRAIDを利用すること(少なくともJBODで見るよりはトラブらない)
・日立系ディスクをJBODで見たいなら、オンボードのAHCI/SCUを使う事(smart取得時の速度低下は起きるが死ぬ事はなかった)
・2012年頃のSeagateのディスクはやばい(DM01が3/8で36%の故障率、DL003が1/6で16%の故障率)
と言うのが今のところの結論です。日立系のディスクと言っても、ニアラインSASや10kRPMのSASドライブではまた違うと思いますが、少なくともデスクトップ向けのディスクとLSIのチップは避けるべきのようです。
また、DM001の故障率は有名なBACKBLAZEでもST3000DM001が導入からちょうど2-3年で20-40%の割合で故障しているので、奇しくもこのデータと近い値が出てしまいました。このヤバいディスクがINしてるシステムでまだ問題が起きていないのであれば、早急に交換をおすすめします。(大半のディスクはもう死んでこの世にいないかもしれませんが)
1台2台がばらばらの時期に壊れてくれるのであれば良いのですが(良くはない)、まさか連続死を起こされるとは…。まあ、それを見越した設計でも最後の砦を壊したのはこの手でしたが。
この一件で、バックアップの重要性を身をもって実感することになり、いくつかのデータは仮想マシンではなく物理マシンにrsyncするようになりました。そしてディスクが安く売ってると買ってバックアップサーバを作らなくてはと言う強迫観念に駆られるという傷跡を残しました。
せめてもの救いは、オペミスしたのが自分の環境だったことで、仕事でやらなくて良かったという点です。個人的には仕事のデータなんかよりこちらの方がよほど大事ですが…。
かなり長い間悩んだ内容だったので記事自体も長くなってしまいましたが、誰かの役に立つことを願い一応まとめてみました。ストレージ関係の悪夢はほんとつらいので誰も見ないに越したことはないのですが。
[ コメントを書く ] ( 1395 回表示 ) | このエントリーのURL |

凄く久々にブログを更新しますが、この間に色々問題が起きたのでその事についてまとめようと思います。
特に、この一年は何故かストレージ周りでトラブルが起きることが多く、とてもつらい感じでした…が、とりあえず収束したようなので書き出してみようと思います。
惨事その1 RAIDアレイ崩壊→VMストレージの死
事の発端はまずここからでした。去年2015年の6月頃に、まず1台ディスクが故障しました。故障したディスクは悪名高きST2000DM001です。(あとになって故障率の高さを知りましたが。7200.12くらいの頃はディスクロックというもの以外そこまで壊れた経験がなかったのでSeagateのディスクは大丈夫だろうと思いましたが、それが甘かったです…)
まあ、当時でも構築して2年くらいが経っていたので、そろそろディスクの1台くらい壊れても不思議ではないかなあと思い、手持ちのST2000DM001と交換し、再構築しました。
その時は特に問題がなかったのですが、更に2ヶ月後の8月に2台目のDM001が死にました。このときに手元にあったのがバックアップストレージに使っていたST2000DL003だったのですが、回転数が違うので新しいのを買わないとなあと1週間くらいRAIDがデグレッた状態で放置していたのですが、この一週間のうちに3台目のST2000DM001が死に、RAIDアレイが全損しました。
うっせやろと思いながらも、ghettoVCBにてバックアップのストレージに重要なマシンのコピーを取っていたので、ダメージは少なく、ここから戻しを行うことにしました。
しかし、ghettoVCBのような方法だと、vmdkの差分コピーとはならず、実行する度に全てのディスクをまるまるコピーすることになるので、TBクラスのディスクを定義しているとなると色々厳しくなります。
そのため、ある程度データが大きくなりそうなものについては、バックアップ対象外のVMとしてNFSサーバを作り、そこに置くようにしていました。そして、これが悲劇の元に…
惨事その2 オペミス
タイトルでネタバレしていますが、まず環境を簡単に説明します。

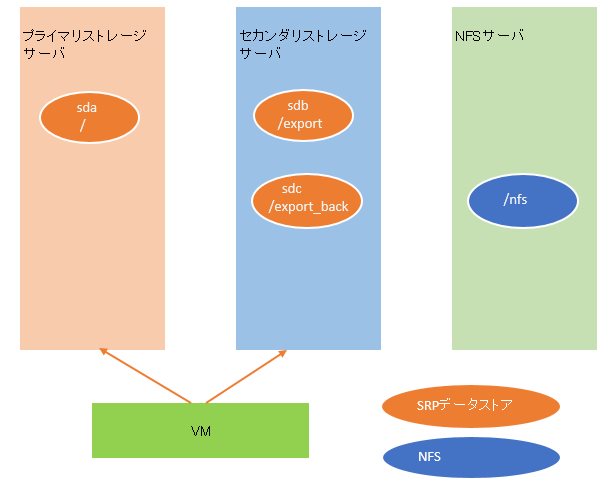
非常に雑な絵ですが、このような方法で/を含むsdaのイメージバックアップと、sdbに含まれるNFSの領域をsdcへコピーしていました。オレンジの円がVMホストからのSRP接続のデータストアで、青い円がVMゲストから別の物理NFSサーバ(10G接続)への接続です。同期方法は/はMondo backupによるイメージバックアップで、/exportは/export_backへrsyncでした。
ちなみに、NFSには内輪で使っていた諸々のMODデータやこのブログのデータが置いてありました。
プライマリのストレージに問題が起きた場合はvmxファイルなどが消えますが、その際には新規でVMを定義し直し、NFSからMondo backupで定期的に作成されるISOをマウントして復旧、その後/exportを/export_backから戻す、と言う想定でした。mondo自体の実績はあったのでまあ手間だけど問題ないだろうと言う判断でした。
直接NFSに/exportのコピー持てば良くないかと思うかもしれませんが、NFSサーバはメインで使っているNASなので、フルに同期するとその当時の容量的にぎりぎり収まるか何かあれば溢れるという状態だったため、容量的に余裕のあるghettoVCBのバックアップ先にもなっているセカンダリストレージサーバにSRPデータストアを作成していました。
環境の説明が終わったところで、本題に移ります。今回はプライマリストレージが死んだので、このような状態になりました。
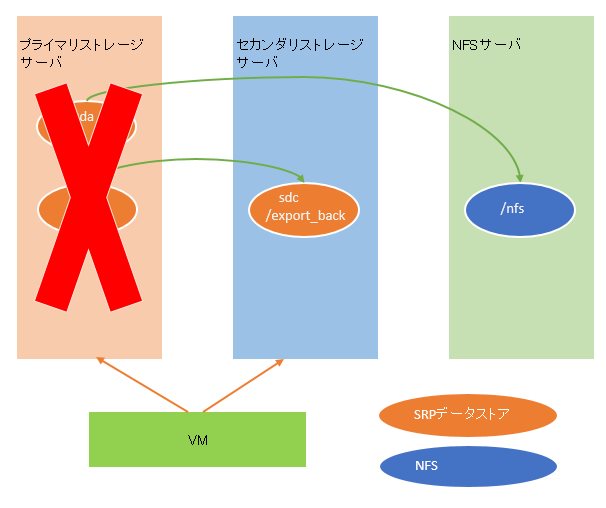
そのため、プライマリストレージのディスクを新しく2本買い再構築したうえで、想定通り/nfsに取っていたISOイメージからまずVMの戻しを行いました。正確に言うと微妙に図とは違いますが、概要としてはこうなります。
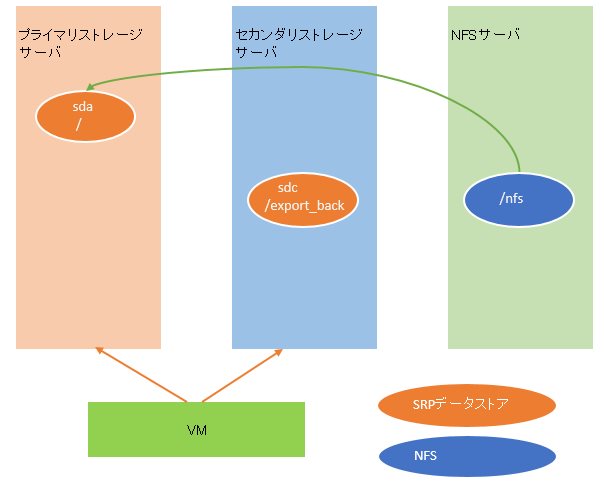
その後、/が復旧したので、/exportの復旧を行うことにしました。が、ここでデータストアを間違えてセカンダリストレージに定義してしまいました。(あっ…)
あ、vmdkの置き先を間違えた、と気がついたので、再度ディスクの定義をしようと一旦間違えた方をけす事にしました。そして実際のオペレーションが下記です。
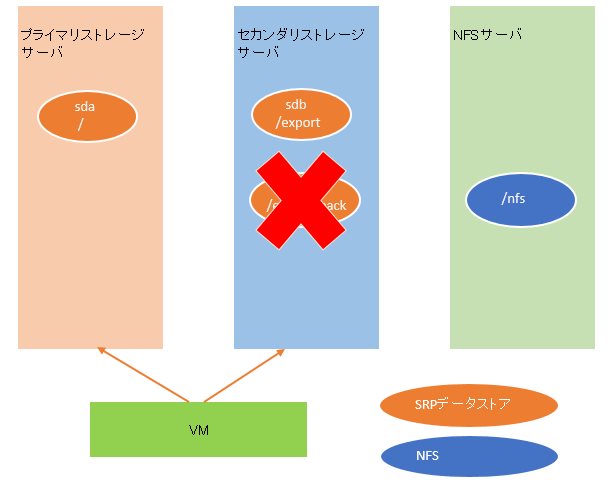
ミスに気がついたときの状態のイメージです。ご確認ください。

ええ、人は犯したミスの大きさ、そのミスが戻せないと分かるとほんとこんな感じになります。しかもたちの悪いことにディスクイメージ自体の削除を選んでしまったんですよね。バックアップがあるから大丈夫、という慢心の結果、そのバックアップを自らの手で消す、という愚行を行ってしまいました。これさえしていなければ何事もなかったというのに…。
SRPのエクスポートを一旦止めて、あれこれとディスクの復旧が出来ないかと試してみましたが、まあ無理でした。
バイナリレベルではいくつかのテキストが見つかりましたが、ある程度の大きさのファイルは断片化があり復旧は困難でした。
どうにか復旧できないかとあれこれ探した結果、物理サーバでブログを動かしていた頃のディスクがあったので、そこから何とか復旧できましたが、諸々のデータが1年分消えました。(前エントリが非常に古いのはそのせい)
その後、色々動いていないと不便なので結局プライマリのストレージは再度稼動させ、VM環境もどうにか以前の状態までは復旧させました。
ここまでで十分惨状ですが、このあともまだトラブルは続きました…(長くなったので後半へ)
[ 1 コメント ] ( 1448 回表示 ) | このエントリーのURL |
<<最初へ <戻る | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 進む> 最後へ>>