
Windowsのリモートデスクトップですが、実はマルチモニター環境で特定の画面だけにまたがって全画面表示する、という機能があります。この機能を使ってとあるVMで作業するときに「1枚の全画面だと微妙に使いにくいけどマルチモニタすべての画面をリモデに使いたくない」という要件を満たすべく2枚の画面だけを使うようにしていました。
https://www.hanselman.com/blog/how-to-remote-desktop-fullscreen-rdp-with-just-some-of-your-multiple-monitors
https://qiita.com/yusuke-sasaki/items/5f70dc266caf13021838
先に結論を書くと、 RDPで複数画面が使えない!というときは、使いたいディスプレイ同士が0pxで隣接しているかを確認する必要があります。以下、検証のメモです。
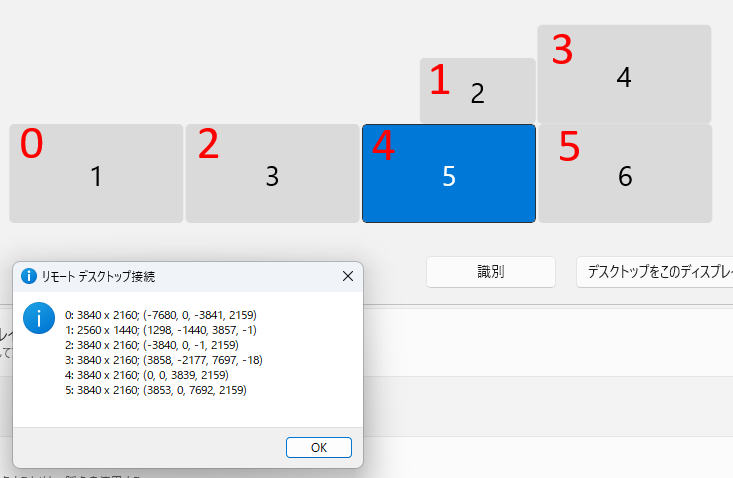
実際のモニターのセットアップはこうなっています。グラボの出力順を考慮していないのでぐちゃぐちゃになっていますが、この中から5,6を使ってRDPを全画面表示する、ということをしていました。

今までこれは動いていたのですが、モニターのつながっているグラボの出力端子を入れ替えたタイミングで画面をまたがっての表示が動かなくなってしまいました。
mstsc /lで調べてみると、端子が入れ替わったことによってモニターのIDが変わっていたので、IDを確認してrdpファイルに書かれている順番を入れ替えれば動くだろう、と思いました。しかし、若干の移動はあったもののIDは大きく変わっておらず、何をやってもモニタをまたがって全画面表示ができずプライマリモニタだけ全画面で表示される挙動を示しました。よくわからないので一度マシンを再起動し、もう一度mstsc /lをすると今度は何故かモニターIDが大きく変わっていた(1,3,10,11,12,13から0,1,2,3,4,5になっていた)のですが、それを直しても動かず、色々検証すると下記設定の赤字0,2の2画面表示と2,4及び5,3の2画面表示は問題なく動き、なぜか2,4,5,や4,5と横一列にしようとしたときに5を含むと動かなくなるということがわかりました。
検証に使った最低限の要素だけ含めたrdpファイルは以下になります。
## NG ##
full address:s:VM1
use multimon:i:1
selectedmonitors:s:4,5
dynamic resolution:i:0
## OK ##
full address:s:VM1
use multimon:i:1
selectedmonitors:s:0,2
dynamic resolution:i:0
プライマリモニタがRX7900XTXにつながっていることもあり、最初はRadeon仕草かと思いましたが、
mstsc /lの値をよく見るとmstsc側ID(画像赤文字)の5の起点座標がおかしい事に気が付きました。この場合、0,0から3839,2159が4の値なので5が3840から始まらないといけないのですが、なぜか3853となっており、赤字4と5の間に13ピクセルの隙間があるいうことがわかりました。カッコ内部の値はそれぞれプライマリモニタ(この場合は赤字の4)の左上を0,0として右下に向けて座標がプラスになり、プライマリモニタより左にモニタがあればxはマイナスに、プライマリモニタより上にモニタあればyがマイナスになります。
Windowsの仕様として隣り合うモニタ同士はどこかでくっついていないといけないのですが、赤字5は赤字3とくっついているという扱いになり、4と5は13ピクセル離れている、という認識になっているようです。出力端子を入れ替えたのがちょうど赤字の5にあたるものだったのですが、Windowsで画面の位置を移動したときにそれがズレたようです。わかるかそんなモノ…。
離れてるのであればマウスの移動もできないのではと思いましたが、ある程度の加速度があると多少の隙間を乗り越えて隣のモニタに行けるようです。逆に、隙間があるととてもゆっくりマウスを動かしてモニタの境界線をまたごうとするとブロックされます。密着しているとマウスカーソルの加速度が1px/sでも境界をまたげるようです。たまに感じた違和感はこれだったのか…。
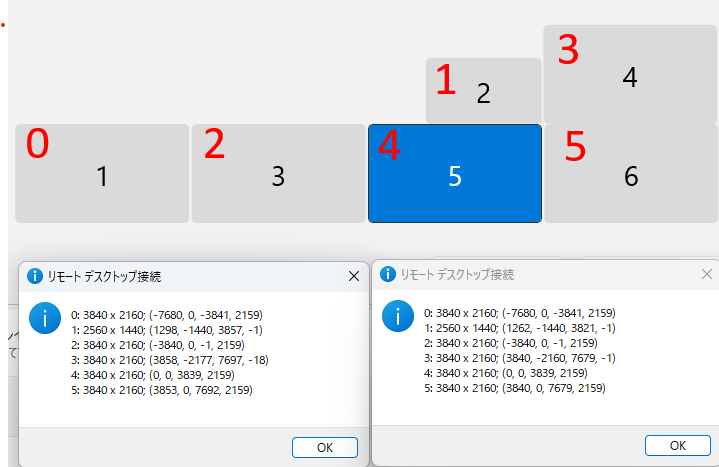
ディスプレイのスナッピングとの格闘の末、最終的に一回り小さい赤字の1以外は0pxで整列できたのですが、どうしても最後の1つが完全密着になりませんでした。1の値は1279,ー1440,3840,ー1になるべきなのですが、Windowsのディスプレイ設定は2辺と隣り合うことを想定していないのか、赤字の3の左辺、もしくは4の上辺のどちらかにしかスナップせず、逆にどちらかにスナップすると絶対にもう一方は合わないという動きをしていました。
ただ、赤字の0,2,4,5の横一列は整列されたので、当初赤字4,5の2画面でリモデが使えないという問題は解決しました。現状、赤字の1,3を使って画面をまたいでリモデをする、ということができませんが、このパターンはないと思うので諦めました…。座標を使ってディスプレイの場所を指定できる方法があればいいんですが…。
変な環境でディスプレイを出力していてRDPで複数画面が使えない!というときは、使いたいディスプレイ同士が0pxで隣接しているかを確認する必要がある、という、ほんとに使い所のないナレッジを得たのでここに供養します。
追記:
その後またディスプレイポートの差し替えがありスナッピングと格闘していましたが、それを便利にするDPEditというツールがあるのを知りました。
DPEdit -A simple Windows command line utility to accurately set the relative position of displays in a dual- or multi-monitor setup -
dpedit /L でつながっているディスプレイ一覧を取得できます。
dpedit /L
Display #5
Device name: \\.\DISPLAY5
Device string: AMD Radeon RX 7900 XTX
Active: 1
Mirroring: 0
Modes pruned: 0
Primary: 0
Removable: 0
VGA compatible: 0
Dimensions: {3840, 2160}
Position: {3840, 0}
Display #6
Device name: \\.\DISPLAY6
Device string: AMD Radeon RX 7900 XTX
Active: 1
Mirroring: 0
Modes pruned: 0
Primary: 4
Removable: 0
VGA compatible: 0
Dimensions: {3840, 2160}
Position: {0, 0}
Display #10
Device name: \\.\DISPLAY10
Device string: NVIDIA Quadro M2000
Active: 1
Mirroring: 0
Modes pruned: 0
Primary: 0
Removable: 0
VGA compatible: 0
Dimensions: {3840, 2160}
Position: {-7680, 0}
Display #11
Device name: \\.\DISPLAY11
Device string: NVIDIA Quadro M2000
Active: 1
Mirroring: 0
Modes pruned: 0
Primary: 0
Removable: 0
VGA compatible: 0
Dimensions: {2560, 1440}
Position: {1280, -1440}
Display #12
Device name: \\.\DISPLAY12
Device string: NVIDIA Quadro M2000
Active: 1
Mirroring: 0
Modes pruned: 0
Primary: 0
Removable: 0
VGA compatible: 0
Dimensions: {3840, 2160}
Position: {-3840, 0}
Display #13
Device name: \\.\DISPLAY13
Device string: NVIDIA Quadro M2000
Active: 1
Mirroring: 0
Modes pruned: 0
Primary: 0
Removable: 0
VGA compatible: 0
Dimensions: {3840, 2160}
Position: {3840, -2160}
dpedit [ディスプレイ番号] [x座標] [y座標] でディスプレイを一つづつ、もしくは複数指定して配置を指定できます。上記の内容を5,6,10,11,12,13の順で一発で指定しようとすると以下のようになりますdpedit 5 3840 0 6 0 0 10 -7680 0 11 1280 -1440 12 -3840 0 13 3840 -2160
複雑な配置を行っている場合にピクセルパーフェクトで配置できずにツラミを感じている人は他にもいるようなので、そのうちPowerToysに入るかもしれません
Fine-tune multi-monitor positioning tool #2652 - microsoft / PowerToys -
いずれにしても、これで不毛なイラつきがなくなったのでまた一つPCの利用が快適になりました。
[ コメントを書く ] ( 717 回表示 ) | このエントリーのURL |
複数GPUを搭載している環境だと、WindowsのバージョンによってセカンダリGPUの扱いが違うというのがあるのでそのメモです。前回の内容に入れようと思った内容だったのですが長くなりすぎたので分けました。
昔は表示しているディスプレイごとに使うGPUが違った
古のXPからWin7、W10の何処かのバージョンまでは、グラボが複数あってそれぞれ画面を出力している場合、その画面を表示しているGPUが実際にその内容を処理していました。 そのため、ゲーム用に使うGUPは画面を1枚だけつなぎ、それ以外の雑多な内容を表示するためのをGPUを別に搭載することによって一種の負荷分散が出来ました。
少なくとも、1080を買った直後は「ゲーム用GPUは画面を1枚だけ出すのが一番パフォーマンスが出る」という動きをしていた記憶があります。
逆に、セカンダリGPUが貧弱だと、ウィンドウモードで起動したゲームをセカンダリ側に持っていくとカクカクになるという動きをしていました。XPや7ではウィンドウモードで起動したゲームが少しでもディスプレイの境界をまたぐとFPSがガタ落ちしたのを覚えています。
すべての処理がプライマリGPU処理に
それがWindows10のどこかのバージョン(20H2くらい?)からすべての内容はプライマリGPUで処理し、その結果を各ボードのRAMにコピーする、という挙動になっていました。その結果、 利点としてはHEVCなどの重いコーデックを使った動画やウィンドウモードで起動したゲームなどを、低性能なセカンダリGPUにつながっているディスプレイ領域にもっていってもそれなりに動く、という挙動になりました。
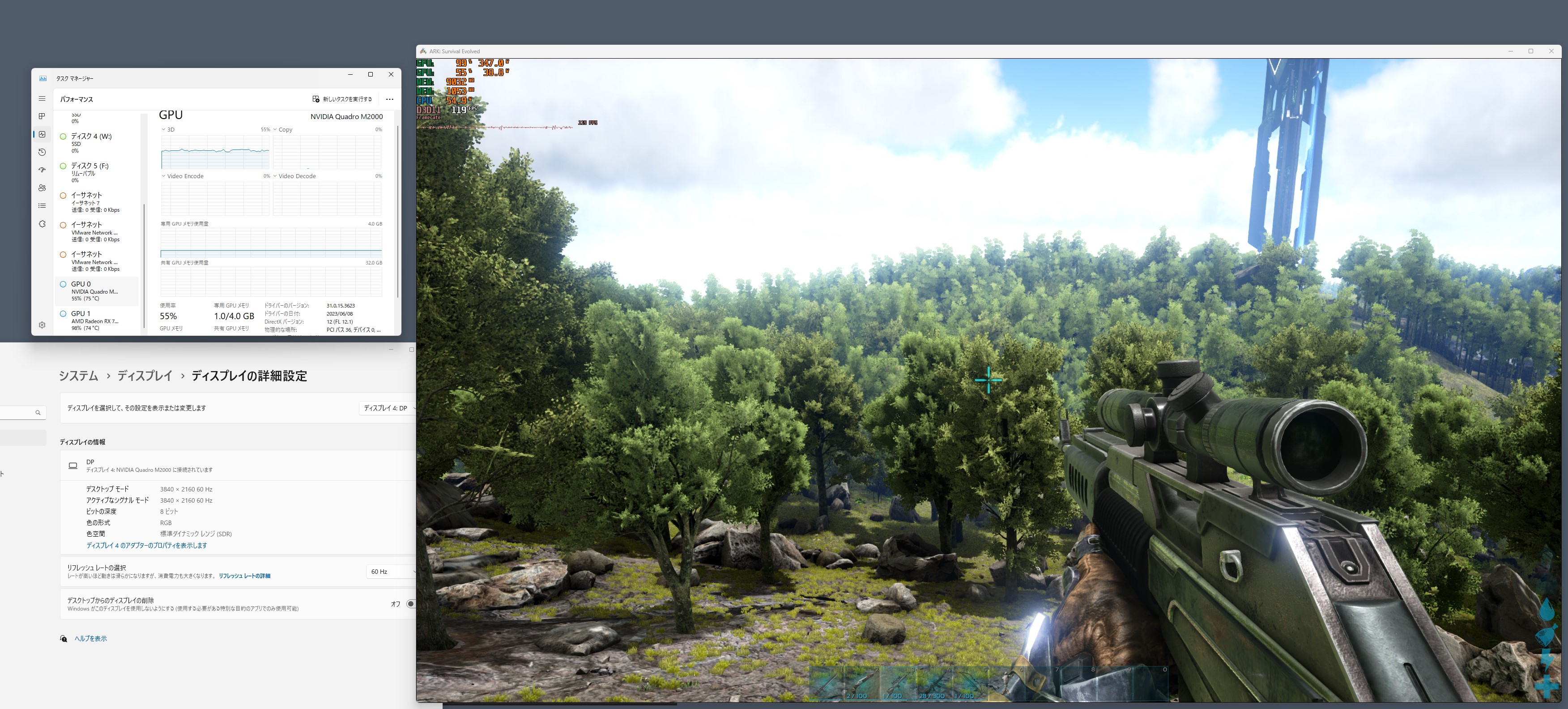
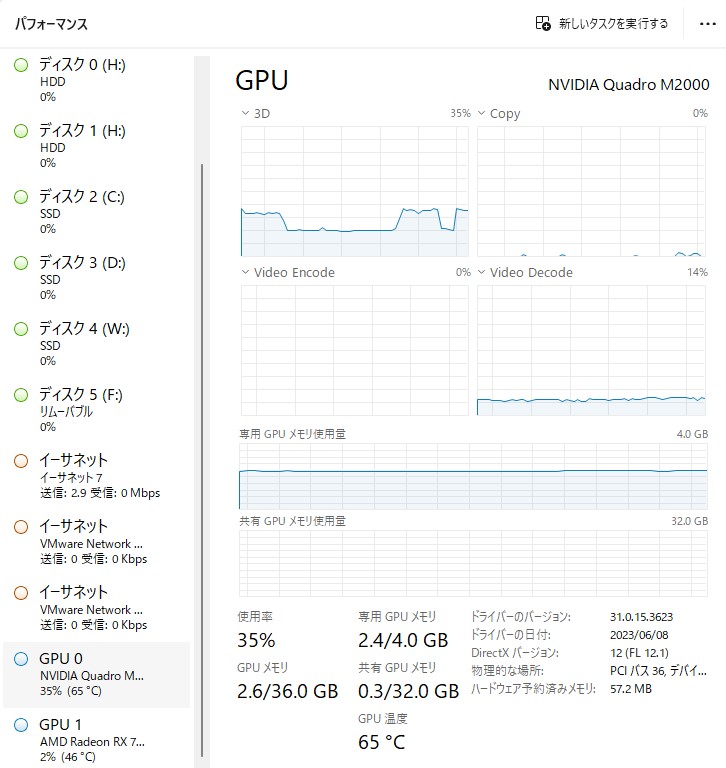
上記はゲーム性能としてとしては貧弱なM2000に繋がったディスプレイにARKという重いゲームをウィンドウモードで起動して持ってきていますが、実態としては7900XTXで処理しているので100FPSを超えて表示できています。
ラグなどもなく、ディスプレイのリフレッシュレート以上のFPSが出ているので、詳しくないとその事に気が付かないくらい違和感がありません。
昔Twitterなどで「GPUが搭載されていてもオンボード側のHDMIなどにディスプレイを繋いでいて意味がない!」というような投稿がありましたが、その状態でもプライマリGPUがディスクリートGPUに指定されているならVRAMコピーを挟むもののGPU性能の8割位は出ていたと推測できます。
非効率ではあるものの上記のARKの例のようにゲームなどは普通に動くので、実際のところ気がついていなかったのではないかと思います。Win7とか10のでたての頃は明らかにパフォーマンスが出なかったと思いますが。
この仕組みの欠点としては、どうやってもプライマリGPUの負荷だけが上がるようになってしまうこと、ある程度以上のセカンダリを積んでいると、GPUのその余ったリソースを有効活用できないことです。
また、マルチモニタ環境でセカンダリGPUに繋がったディスプレイでなにか作業をすると、まずプライマリGPUで描写→セカンダリGPUのVRAMにコピーという無駄なステップが増えてしまうという問題もありました。
無理やりプログラムが使うGPUを指定する
プロセスが利用するGPUは、プロセスが立ち上がるときにWindowsでプライマリになっているディスプレイ(「このディスプレイをメインディスプレイにする」に指定されているディスプレイ)がつながっているGPUとなります。
ずっと起動しているとあまりにもプライマリGPUのVRAMを消費するので、その仕組を利用して、ブラウザなどを起動する前にセカンダリGPUに繋がっている適当なモニタをプライマリにする→ブラウザなどを起動する→もとに戻す、という手順でVRAMを食うブラウザなどが利用するGPUを無理やり変更していたこともありました。
ただ、これをするとFirefoxがWebGLやGoogleMapをレンダリングできなくなるというような問題があったので微妙なところでした。
まあ、こまめに再起動すればいいという話はありますが、基本起動しっぱなしだと、作業中の窓やブラウザのタブを閉じたくないのでVRAMの負荷分散をしたいという動機が強くなります。
Win10から処理するGPUを指定できるようになったが…
Windows10の21H2くらいからプロセスを処理させるGPUを指定できたのですが、試したところ省電力、高パフォーマンスというくくりは、UDHグラフィックスなどのiGPUを省電力GPU、それ以外のディスクリートGPUは高パフォーマンスGPUというくくりでした。
なので、両方ともディスクリートであるM2000と1080という組み合わせの場合、どちらかを省エネグラボに指定する、ということは出来ませんでした。
https://forest.watch.impress.co.jp/docs/news/1270962.html
M2000を省電力、1080を高パフォーマンスと指定できる方法がないかと探したのですが、結局iGPU以外は省電力GPUとして指定することは出来ませんでした。
Win11でいつの間にかプロセスのGPU割当機能が追加された
7900XTXに換装後も4k複数枚でブラウザを起動したままにしていると相変わらずVRAMを10GBとか消費することがある(ブラウザを閉じてもDWMが4GBくらい抱えたままになる)のは解消しませんでした。メモリに余裕があるとはいえ流石にどうにかしたいです。
WindowsUpdateを当てたらマシにならないかとWindowsUpdateを当てることにしたのですが、上記のグラフィックスのInsider previewを試すためにDevチャンネルにしたままなのを忘れていて、久しぶりにUpdateを当てたらWin11のInsider previewが降ってくるという事故を起こしてしまいました。
意図せずWin11(のInsider preview)になってしまったのですが、ロールバックする前に今の環境をWin11にした場合の挙動を確認することにしました。
仕事では13世代のi5を使う関係でW11を使っていますが、W10に比べてすべての動作が緩慢なのでW11をメイン機に入れたくないと思っていたところ、いざ実際に普段のマシンで使ってみると「あれ…なんか逆に調子いい?」という感じだったので、そのまま利用を続行しました。CPUはRyzen 5 5600XなのでP/Eコアというものはなく、OSはどちらを使っても問題ないはずなのですが…。
そして、いろいろな設定を巡っているといつの間にかプログラムを処理するGPUを指定できるようになっていました。
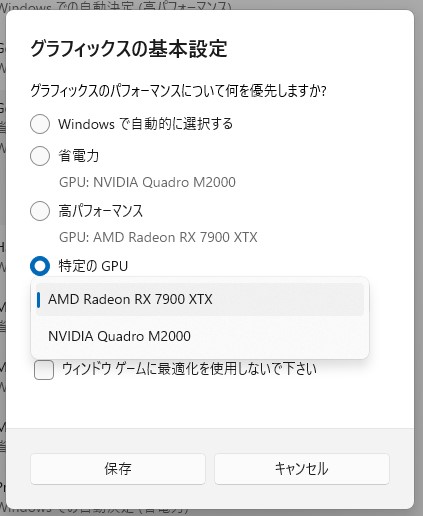
W11も初期のバージョンはこの「特定のGPU」という選択肢がなかったように思いますが、いつの間にか増えていました。確認したバージョンは Insider Preview Build 23612 (Dev Channel)となりますが、ビルド的に多分22H2くらいにも入っている気がします。
その結果、ブラウザでなにか調べたり動画を見たりするときにはセカンダリGPUのVRAMやビデオデコーダがが使われるようになり、いい感じに動くようになりました。
もっと前にこれができるようになっていてほしかったですが、ようやく欲しかった機能が実装されました。
まとめ
プライマリGPUがミドルクラス〜ローエンドのグラボを使っていて、補助GPUを使って少しでもプライマリ側の負荷を下げたい、というときにはこのオプションは有効だと思います。
現行のミドルクラスならベース性能がかなり上がっているのでその必要もない気はしますが、VRAMが8GBクラスのものだとゲーム用にメモリを空けるためにブラウザ処理用の補助GPUが欲しくなる気もします。
ちなみに4kだとゲームを起動すると8GB位のメモリはあっという間に使うので、4kでゲームをしたいなら12GB、できれば16GB以上は必要だと感じました。
動画のHWエンコードソフトから使うGPUを選べないような場合も、強制的に使うGPUを指定することによって負荷分散ができるようになります。1080とM2000を組み合わせたときにはOBSやD3DGearのHEVC録画はGPUを分けたほうがゲームのFPSは安定していました。
また、プライマリGPUの性能が高いのであれば、CPUがiGPUを持っている場合マザボ側のポートもそれなりに使えるようになること、 NVS810 のような1スロットで8枚DPをはやせるGPUを使うときに、GPUの性能としては低くてもプライマリGPUの性能を借りることによってある程度快適に使えるので、ある種のディスプレイハブとして使うといった柔軟性がかなり高くなったと思います。
こういったカーネル周りに手が入って良くなっている感じはするので、事故で上げてしまったW11はW10に戻さずに使うことにします。
以上
[ 1 コメント ] ( 795 回表示 ) | このエントリーのURL |

普段使っているモニタを4k*4枚に変更したのですが、ふとゲームをしようと思ったら今まで使っていたGTX1080では処理能力が足りなくなったためグラボを変えようと思っていたところに、じゃんぱらでRadeon RX7900XTXがなぜか特価で出ていたため久々のRadeonにしました。その時に色々検証したのでその時のメモです。
ことの発端
仕事でモニタを使うときに、置く場所の関係であまり多くのモニタを置くことができなかったので、モニタの中に極限まで情報をぶち込みたいという欲求から27インチの4Kモニタをスケーリング無しで使っていました。目を潰しながら4kを使っているうちに慣れてきたので、家で使っているモニタも4kにしようとすべて置き換えました。
1枚だけ変えると色味が合わないとかベゼル位置が合わないというような微妙なストレスが嫌なので 4kを複数枚買いましたが、使ってて思うのは個人的には27インチWQHDくらいの解像度がベストだと思います。
27インチ4kモニタは11インチのFHDモバイルモニタを4枚並べたときとDPI的に同じになるのでスケーリングなしにするとまあまあ厳しいですが、現代のITエンジニアは眼球に可能な限り多くの情報を詰め込む必要があります。
モニタを変えてからしばらくは忙しくゲームをする暇と気力がなくてオフィス用途でしか使っていませんでしたが、ふとARK: Survival Evolvedを起動してみたところ、すべてEpicの状態で4kネイティブで起動すると20FPSくらいしか出ないという状態でした。
ゲームしたいときに出来ないというのは問題なのと、4k複数枚の環境だと普通に使っていてもDWMプロセスやFirefoxなどのブラウザがVRAMを消費していって8Gのうちの5GBを消費しているようなことがあったので、いい加減グラボを変えたいという思いが強かったので新しいものを買うことにしました。
グラボ選定
最初は4080を買おうと思っていたのですが、じゃんぱらで7900XTXが特売されていたのでVRAMが24GBと多いという利点からこれも候補に上がりました。色々比較すると、
・純粋な3D処理能力は4080よりも高い場面も結構ある
・すべてのタイトルでDLSSなどの機械学習が使える訳では無い
・7900XTXの特価は12万だったが4080はどうしても18万くらいになる
・RTX5000シリーズが先送りになったのでRTX4000シリーズの価格が下る要素がなくなってしまった
・VRAMが多いので雑に使っても心の余裕がある
となり、過去散々ATiのグラボで色々踏んだ事があってもまあいいかなと思えたのでポチりました。
VRAMがそんなに必要になるか、と思うかもしれないですが、3ヶ月位(下手すると1年)再起動せずにブラウザのタブやウィンドウを大量に開いたまま使っているとVRAMの使用量が肥大化していき、VRAMが足りなくなるとブラウザやOSの挙動がおかしくなり、すべてのブラウザを閉じるという必要が出てきます。
ブラウザをすべて閉じても今度はWindowsのDWMがVRAMを握ったままになり、その状態でゲームをするとスワップのような挙動になる事があり、解消には結局再起動が必要になってストレスだったりします。
使い方が悪いのでは??というのはそうなんですが、原状どうにもならないのでこの使い方だとスペックによるパワーで押し切るしかないです。また、4kという解像度が1枚でFHDディスプレイ4枚分の表示面積があるので、それを複数枚となると相応のスペックが必要になります。
27インチで4kの解像度でゲームをする必要があるのかと言われると、別に画質を求めているわけではないのですが、フルスクリーンの解像度変更によって開いているウィンドウがめちゃくちゃになるのが嫌なので、どうしてもネイティブの解像度で出したくなります。
ただ、こういった変な要求がなければ現在では性能や値段、発熱や消費電力の扱いやすさから4070あたりが妥当だと思います。また、自分は今のところ常用デスクトップ機で機械学習をさせるつもりはないのでRadeonも候補になりましたが、普段機ででお絵かきAIも動かしたいというような要望があると必然的にGeforceが候補になるかと思います。
わかっていたけど高い消費電力
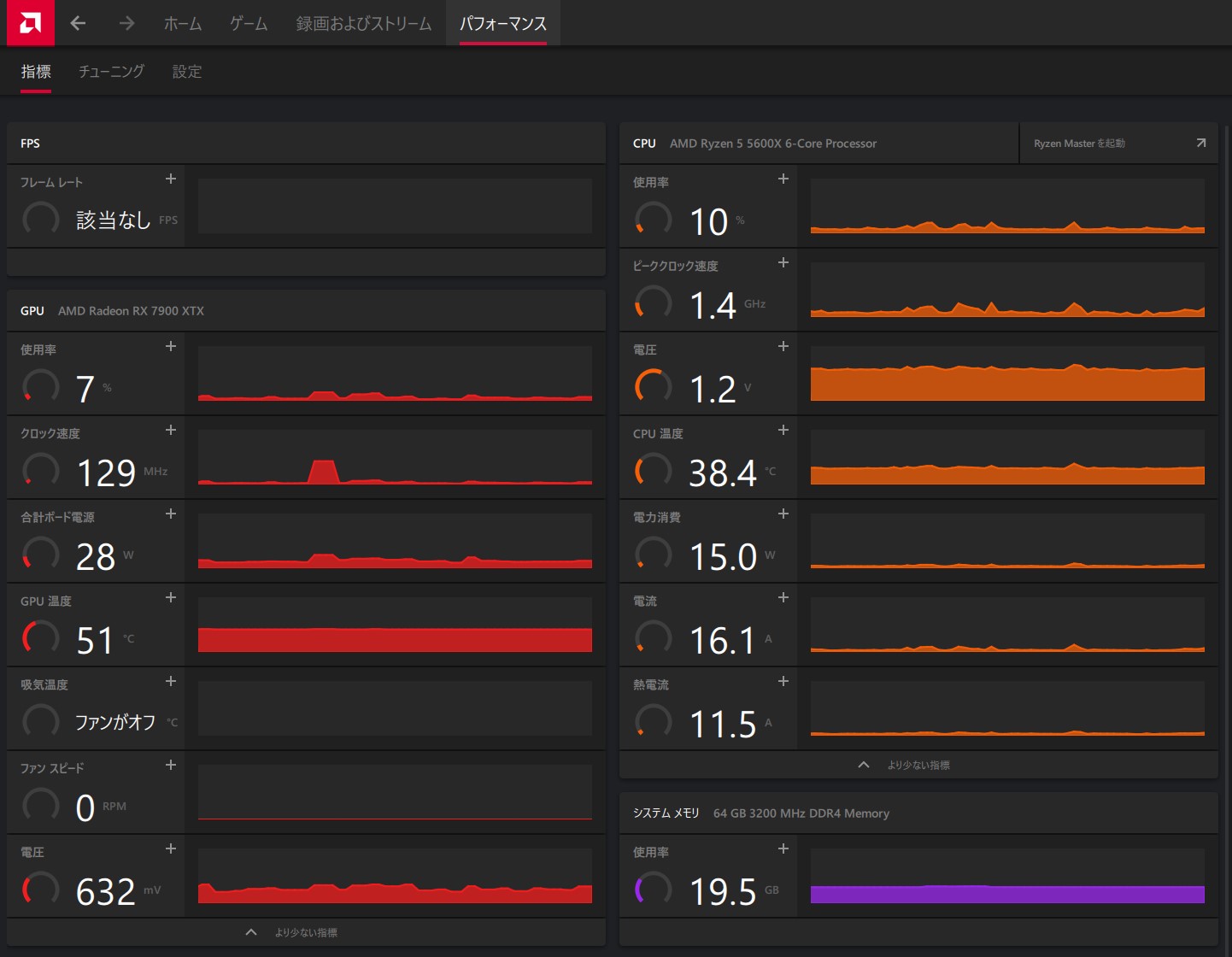
グラボを換装した感想ですが、4kでもARKなど今までやってきたゲームがコマ落ちせずかなり快適に動くので1080との性能差を実感しました。ただ、それに比例して消費電力が増えたので、 AMD Software: Adrenalin EditionというAMD謹製のGPUのモニタリング、チューニングをするツールから消費電力を監視し、これを下げる方向にチューニングする方法を模索することにしました。
フレームレート制限で消費電力を下げる
ARKを遊んでいるとGPUだけで350Wくらい行ってしまうので、どうにかこれを下げられないかとアレコレしていると、当然ながら負荷が下がればそれに伴って消費電力も下がることがわかりました。60Hzのディスプレイなので、それ以上のフレームレートは無駄になってしまうため、まずはフレームレートの固定を行いました。
HL2やL4D2などでゲームからV-Syncを有効にすると明らかな入力ラグが出るので今まではティアリング上等で200FPSなどのフレームレートを出していましたが、FreeSync対応モニタなのが有効なのかドライバが賢くなったのかわかりませんが、Adrenalineからフレームレートの制限をかけると気になるラグは出ませんでした。
80-90FPS出ていて350W消費していたのが60固定にすることによって300Wくらいに落ちたので、もう少し下げられないか試してみました
RSRなどのアップスケーリングを試す
Adrenalineの設定にRadeon Super Resolution(RSR)という項目があったのでこれについて調べてみると、ゲームの解像度をネイティブ以下に設定したフルスクリーンゲームを起動した際にドライバ側でネイティブまでアップスケーリングして出力する、という機能だとわかり、試しにゲームから解像度をWQHDにしてRSRを有効にしてみるとかなり効くことがわかりました。
具体的にはRSRを使うことによりフレームレート制限と合わさりGPU負荷が80%まで下がり、消費電力が一気に180W程度にまで落ちました。ただ、ゲーム自体はネイティ解像度以下で出力されるため、開いているウィンドウがぶっ飛ぶ問題は起きてしまいました。
よく見てみるとAdrenalineの説明にFSRをドライバレベルで実行するのがRSRである、という文言があったのでこのFSRについても調べてみましたが、FSRとは FidelityFX Super Resolutionの略であり、こちらは出力するテクスチャの解像度を内部的に落としたあと、グラボでアンチエイリアシングなどの処理をしたあとにアップスケーリングをかけるという技術になるようです。
ただ、FSRについてはゲーム側の対応が必要になるようなので、そもそもARKなどは対応していないのでは?と思いましたが、ゲームのオプションにあるResolution scaleというのがアップスケーリング前に描写するテクスチャの画像になるようです。しらなかった…
FSRについては思いっきり解像度を下げると流石にテクスチャの不鮮明さが目についてしますが、27インチ4kであれば7-8割位のスケーリングならネイティブと遜色ないレベルになりました。
60FPSの制限の中では画質と消費電力のトレードオフになりますが、違和感のないところでWQHDのRSRと同じ180Wかそれよりも若干高い200W程度で落ち着きました。もとの350Wに比べたらだいぶマシになりました。
ついでにDLSSなどについても調べてみる
AMDのグラボなのでNVIDIAの技術であるDLSSは使えないのですが、こちらについても調べてみたところ、やっていることとしてはFSRと同じ低解像度テクスチャのアップスケーリングだとわかりました。
違いとしては、FSRはスケーリング処理をシェーダーとして扱うため特殊なコアが必要ないという特徴がありますが、DLSSはその処理をTensorコアなどの専用プロセッサで行うので対応したグラボが必要になる、ということみたいです。
事実、FSRは1080でも利用できたようなので、実はこれで誤魔化せばグラボを買わなくても耐えられたのでは…という思いはありますが、FSRを行うにもグラボ側の余裕がないと効果がないようなので多分意味はあったと信じます。まあ、VRAMが足りない問題は出ていたので…
DLSSの進化系であるDLSS-FG(Frame Generation)は、実際のレンダリングフレームの間にTensorで(描写済みのテクスチャからいわば画像として)作成したフレームを挟むことによりフレームレートを上げる処理になるようです。同じような技術がFSR3でも実装されるようです。
ただ、補完フレームを挟む必要があるので入力から出力までのバッファが必要になり、入力のレイテンシ低減にはならず、むしろ増える方向になるようです。FSR/DLSSは実際の描写が軽くなるためこれを有効にすることによって入力レイテンシが下がるらしいです。
フレームレートと入力遅延が一致しないというのはなかなか難しいですが、GPUの性能が足りずそもそもコマ落ちするレベルでレイテンシが上がっているようなときにはDLSS-FGのレイテンシのほうがマシになる可能性はあります。
まとめ
昔は「ドライバのフィルタ処理で正しくテクスチャを描写してない!手抜きだ!チートだ!」 みたいなことを言っていた時期がありましたが、今となっては「クソ真面目に描写するのは馬鹿らしいからAI使って補完しようぜ!」みたいなことを言い始めるあたり時代を感じます。まあ前者についてはただの言いがかりですが。
フレームレートを増やす技術というのは言い換えれば同じフレームレートなら負荷が下がる技術ということになるので、極端な高フレームレートディスプレイを使っていないのであれば消費電力を下げる恩恵があるというのを実感しました。
それなら下位のモデルでもいいのではないかと思うかもしれませんが、これらの技術が (RSRは原理的に使えそうではありますが) すべての場面で使えるわけではないというのと、ベーストルクがあるからこそできる余裕というのもあるので、グラボを買うなら個人的にはある程度の上位モデルをおすすめしたいです。
ただ、11月ごろに7900XTXを買ったのですが、2月に4080Superが15万くらいで出るらしいというのを見て「それならそっちにしたわ…」みたいな気持ちはあります…。まあ、こんなことでもないとRadeonを買うこともなかったと思いますし、使ってみたら改めて知ることも多く、AI以外の用途なら悪くないというのがわかったので良しとします。
7900XTXも出始めの頃のドライバの出来は相変わらず散々だったようなので、他人におすすめするときは「Geforce買っておけ」と言いますが…。
FSPカウンタなどで高いフレームレートを見ると気持ちがいいですが、逆に消費電力を減らす方に振ってみるのも面白いと思いました。
以上
余談:過去のATiで踏んだもの
3870を2枚でCrossFireしていたときが一番ひどかったです。CFを使うとどのドライバでも何かしらおかしかったので、その出来の悪いドライバから一番マシなのはどれかを探すのが大変でした。ジャンク漁りかな?
どれも出来が悪いので、毎月出るCatalystドライバに今抱えている問題が直らないかという僅かな願いをかけて更新するのですが、ひどいものだと入れたら最後、青くなって戻ってこれなくなるということが多々ありました。月刊Catalyst!今月号の付属はきれいな青画面つき!!!みたいな感じでした。
まあ、そのあとGTX295を使いましたが 結局nVidiaでもデュアルチップはうまく動かない事が多く、その後使ったHD4890は安定していました。
余談:買ったモニタ
モニタについてはそこまでこだわりがないのですが、1枚だけ変えると色味が合わないとかベゼル位置が合わないというような微妙なストレスが嫌なので、使っていた4枚をすべて交換する前提で安いものを探していました。するとAliで162ドルのものが見つかりました。 (今は絶版になってますが)
モバイルモニタなどの中国製モニタをいくつか試した経験から、今の中国製のモニタのパネルはそれなりに品質が高いという経験則と、ベゼルに変な文字が入っていないのと、何故かこれだけ大きいにも関わらず送料が無料だったので 、試しに1枚買って1ヶ月検証したのですが、そこそこ良かったので計4枚買いました
まあ買った時期によって(もともとできるとは書いていなかった)入力のPiPができるリビジョンとできないリビジョンが混ざっていたとか、 旧リビジョンのモニタについてきたACが公称消費電力が45Wに対して12V/3.33A=40Wという微妙に出力の足りないACで「大丈夫かこれ」とか思っていたら案の定1ヶ月でACが壊れたとか、解像度をWQHDにすると144Hz駆動にする裏オプションが存在するとか、大陸しぐさ満載でしたが、鍛えられてくるとむしろそれが楽しくなってきます。 色んな意味でシビレますね。
ちなみにACについては汎用的な2.2/5.5mm径のACなので在庫が家にくさるほどあり、12V/5Aのものに交換して無事に動きました。それを口実に紛争を開始して部分的な返金を受けられたので良しとします。向こうも知ってか後期リビジョンではACが最初から12V/5Aのものになっていました。色については初期は黄色みが強いですがOSDで調整すればいい感じの発色になりました。
[ コメントを書く ] ( 1094 回表示 ) | このエントリーのURL |
個人でESXiを動かしていると、何かとLSIのRAID情報を取得したいと思うことがありますが、LSAではなくて既存のZabbixからデータを取得したいと思うことがあります。ありますよね(同調圧力)。
何かいい方法がないかと見ていたらstorcliがjsonでデータを出力できることに気がついたので、ZabbixのLLDと組み合わせていい感じにデータを監視する方法を作りました。先にテンプレートのJSONを置いておきます。
Template_LSI-storcli.json
storcliが動けばLinuxであっても情報を取得できるので、agentのsystem.run形式で作ったものも同梱しておきます。storcliの実行にroot権限が必要になるので、storcliにスティッキービットをつけたりsudoを許可したりagent自体をrootでうごかしたりしていい感じに対応してください。
system.runは悪だ!!!!!という方は、最終的にjsonが取れればいいので、userparameterにしたりrootのcronでstorcliを実行して結果をテキストデータとして出力してログ監視するなど、linuxであればやりようはいくつもあるのでいい感じに工夫してください。
まあ、linuxでエージェントが入っているようであれば/var/log/kernelなどをmegaraid_sasといったようなキーワードで監視していれば大体のイベントが取得できますが…。
ESXi用のテンプレートはSSHで接続してstorcliの実行結果を取得するので、Zabbix-agentが入っていないLinuxを監視したい場合にも使えます。
前提条件
利用するにあたり、以下の前提条件が必要になります。
Zabbixのバージョンが6系であること
監視対象上でstorcliが動かせること
作成したLDに対して名前がついていること
ssh接続が有効になっていること
ESXiホストの/etc/ssh/sshd_configのPasswordAuthentication が yesになっていること
注意点としては、LLDとJSONのクエリの関係で、作成した論理ディスクに対して名前が必要になります。デフォルトではついていないので、storcliで監視対象全てで被らない一意な名前をつけてあげてください
/opt/lsi/storcli/storcli /call/vall show all #一覧を確認
/opt/lsi/storcli/storcli /c0/v0 set name=myhost01-boot #/c0/v0に対して名前を付ける
ESXi側のSSHに関しては共通鍵認証でもいいですが、テンプレートの変更が必要なのでそのへんの設定は今回は省きます。デフォルトのkeyboard-interactiveになっていても動きそうな気がしますがテストしてません。
また、テンプレートの形式がZabbix6形式になっているので4系では入らない気がします。LLDのためにJSONpathとカスタムスクリプトでJSを使っているので、これを元に一から作る場合であっても、Zabbix側のカスタムスクリプトでJSの拡張がされていないと動かない気がします。
いずれにしても、4系の環境がもうないのでテストしてないですが、JSONpathは4系でも使えたはずなのでなにかのヒントにはなるかと思います。
利用方法
まず、Zabbixに監視するためのホストを作ります。ESXiの場合はSSHで接続するので、インターフェースは参照しないので127.0.0.1のままでOKです。ホスト名だけ入れてください。
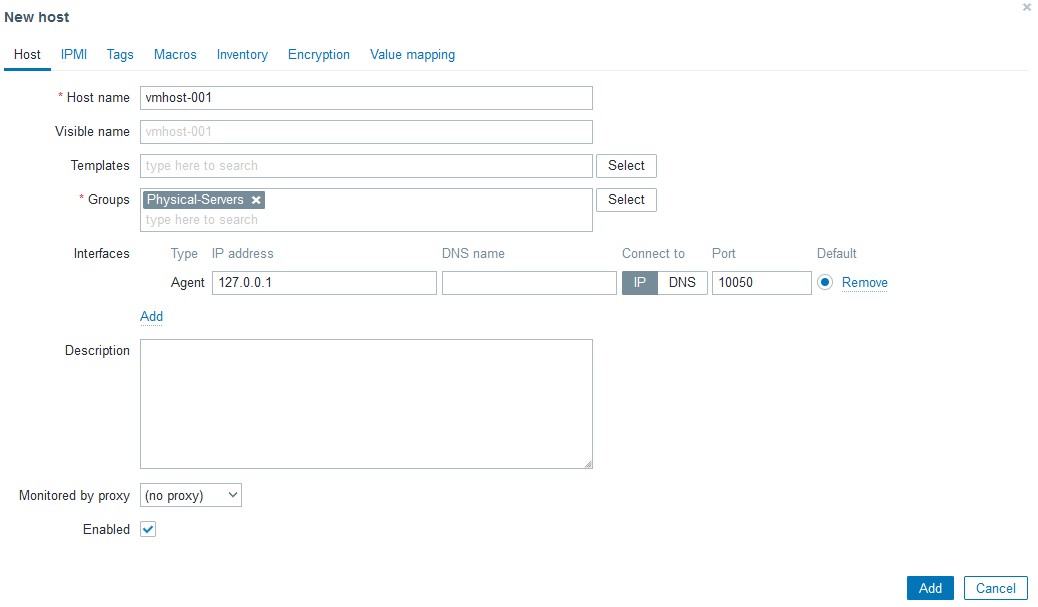
次に、マクロに色々仕組みます。利用しているマクロは以下になります
{$IP} 接続先IP
{$PASS} SSHの接続パスワード
{$STORCLI} Storcliの配置先 ESXiデフォルトは/opt/lsi/storcli/storcliのはず
{$USER} SSHの接続ユーザ
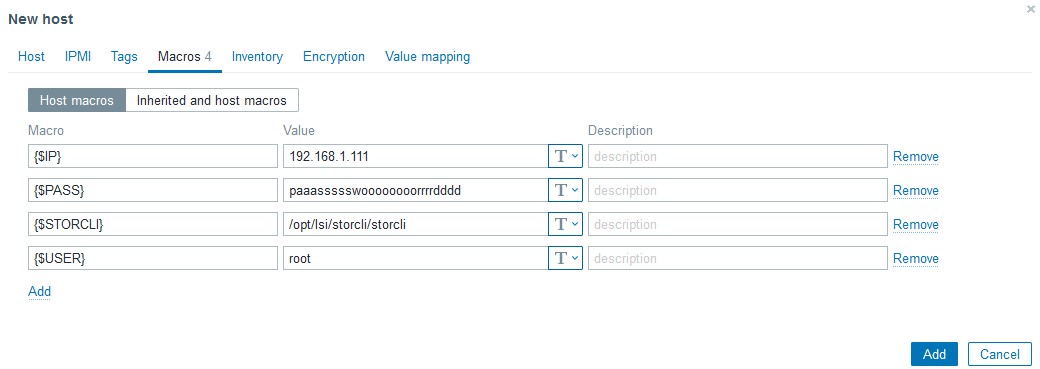
今思うと{$IP}はホスト作るときにIPで作って{#HOST.IP}でも良かったのでは??という気がしますが、作ってしまったのでそのままにします。また、PASSについてはデバッグが終わったあとであればSecret textに変更可能ですが、最初はクリアテキストでデータが取れるかを見たほうがいいです。
作成したホストに今回のテンプレートをリンクさせ、
LD Data from StorcliをExecute nowで実行します。正しく設定されていれば、LLDが発動してアイテムが増えるはずです。LDが増えない場合、上記の制限事項にある手順のstorcli /cx/vx set name=uniquename で名前をつけたか確認してください。Latest dataでデータが取得できているのにLDが増えない場合おそらくこれが原因です。同じく
PD Data from Storcliを実行すると、刺さっている物理ディスクの一覧が取得できると思います。Latest dataが取れない場合、ZabbixからESXiにSSHが届くか、storcliのパスが合っているかなどを確認してください。
制限事項
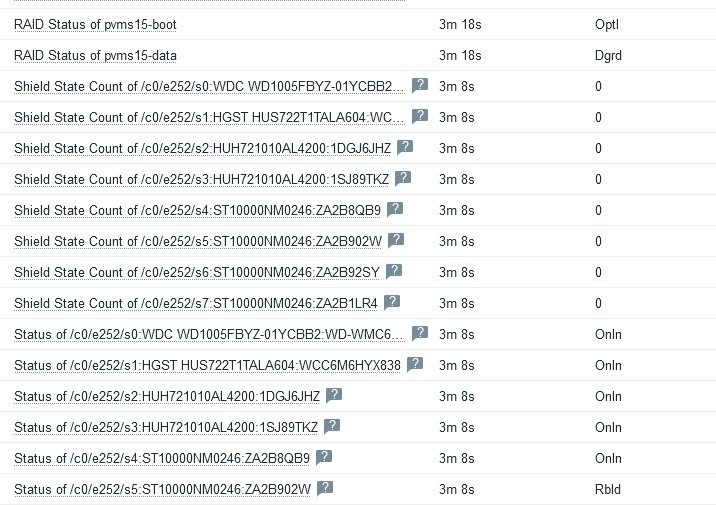
物理ディスクの監視ですが、ディスク、HBAのファームウェアのバージョンによっては取得できない項目があります。
BBM Error countやShield State Countなどはある程度のクラスのディスクでないと値を持っていないので、ディスクによっては取得できないかもしれません。その場合は取得不可のマークが付きますが、影響がないのでそのままにするかLLDで作成されたアイテムから監視の無効化をしてください。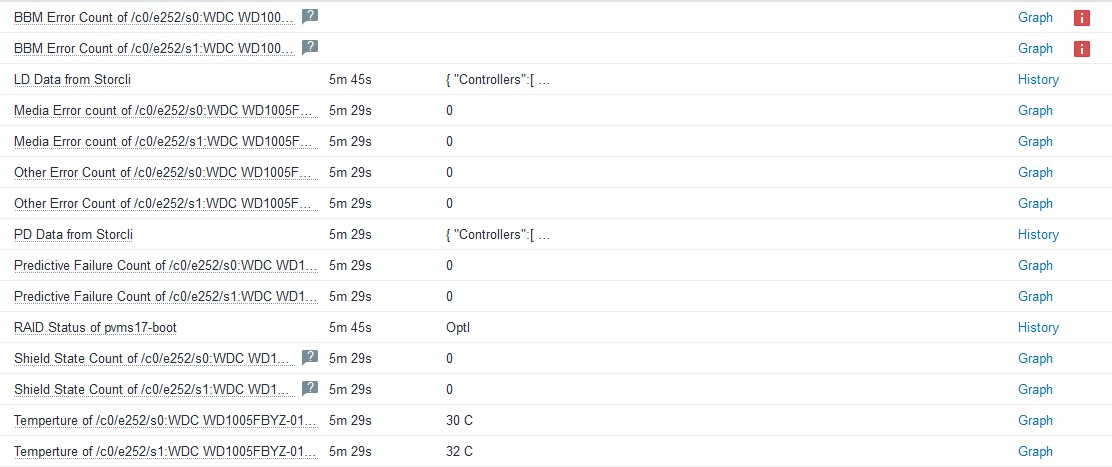
また、物理ディスクの監視のために実行している
storcli /call/eall/sall show all jで応答するJSONがかなり大きいため、搭載ディスク本数が24本などの巨大なマシンの場合はうまく取れないかもしれません。Zabbix6系ではTEXT型アイテムの場合、history_textテーブルに格納され、使っているDBがMariaDBであればmediumtext型で格納されるため1回のデータ取得で16MBまでは入りますが、使っているDBの種類によっては入り切らない可能性があります。参考までに、ディスクを8本搭載したマシンで
storcli /call/eall/sall show all jを実行すると22KBのJSONが出来上がります。調べた限り、Zabbixは1つのセッションで1GBくらいのデータを流せるようなので、おそらくSSHからのデータ取得で問題になることは少ないかと思いますが、場合によってはタイムアウトの時間を伸ばす必要があるかもしれません。
storcli /call/eall/sall show all jの結果については依存アイテムを分解するために実行しているだけなので、Zabbixが6系であればヒストリを「Do not keep history」にしてもLLD分解後のデータ取得は可能です。もともとデバッグのために1時間しか保持していませんが、コマンド実行に問題がなさそうであればstorcliの履歴については取得しない設定でも問題ないです。
→テンプレートの微調整の際にデフォルトではstorcliの実行結果を保存しないようにしました。storcliのコマンド実行結果を眺めたい場合は
PD Data from Storcli のアイテムヒストリをnoneから適宜変更してください技術的内容(うらみつらみ)
今回、JSONとLLDを使うにあたってかなり多くの問題にあたりました。まず1つめはstorcliの返すJSONの作りが悪すぎること、そして2つめはZabbix側のJSONの処理がイケてないことです。両方じゃねーか!!!
ZabbixのJSONの扱いが微妙
ZabbixでJSONを扱うときに2つの問題がおきます。まず1つ目は、LLDでJSONを扱う場合、見つかったキーが
["LLDNAME"]とダブルクオートとブラケットに囲まれた状態で取得します。中身だけ見つけてくれ…と、せめてどうにか値に対してtrimやiregsubなどが使えないか試したのですが、どうやらここをどうにかする方法はないようです。そのため、アイテム名を整形するために
Temperture of {{#MR_PD_NAME}.iregsub("\[\"(.*)\"\]", \1)}というような正規表現をところどころで書く必要がありイケてないです。LLDで見つかったアイテムのキーについても
mrstat.pd.temp.["[\"/c0/e252/s0:WDC WD1005FBYZ-01YCBB1:WD-WMC6M0F4M8WN\"]"]というような状態で入ってしまうのですが、どうせこれは他では使わないしもういいや…と諦めました。2つ目は、LLDを実行するときにJSONから複数の値が見つかった場合、それぞれ
[{"key": "value"},{"key": "value"}]で返答する必要があり、["value","value"]だとイテレータが動いてくれないという点です。https://www.zabbix.com/forum/zabbix-help/419391-utilizing-jsonpath-to-setup-an-lld-macros
これもハマりましたが、上記のスレッドのカスタムスクリプトに助けられました。なおしておいてくれ~~~~~
storcliのJSON構造がカス
storcliのJSONの構造で苦労したのは物理ディスクの応答内容がカスなことです。一例としては以下のようになります
{
"Controllers": [
{
"Response Data": {
"Drive /c0/e252/s0": [
{
"DG": 0,
"DID": 14,
"EID:Slt": "252:0",
"Intf": "SATA",
"Med": "HDD",
"Model": "WDC WD1005FBYZ-01YCBB2",
"PI": "N",
"SED": "N",
"SeSz": "512B",
"Size": "931.000 GB",
"Sp": "U",
"State": "Onln",
"Type": "-"
}
],
"Drive /c0/e252/s0 - Detailed Information": {
"Drive /c0/e252/s0 Device attributes": {
"Coerced size": "931.000 GB [0x74600000 Sectors]",
"Connector Name": "Port 0 - 7 x1",
"Device Speed": "6.0Gb/s",
"Firmware Revision": "RR07 ",
"Link Speed": "6.0Gb/s",
"Logical Sector Size": "512B",
"Manufacturer Id": "ATA ",
"Model Number": "WDC WD1005FBYZ-01YCBB2",
"NAND Vendor": "NA",
"NCQ setting": "Enabled",
"Non Coerced size": "931.012 GB [0x74606db0 Sectors]",
"Physical Sector Size": "512B",
"Raw size": "931.512 GB [0x74706db0 Sectors]",
"SN": "WD-WMC6M0J95THT",
"WWN": "50014EE0AF2FC003",
"Write Cache": "N/A"
},
"Drive /c0/e252/s0 Policies/Settings": {
"Certified": "No",
"Commissioned Spare": "No",
"Connected Port Number": "7(path0) ",
"Cryptographic Erase Capable": "No",
"Drive position": "DriveGroup:0, Span:0, Row:0",
"Emergency Spare": "No",
"Enclosure position": "1",
"FDE Type": "None",
"Last Predictive Failure Event Sequence Number": 0,
"Locked": "No",
"Multipath": "No",
"Needs EKM Attention": "No",
"PI Eligible": "No",
"Port Information": [
{
"Linkspeed": "6.0Gb/s",
"Port": 0,
"SAS address": "0x4433221107000000",
"Status": "Active"
}
],
"SED Capable": "No",
"SED Enabled": "No",
"Sanitize Support": "Not supported",
"Secured": "No",
"Sequence Number": 2,
"Successful diagnostics completion on": "N/A",
"Wide Port Capable": "No"
},
"Drive /c0/e252/s0 State": {
"BBM Error Count": 0,
"Drive Temperature": " 32C (89.60 F)",
"Media Error Count": 0,
"Other Error Count": 0,
"Predictive Failure Count": 0,
"S.M.A.R.T alert flagged by drive": "No",
"Shield Counter": 0
},
"Inquiry Data": "7a 42 ff 3f 37 c8 10 00 00 00 00 00 3f 00 00 00 00 00 00 00 20 20 20 20 57 20 2d 44 4d 57 36 43 30 4d 39 4a 54 35 54 48 00 00 00 00 00 00 52 52 37 30 20 20 20 20 44 57 20 43 44 57 30 31 35 30 42 46 5a 59 30 2d 59 31 42 43 32 42 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 10 80 00 40 00 2f 01 40 00 00 00 00 07 00 ff 3f 10 00 3f 00 10 fc fb 00 00 5d ff ff ff 0f 00 00 07 00 "
}
}
}
]
}
各情報について、なぜ変動する値がキーになっているのか、微妙に違うキーに値を入れるのやめろ、と言いたくなります。例えば、ディスクの温度とシリアルを取りたい場合のデータの位置は以下になります。
json.Controllers[0]["Response Data"]["Drive /c0/e252/s0 - Detailed Information"]["Drive /c0/e252/s0 State"]["Drive Temperature"] = " 32C (89.60 F)";
json.Controllers[0]["Response Data"]["Drive /c0/e252/s0 - Detailed Information"]["Drive /c0/e252/s0 Device attributes"].SN = "WD-WMC6M0J95THT";
なぜ以下のようにしなかったのか…
json.Controllers[0]["Response Data"]["PhysDrive"][0]["Path"]= "/c0/e252/s0";
json.Controllers[0]["Response Data"]["PhysDrive"][0]["SN"] = "WD-WMC6M0J95THT";
json.Controllers[0]["Response Data"]["PhysDrive"][0]["Detailed Information"]["State"]["Drive Temperature Celsius"] = 32
もともとディスクのシリアルと型番を元にクエリを投げて温度を取ろうと思い、上記のような構造であればJSONだけでクエリが完結したのですが、このような構造のためLLDのキーに色々仕込む必要がありました。
内容としてはカスタムスクリプトに正規表現でパスを取り出すものを仕組み、LLDの名前として取得して、LLDのアイテムプロトタイプで正規表現で取り出す、という内容です。
LLDのカスタムスクリプト
var array = JSON.parse(value)
var drives = []
for (var a in array) {
for (var ar in array[a]){
if ( ar.indexOf("Detailed Information") != -1){
prefix=ar.replace(/(Drive\s\/[\w\/]+)\s.*/,"$1");
path=ar.replace(/Drive\s(\/[\w\/]+)\s.*/,"$1");
detail=prefix+" Device attributes";
drive=path+":"+array[a][ar][detail]["Model Number"].trim()+":"+array[a][ar][detail].SN
drives.push(drive)
}
}
}
var len = drives.length;
var x = 0
output = "{ \"data\" :["
for (; x < len - 1; x++){
output += "{\"Name\": \"" + drives[x] + "\"},"
}
output += "{\"Name\": \"" + drives[x] + "\"}"
output += "]}"
return output
上記のカスタムスクリプトでこのような名前が取れるので、これをLLDで見つかったディスクとして認識させます。
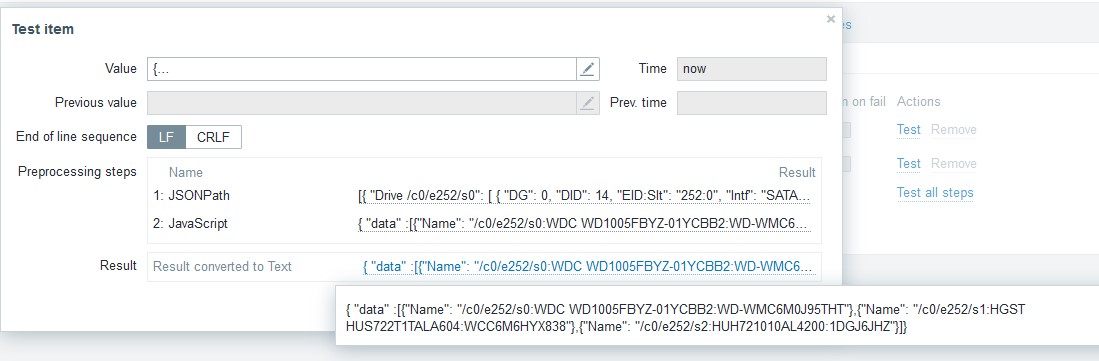
そして、LLDのアイテムプロトタイプにて、JSONpathでデータを取得する際に
.iregsub("\[\"([0-9a-z\/]+):.*\"\]", \1)}で一番最初のスロットナンバーの情報を切り出してJSONのキーに埋め込んでいます。$.Controllers..["Response Data"]..["Drive {{#MR_PD_NAME}.iregsub("\[\"([0-9a-z\/]+):.*\"\]", \1)} State"]["Drive Temperature"]
イケてねえ…。まあイケてないものをイケてない方法でどうにかしようとしているので汚くなるのは必然ですが…。
まとめ
Zabbixは仕事でもプライベートでも使うことが多く、いろいろな意味で一番柔軟性が高い監視方法だと感じています。特定のログを検知しても水曜日の6-7時だけは検知を除外する、というような要求でも、Zabbixであればそれなりに複雑なトリガーの条件式で対応できますが、他の監視方法だとかなりキツイ、もしくはそんな方法はない、という事なりがちで、良くも悪くも使い込めば使い込むほど他のものが使えなくなります。
Zabbixは以前の仕事でそれなりに使っていたつもりだったのですが、今回やった内容は全く知らず、「え、そんなことできたの…」という発見もかなりありました。Zabbixはパズルですが、どうにかする方法はあるのでみんなで沼に沈みましょう。
おそらく、今回の方法ももう少しスマートな方法がある気がしますが、とりあえず動いたので参考にはなるかと思います。
追記:
その後実際に役に立ってしまったので動作については問題ないと思います。また、storcliのデータについてはデフォルトではヒストリを取らない設定に変更し、ディスクのステータスの追加のデータを取るように変更しました。何が起きてるかを知りたいときには手動でヒストリの取得を有効にしてください。
また、コントローラーが複数存在する場合に、2台目以降のコントローラーのデータが上手くパースできていない問題も修正しました。
[ コメントを書く ] ( 777 回表示 ) | このエントリーのURL |

普段便利に使っているESXiの環境ですが、ESXi7x以降になるとvmkAPIのバージョンが上がり、ネイティブドライバが配布されていないとドライバの認識ができないため、古いマイナーなハードウェアがだいぶ認識できなくなります。こちらの環境では未だにストレージがInfinibandとSRPに依存しているので6.7から進めずにいます。

そんな中、普段動いているストレージのIB接続がESXiからみてesxtopでFCMD/sが跳ね上がるときがあり、なんかストレージが調子が悪い、ということが稀に起きるようになってきました。問題が起きるとストレージ自体の再起動をしてもだめな時があり、VMホストを再起動しても解消しないことがありました。いろいろな検証の結果、どうやらVMホストに刺さっているHCAは問題ないようで、ストレージホストに刺さっているHCAがなにか悪そうな感じでした。
このIB HCAも相当長く使っているので、そろそろ交換してみようと思い、手元にCX2の在庫があるもののebayを見てみたら、FDRなHCAが9ドルで売っていたので買ってしまいました。もうIBは買わないと思っていたのですが…。
ハードウェアについて

対象のHCAはEC33という型番で売られており、Connect-IBのDPモデルのようです。ちなみにCX2とブラケットの互換があったため、DDRなCX2からブラケットをはいで使いまわしました。

燦然と輝くFRU PN / NAの文字。謎が多いです。
Connect-X4などはEtherとしても動かせるためまだ需要があるのですが、Connect-IBは完全にIB専用のため、かなり不人気です。9ドルでもいらないというのが全てですが、こちらの環境だと逆にスイッチがEtherを使えないので都合が良いです。
IBについて
IBは基本は広大なL2で使うという単純な作りがゆえ、QDRな32ポート40Gスイッチ(Voltaire Grid Director)であってもポートをたくさん使っても消費電力が70-100W程度と非常に低く、ストレージインターコネクトとして使うにはとても優秀です。
ただ、IBにはL3ルーティングやVLANなどがない(パーティションを分けるためのP keyがあるといえばあるものの…)うえ、SubnetManagerなど独特な作法があり使いづらいし、ネットワーク的にみんなほしいのは結局Etherだよね、となり、EtherでRoCEなどを使うのが今どきのRDMAですが、自宅環境で使おうとすると新しくスイッチとNICを買わないといけない、スイッチを買っても40GだとIBからそこまで変わらない、40Gスイッチで多ポートのものになると消費電力がかなり上がる、などの理由があり、用途次第では未だにIBにはメリットがあります。
FCがそこそこまともに動けばよいのですが、8G-FCでLinuxターゲットを作ったときにはあまりパフォーマンスが出なかったので、結局全て売ってしまいました。その時はLIO+targetcliで検証しましたが、32G-FCとCSCTならもしかしたら改善しているのかもしれません。しかし、FC HBAをイニシエーターではなくターゲットとして動かすには多少の手間があり、かつまだそこまで32G-FCが出回っていないので現在どの程度出るのかは不明です。ただ、RDMAの高速性、低負荷性を見てしまうと微妙な気がします。
SCSTでSRPターゲットが動くのか2022
現在動いているストレージはDebian9までは上げましたが、それからは塩漬けになっています。現在のDebian11はカーネルが5.10となり、カーネルモジュールとしてib_srptを読み込むSCSTはカーネルとの兼ね合いがありそうで無事に使えるのか、Connect-IBはドライバとしてmlx5をつかむのでこれもいけるのか、という疑問がありました。LinuxはINBOXでib_sprtドライバを持っているのですが、LIO+targetcliだとずっと使っているとSRPがなにかのタイミングで刺さるということが多々あり、パフォーマンスもSCSTのほうがかなり良かったので過去の経験からSCSTを使っています。LIOももしかしたら良くなっているのかもしれませんが、過去から現在の実績があるのでSCSTにこだわります。
様々な検証をした結果、結論から言いますと無事に動いています。以下にSCSTのビルド方法などを書きます。
SCSTのビルド
昔は小細工が色々必要でしたが、今は素直にビルドできるようになっています。まずはgit,make,gcc,linux-headersを入れます。
root@debian:~# apt install git make gcc linux-headers-amd64
次に、gitからソースをダウンロードし、makeします。make allでもいいのですが、FCターゲットなど通常使わないものも含まれているため、一つ一つ指定して作ったほうが早く終わります。今回はSCSTに必要なパッケージ、srpt、iscsiモジュールをビルドします。ここで注意が必要なのは、順番的にscst_installを先に持ってこないと他のビルドがコケます
root@debian:~# git clone https://github.com/SCST-project/scst.git
root@debian:~# cd scst/
root@debian:~/scst# make scst_install scstadm_install iscsi_install srpt_install
ビルドが終わったら、depmodで新しく追加されたモジュールを反映します。
root@debian:~/scst# depmod -a
これで、SCSTの前準備が完了しました。正しくモジュールが入ったか、modinfoで確認します。import_nsがSCSTになっていれば問題なくビルドできています。
root@debian:~# modinfo ib_srpt
filename: /lib/modules/5.10.0-10-amd64/extra/ib_srpt.ko
import_ns: SCST
license: Dual BSD/GPL
description: SCSI RDMA Protocol target driver v3.7.0-pre#in-tree (11 January 2022)
author: Vu Pham and Bart Van Assche
depends: scst,ib_core,rdma_cm,ib_cm
retpoline: Y
name: ib_srpt
vermagic: 5.10.0-10-amd64 SMP mod_unload modversions
sig_id: PKCS#7
signer: SCST Kernel Modules
設定ファイルの作成
昔はscstadminで色々やっていましたが、設定ファイルをある程度作って読み込ませたほうが楽なので以下にサンプルを置きます。SCSTのIBのGIDは/sys/class/infiniband/mlx5_0/ports/1/gids/0などにあるので、こちらをcatなどで開きます。
root@debian:~# cat /sys/class/infiniband/*/ports/*/gids/0
fe80:0000:0000:0000:5849:560e:5c50:0401
fe80:0000:0000:0000:5849:560e:5c50:0409
以下のサンプルはFCでいうところのLUNマスキングをしていない、すべての接続を受け入れてマウントを許可する設定になっています。場合によってはマスキングをしないと意図しないマウントが発生してファイルシステムが壊れるので注意してください。今回はVMFSとESXiからの利用のみを想定しています。TARGET_DRIVER copy_managerは無くてもscstadminが勝手に増やすものなので正直なんだかよくわかりませんが、書いておかないとターゲットの更新をするときなどに--forceをつけて読み直したときに色々終わるので必要なものになります。
cat /etc/scst.conf
HANDLER vdisk_fileio {
DEVICE ram0 {
filename /ramdisk/ram.img
}
}
TARGET_DRIVER copy_manager {
TARGET copy_manager_tgt
}
TARGET_DRIVER ib_srpt {
TARGET fe80:0000:0000:0000:5849:560e:5c50:0401{
enabled 1
rel_tgt_id 1
LUN 0 ram0
}
TARGET fe80:0000:0000:0000:5849:560e:5c50:0409{
enabled 1
rel_tgt_id 2
LUN 0 ram0
}
}
#TARGET_DRIVER iscsi {
#
# enabled 1
#
# TARGET iqn.2022-11.dev-debian-04.sn.1234 {
# QueuedCommands 128
# LUN 0 ram0
# enabled 1
#
# }
#
#}
一度これでSCSTを起動します。systemctl start scst.serviceだとなぜかscst_vdiskが読み込まれないので、手で読み込みます
root@debian:~# for a in scst scst_vdisk ib_srpt ; do modprobe $a ; done
その後、scst_adminで設定を直接読み込んで起動します。
root@debian:~# scstadmin -config /etc/scst.conf
これでESXiにOFEDが入っていればそのうちディスクが見えるはずです。
ESXiからマウントして確認する
LUNマスキングをしていないため、SRPが有効になったESXiがいるIBファブリックにつなぐと定期的にクエリが飛んでいるので勝手にターゲットを認識して未使用ディスクとしてESXiにマウントされます。非公式ながらSRPを使えるESXiは6.7U3が最終です。予め必要なセットアップをしたESXiから見てみます。スペックは以下です。
ターゲット
Dell T5810
CPU Xeon E5-1620 v3
RAM 8*4GB @ 2133MHz (32GB)
HCA: Connect-IB@PCIE 3.0 x16接続 (デュアルポート接続)
RAMDISK 25GB
VMホスト
Supermicro X10SRL-F
CPU Xeon E5-2697 v4
RAM: 8*32GB@2133MHz (256GB)
OFED:MLNX-OFED-ESX-1.8.2.5-10EM-600.0.0.2494585
HCA: ConnectX-3 (not VPI/Pro) @PCIE 3.0 x8接続 ( マルチパス)
その結果が以下です。
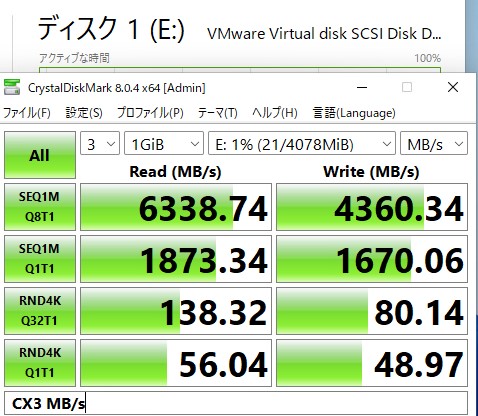
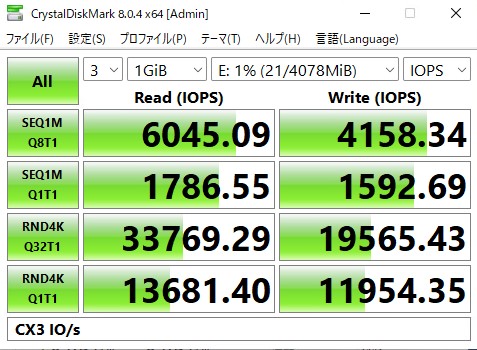
速い(確信)
QDRなスイッチに接続されているため、理論値的には80Gbps*0.8 in MB/sで8GB/sが最大ですが、CX3がPCIE 3.0のx8でリンクしているため、PCIEの最大が64Gbpsとなり、それの0.8倍となると6.4GB/sが理論値になるのでかなり近いところまで出ています。もう少しIOPSが出てもいい気がしたので、以下のシステムでも検証してみました。
VMホスト
Supermicro C9Z390-PGW
CPU Core i5 9600K @ AllCore4.8GHz
RAM: 4*32GB@2666 MHz (128GB)
OFED:MLNX-OFED-ESX-1.8.2.5-10EM-600.0.0.2494585
HCA: ConnectX-2 @PCIE 2.0 x8接続 (マルチパス)
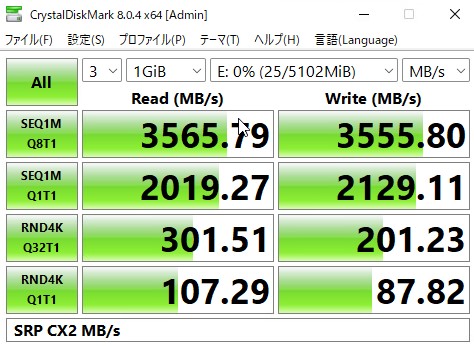
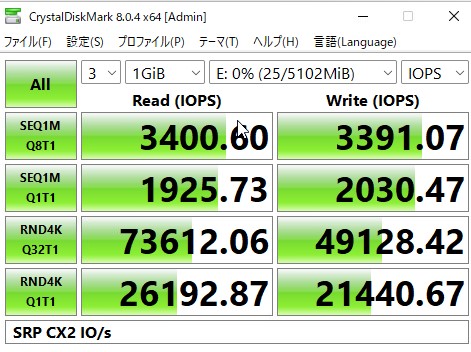
その結果が以下です。
速い(確信)
刺さっているのがConnectX-2というPCIE2.0の化石なので帯域は頭打ちになっていますが、CPUのクロックが高いのでIOPSがかなり出ています。
Connect-IBをESXiで使いたい人生だった
Connect-IBはmlx5ドライバを使うため、6.7などでOFEDを入れても認識しません。しかし、デバイスにパススルーをかけてLinux VMでSRPを受け付け、そのディスクをもう一度内部のvmkスイッチとiSCSIで接続することによりストレージプロクシとして動かせば見えるのでは??というスケベ心が起きてしまったので試してみました。これが動けばESXiの上で動くドライバ依存がなくなるので、ESXi8も使えるようになります。センスのない絵にすると以下のような感じになります。SRPドライブはVMによりiSCSIに変換され、ESXiの内部ループバック接続によってDatastoreとしてマウントされます。
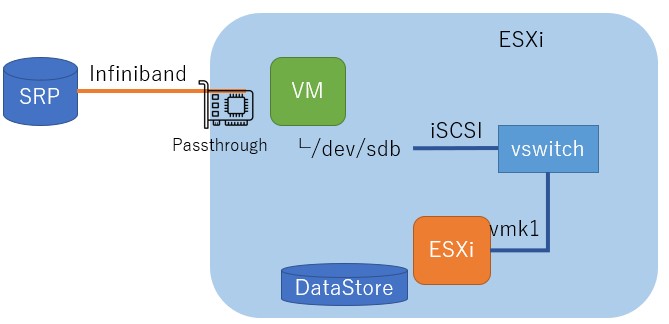
結論から言うと、動くには動いたのですが、何故かPCIパススルーをかけたLinuxVM上からのSRPドライブに対してそもそもののパフォーマンスが出ないため、あまり意味がありませんでした。ddなどで負荷をかけるとSRPドライブそのものに対するアクセスが物理環境と比べて負荷が高いように見えました。
とはいえ、ストレージプロクシ経由のESXi8.0環境でも1.4GB/sと10Gbps以上は出ていたので、何かしらのチューニングにより改善する可能性はあります。ただ、物理環境では問題なくてもパススルーVM環境だとib_read_bwが通らなかったりなど、なにか一癖ありそうな雰囲気がありました。起動オプションになにか必要なのかもしれません。
また、SRPドライブをiSCSIでエクスポートし直してファイルシステムがこわれないのか、という疑問については問題ありませんでした。ただし、DEVICEの名前を元の名前と揃えておかないとESXiからマウントしたときのeuiが変わってしまうため、これを合わせる必要はありました。
root@debian:~# cat /etc/scst.conf
HANDLER vdisk_blockio{
DEVICE ram0{ #←ここ
filename /dev/sdb
}
}
TARGET_DRIVER iscsi {
enabled 1
TARGET iqn.2022-11.dev-debian-iscsiloop.sn.1234 {
allowed_portal 10.11.1.1
QueuedCommands 128
LUN 0 ram0
enabled 1
}
}
まとめ
Connect-IBについてはIBで使う限りはなかなか良いのですが、ESXiについてはやはり6.7+CX3止まりということになりそうです。IBは損切りしたいのですが、いかんせん速いので結局これを使い続けることになりそうです。今どきのシステムだとハイパーコンバージドな構成でローカルに高速ストレージを積むのが流行りですが、自宅環境だと最低必要台数とハード構成の縛りが結構きつく、多少の冗長化を捨ててもコンピュートノードとストレージノードを分けられたほうがそれぞれに特化した構成が作れるので都合がいいことが多いです。
とはいえ、そろそろNVMeOFとかiSER使いたいので誰か低消費電力な100Gスイッチください…
[ コメントを書く ] ( 909 回表示 ) | このエントリーのURL |
<戻る | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 進む> 最後へ>>